词频统计多需求版
Posted blogli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词频统计多需求版相关的知识,希望对你有一定的参考价值。
下面针对词频统计的不同功能要求给出部分代码和截图,具体代码请访问博客下方提供的链接。
功能1. 小文件输入. 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
package com.lq.homework; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Scanner; import java.util.Map.Entry; import java.util.StringTokenizer; public class CountWord01 { public static void main(String[] args) throws IOException { FileReader file; BufferedReader buffer; Map<String, Integer> hashMap = new HashMap<String, Integer>(); Scanner scan = new Scanner(System.in); String input = scan.next(); // 在命令行创建并且编辑文件后,在运行时输入所编辑的文件路径 file = new FileReader(input); buffer = new BufferedReader(file); String value = null; while ((value = buffer.readLine()) != null) { value = value.toLowerCase().replaceAll("[^a-z]|\\\\s+|\\t|\\r]", " "); StringTokenizer token = new StringTokenizer(value); while (token.hasMoreTokens()) { String target = token.nextToken(); if (hashMap.containsKey(target)) { int k = hashMap.get(target).intValue() + 1; hashMap.put(target, new Integer(k)); } else { hashMap.put(target, new Integer(1)); } } } List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(hashMap.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); System.out.println("total " + list.size() + " words"); for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i).getKey() + ":" + list.get(i).getValue()); } } }
编译后,运行时在后面直接加参数,运行时截图如下:

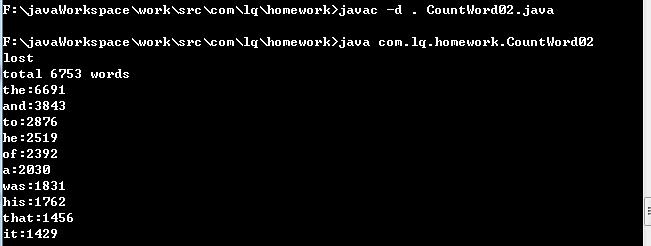
功能2. 支持命令行输入英文作品的文件名,请老五亲自录入。
部分代码:
public static void main(String[] args) throws IOException { FileReader file; BufferedReader buffer; Map<String, Integer> hashMap = new HashMap<String, Integer>(); Scanner scan = new Scanner(System.in); try { String path = "F:\\\\document\\\\"; path += scan.next(); // 输入文件名,按照path+文件名进行拼接,形成文本所在的路径 // 建立文件输入流 file = new FileReader(path + ".txt"); buffer = new BufferedReader(file); String value = null; while ((value = buffer.readLine()) != null) { value = value.toLowerCase().replaceAll("[^a-z]|\\\\s+|\\t|\\r]", " "); StringTokenizer token = new StringTokenizer(value); while (token.hasMoreTokens()) { String target = token.nextToken(); if (hashMap.containsKey(target)) { int k = hashMap.get(target).intValue() + 1; hashMap.put(target, new Integer(k)); } else { hashMap.put(target, new Integer(1)); } } } List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(hashMap.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); System.out.println("total " + hashMap.size() + " words"); for (int num = 0; num < 10; num++) { System.out.println(list.get(num).getKey() + ":" + list.get(num).getValue()); } } catch (FileNotFoundException e) { e.printStackTrace(); } }
编译后,后运行,然后等待用户输入文件名,运行时截图如下:
ps:lost是程序运行后从命令行输入的文件名。
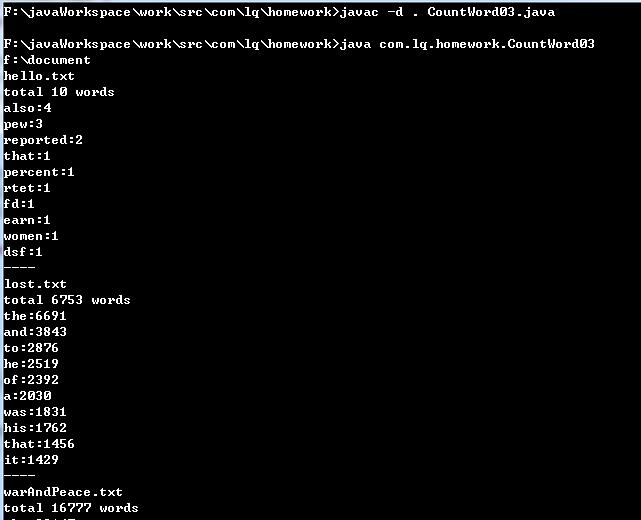
功能3. 支持命令行输入存储有英文作品文件的目录名,批量统计。
public static void main(String[] args) throws IOException { FileReader file; BufferedReader buffer; Map<String, Integer> hashMap = new HashMap<String, Integer>(); Scanner scan = new Scanner(System.in); try { // 输入文件所在的目录名,对目录下的文本进行词频统计 String path = scan.next(); File f = new File(path); File s[] = f.listFiles(); for (int i = 0; i < s.length; i++) { // 确保文件是以.txt结尾 String fileName = s[i].getName(); if (fileName.endsWith(".txt")) { System.out.println(fileName); // 建立文件输入流 file = new FileReader(s[i]); buffer = new BufferedReader(file); String value = null; while ((value = buffer.readLine()) != null) { value = value.toLowerCase().replaceAll("[^a-zA-Z]|\\\\s+|\\t|\\r]", " "); StringTokenizer token = new StringTokenizer(value); while (token.hasMoreTokens()) { String target = token.nextToken(); if (hashMap.containsKey(target)) { int k = hashMap.get(target).intValue() + 1; hashMap.put(target, new Integer(k)); } else { hashMap.put(target, new Integer(1)); } } } List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>( hashMap.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); System.out.println("total " + hashMap.size() + " words"); for (int num = 0; num < 10; num++) { System.out.println(list.get(num).getKey() + ":" + list.get(num).getValue()); } System.out.println("----"); hashMap.clear();// 清理前一个map的内容 } } } catch (FileNotFoundException e) { e.printStackTrace(); } }
编译后,然后运行,然后等待用户输入目录名,然后目录下的所有.txt文件将会依次展示。运行时截图如下:
ps:f:\\document是程序运行后从命令行输入的文件的路径名。
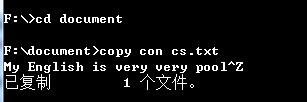
功能4. 从控制台读入英文单篇作品,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。
public static void main(String[] args) throws IOException { if (args.length == 0) { Scanner in = new Scanner(System.in); FileWriter out = new FileWriter("F:\\\\document\\\\new.txt"); while (in.hasNext()) { out.write(in.nextLine()+"\\r\\n"); } out.close(); in.close(); } FileReader file; BufferedReader buffer; Map<String, Integer> hashMap = new HashMap<String, Integer>(); try { // 建立文件输入流 file = new FileReader("F:\\\\document\\\\new.txt"); buffer = new BufferedReader(file); String value = null; while ((value = buffer.readLine()) != null) { value = value.toLowerCase().replaceAll("[^a-z]|\\\\s+|\\t|\\r]", " "); StringTokenizer token = new StringTokenizer(value); //分词 while (token.hasMoreTokens()) { String target = token.nextToken(); if (hashMap.containsKey(target)) { int k = hashMap.get(target).intValue() + 1; hashMap.put(target, new Integer(k)); } else { hashMap.put(target, new Integer(1)); } } } List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(hashMap.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override //对map中的value按照数值大小进行逆排序 public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); System.out.println("total " + list.size() + " words"); for (int i = 0; i < 10; i++) { System.out.println(list.get(i).getKey() + ":" + list.get(i).getValue()); } } catch (FileNotFoundException e) { e.printStackTrace(); } }

总结:对于这次的词频统计,我的感受是主体程序未变。只是在命令行编译,运行时输入的要求不同,与之相应的是程序中的少量修改。
词频统计代码发布地址: https://coding.net/u/muziliquan/p/classwork02/git/tree/master/homework
ssh: git://git.coding.net/muziliquan/classwork02.git
以上是关于词频统计多需求版的主要内容,如果未能解决你的问题,请参考以下文章