Laplacian matrix(转)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Laplacian matrix(转)相关的知识,希望对你有一定的参考价值。
转自:https://en.wikipedia.org/wiki/Laplacian_matrix#Deformed_Laplacian
Laplacian matrix
In the mathematical field of graph theory, the Laplacian matrix, sometimes called admittance matrix, Kirchhoff matrix or discrete Laplacian, is a matrix representation of a graph. Together with Kirchhoff‘s theorem, it can be used to calculate the number of spanning trees for a given graph. The Laplacian matrix can be used to find many other properties of the graph. Cheeger‘s inequality from Riemannian geometry has a discrete analogue involving the Laplacian matrix; this is perhaps the most important theorem in spectral graph theory and one of the most useful facts in algorithmic applications. It approximates the sparsest cut of a graph through the second eigenvalue of its Laplacian.
Contents
Definition
Given a simple graph G with n vertices, its Laplacian matrix 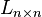 is defined as:[1]
is defined as:[1]
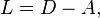
where D is the degree matrix and A is the adjacency matrix of the graph. In the case of directed graphs, either the indegree or outdegree might be used, depending on the application.
The elements of 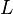 are given by
are given by
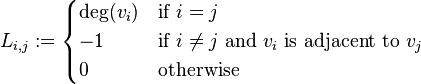
where deg(vi) is degree of the vertex i.
The symmetric normalized Laplacian matrix is defined as:[1]
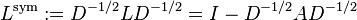 ,
,
The elements of 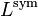 are given by
are given by
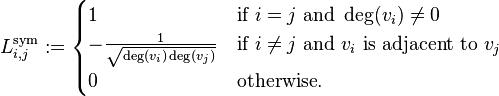
The random-walk normalized Laplacian matrix is defined as:
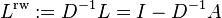
The elements of 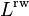 are given by
are given by
Example
Here is a simple example of a labeled graph and its Laplacian matrix.
| Labeled graph | Degree matrix | Adjacency matrix | Laplacian matrix |
|---|---|---|---|
 |
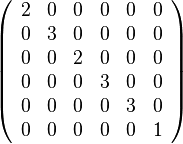 |
 |
 |
Properties
For an (undirected) graph G and its Laplacian matrix L with eigenvalues 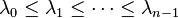 :
:
- L is symmetric..
- L is positive-semidefinite (that is
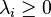 for all i). This is verified in the incidence matrix section (below). This can also be seen from the fact that the Laplacian is symmetric and diagonally dominant.
for all i). This is verified in the incidence matrix section (below). This can also be seen from the fact that the Laplacian is symmetric and diagonally dominant. - L is an M-matrix (its off-diagonal entries are nonpositive, yet the real parts of its eigenvalues are nonnegative).
- Every row sum and column sum of L is zero. Indeed, in the sum, the degree of the vertex is summed with a "-1" for each neighbor.
- In consequence,
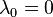 , because the vector
, because the vector 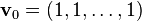 satisfies
satisfies 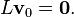
- The number of times 0 appears as an eigenvalue in the Laplacian is the number of connected components in the graph.
- The smallest non-zero eigenvalue of L is called the spectral gap.
- The second smallest eigenvalue of L is the algebraic connectivity (or Fiedler value) of G.
- The Laplacian is an operator on the n-dimensional vector space of functions f : V →
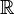 , where V is the vertex set of G, and n = |V|.
, where V is the vertex set of G, and n = |V|. - When G is k-regular, the normalized Laplacian is:
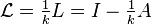 , where A is the adjacency matrix and I is an identity matrix.
, where A is the adjacency matrix and I is an identity matrix. - For a graph with multiple connected components, L is a block diagonal matrix, where each block is the respective Laplacian matrix for each component, possibly after reordering the vertices (i.e. L is permutation-similar to a block diagonal matrix).
- Laplacian matrix is singular.
Incidence matrix
Define an 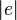 x
x 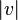 oriented incidence matrix M with element Mev for edge e (connecting vertex i and j, with i > j) and vertex v given by
oriented incidence matrix M with element Mev for edge e (connecting vertex i and j, with i > j) and vertex v given by
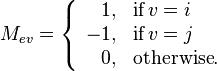
Then the Laplacian matrix L satisfies
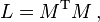
where 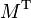 is the matrix transpose of M.
is the matrix transpose of M.
Now consider an eigendecomposition of , with unit-norm eigenvectors 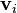 and corresponding eigenvalues
and corresponding eigenvalues 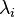 :
:
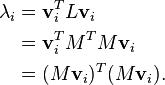
Because can be written as the inner product of the vector 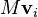 with itself, this shows that and so the eigenvalues of are all non-negative.
with itself, this shows that and so the eigenvalues of are all non-negative.
Deformed Laplacian
The deformed Laplacian is commonly defined as
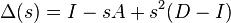
where I is the unit matrix, A is the adjacency matrix, and D is the degree matrix, and s is a (complex-valued) number. Note that the standard Laplacian is just 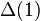 .[2]
.[2]
Symmetric normalized Laplacian
The (symmetric) normalized Laplacian is defined as
where L is the (unnormalized) Laplacian, A is the adjacency matrix and D is the degree matrix. Since the degree matrix D is diagonal and positive, its reciprocal square root 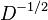 is just the diagonal matrix whose diagonal entries are the reciprocals of the positive square roots of the diagonal entries of D. The symmetric normalized Laplacian is a symmetric matrix.
is just the diagonal matrix whose diagonal entries are the reciprocals of the positive square roots of the diagonal entries of D. The symmetric normalized Laplacian is a symmetric matrix.
One has: 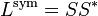 , where S is the matrix whose rows are indexed by the vertices and whose columns are indexed by the edges of G such that each column corresponding to an edge e = {u, v} has an entry
, where S is the matrix whose rows are indexed by the vertices and whose columns are indexed by the edges of G such that each column corresponding to an edge e = {u, v} has an entry 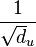 in the row corresponding to u, an entry
in the row corresponding to u, an entry 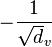 in the row corresponding to v, and has 0 entries elsewhere. (Note:
in the row corresponding to v, and has 0 entries elsewhere. (Note: 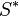 denotes the transpose of S).
denotes the transpose of S).
All eigenvalues of the normalized Laplacian are real and non-negative. We can see this as follows. Since is symmetric, its eigenvalues are real. They are also non-negative: consider an eigenvector g of with eigenvalue λ and suppose 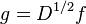 . (We can consider g and f as real functions on the vertices v.) Then:
. (We can consider g and f as real functions on the vertices v.) Then:
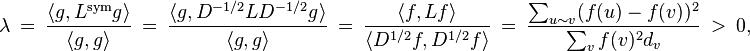
where we use the inner product 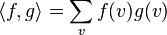 , a sum over all vertices v, and
, a sum over all vertices v, and 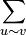 denotes the sum over all unordered pairs of adjacent vertices {u,v}. The quantity
denotes the sum over all unordered pairs of adjacent vertices {u,v}. The quantity 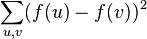 is called the Dirichlet sum of f, whereas the expression
is called the Dirichlet sum of f, whereas the expression 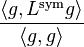 is called the Rayleigh quotient of g.
is called the Rayleigh quotient of g.
Let 1 be the function which assumes the value 1 on each vertex. Then 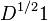 is an eigenfunction of with eigenvalue 0.[3]
is an eigenfunction of with eigenvalue 0.[3]
In fact, the eigenvalues of the normalized symmetric Laplacian satisfy 0 = μ0≤...≤ μn-1≤ 2. These eigenvalues (known as the spectrum of the normalized Laplacian) relate well to other graph invariants for general graphs.[4]
Random walk normalized Laplacian
The random walk normalized Laplacian is defined as
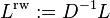
where A is the Adjacency matrix and D is the degree matrix. Since the degree matrix D is diagonal, its inverse 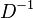 is simply defined as a diagonal matrix, having diagonal entries which are the reciprocals of the corresponding positive diagonal entries of D. For the isolated vertices (those with degree 0), a common choice is to set the corresponding element
is simply defined as a diagonal matrix, having diagonal entries which are the reciprocals of the corresponding positive diagonal entries of D. For the isolated vertices (those with degree 0), a common choice is to set the corresponding element 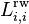 to 0. This convention results in a nice property that the multiplicity of the eigenvalue 0 is equal to the number of connected components in the graph. The matrix elements of are given by
to 0. This convention results in a nice property that the multiplicity of the eigenvalue 0 is equal to the number of connected components in the graph. The matrix elements of are given by
The name of the random-walk normalized Laplacian comes from the fact that this matrix is simply the transition matrix of a random walker on the graph. For example let 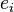 denote the i-th standard basis vector, then
denote the i-th standard basis vector, then 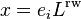 is a probability vector representing the distribution of a random-walker‘s locations after taking a single step from vertex
is a probability vector representing the distribution of a random-walker‘s locations after taking a single step from vertex 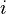 . i.e.
. i.e. 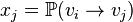 . More generally if the vector
. More generally if the vector 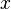 is a probability distribution of the location of a random-walker on the vertices of the graph then
is a probability distribution of the location of a random-walker on the vertices of the graph then 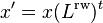 is the probability distribution of the walker after
is the probability distribution of the walker after 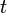 steps.
steps.
One can check that
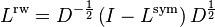 ,
,
i.e., is similar to the normalized Laplacian . For this reason, even if is in general not hermitian, it has real eigenvalues. Indeed, its eigenvalues agree with those of (which is hermitian) up to a reflection about 1/2.
In some of the literature, the matrix 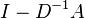 is also referred to as the random-walk Laplacian since its properties approximate those of the standard discrete Laplacian from numerical analysis.
is also referred to as the random-walk Laplacian since its properties approximate those of the standard discrete Laplacian from numerical analysis.
Graphs
As an aside about random walks on graphs, consider a simple undirected graph. Consider the probability that the walker is at the vertex i at time t, given the probability distribution that he was at vertex j at time t-1 (assuming a uniform chance of taking a step along any of the edges attached to a given vertex):
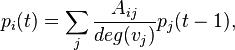
or in matrix-vector notation:
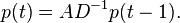
(Equilibrium, which sets in as 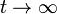 , is defined by
, is defined by 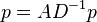 .)
.)
We can rewrite this relation as
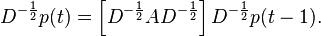
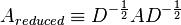 is a symmetric matrix called the reduced adjacency matrix. So, taking steps on this random walk requires taking powers of
is a symmetric matrix called the reduced adjacency matrix. So, taking steps on this random walk requires taking powers of 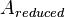 , which is a simple operation because is symmetric.
, which is a simple operation because is symmetric.
Interpretation as the discrete Laplace operator
The Laplacian matrix can be interpreted as a matrix representation of a particular case of the discrete Laplace operator. Such an interpretation allows one, e.g., to generalise the Laplacian matrix to the case of graphs with an infinite number of vertices and edges, leading to a Laplacian matrix of an infinite size.
To expand upon this, we can "describe"[why?] the change of some element 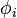 (with some constant k) as[why?]
(with some constant k) as[why?]
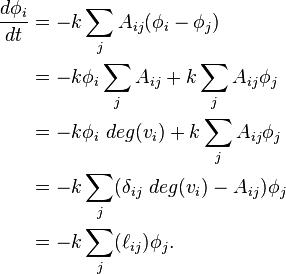
In matrix-vector notation,
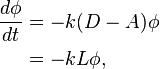
which gives
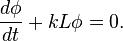
Notice that this equation takes the same form as the heat equation, where the matrix L is replacing the Laplacian operator 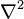 ; hence, the "graph Laplacian".
; hence, the "graph Laplacian".
To find a solution to this differential equation, apply standard techniques for solving a first-order matrix differential equation. That is, write 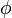 as a linear combination of eigenvectors of L (so that
as a linear combination of eigenvectors of L (so that 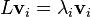 ), with time-dependent
), with time-dependent 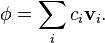
Plugging into the original expression (note that we will use the fact that because L is a symmetric matrix, its unit-norm eigenvectors are orthogonal):
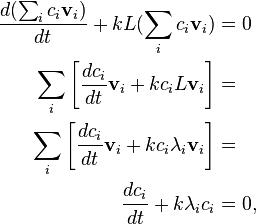
whose solution is
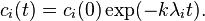
As shown before, the eigenvalues of L are non-negative, showing that the solution to the diffusion equation approaches an equilibrium, because it only exponentially decays or remains constant. This also shows that given and the initial condition 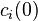 , the solution at any time t can be found.[5]
, the solution at any time t can be found.[5]
To find for each in terms of the overall initial condition 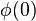 , simply project onto the unit-norm eigenvectors ;
, simply project onto the unit-norm eigenvectors ;
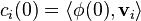 .
.
In the case of undirected graphs, this works because is symmetric, and by the spectral theorem, its eigenvectors are all orthogonal. So the projection onto the eigenvectors of is simply an orthogonal coordinate transformation of the initial condition to a set of coordinates which decay exponentially and independently of each other.
Equilibrium Behavior
To understand 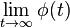 , note that the only terms
, note that the only terms 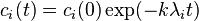 that remain are those where
that remain are those where 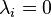 , since
, since
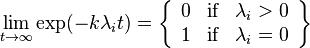
In other words, the equilibrium state of the system is determined completely by the kernel of . Since by definition, 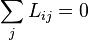 , the vector
, the vector 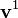 of all ones is in the kernel. Note also that if there are
of all ones is in the kernel. Note also that if there are 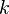 disjoint connected components in the graph, then this vector of all ones can be split into the sum of independent
disjoint connected components in the graph, then this vector of all ones can be split into the sum of independent 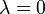 eigenvectors of ones and zeros, where each connected component corresponds to an eigenvector with ones at the elements in the connected component and zeros elsewhere.
eigenvectors of ones and zeros, where each connected component corresponds to an eigenvector with ones at the elements in the connected component and zeros elsewhere.
The consequence of this is that for a given initial condition 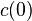 for a graph with
for a graph with 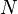 vertices
vertices
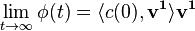
where
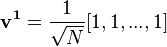
For each element 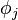 of , i.e. for each vertex
of , i.e. for each vertex 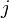 in the graph, it can be rewritten as
in the graph, it can be rewritten as
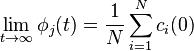 .
.
In other words, at steady state, the value of converges to the same value at each of the vertices of the graph, which is the average of the initial values at all of the vertices. Since this is the solution to the heat diffusion equation, this makes perfect sense intuitively. We expect that neighboring elements in the graph will exchange energy until that energy is spread out evenly throughout all of the elements that are connected to each other.
Example of the Operator on a Grid

This section shows an example of a function diffusing over time through a graph. The graph in this example is constructed on a 2D discrete grid, with points on the grid connected to their eight neighbors. Three initial points are specified to have a positive value, while the rest of the values in the grid are zero. Over time, the exponential decay acts to distribute the values at these points evenly throughout the entire grid.
The complete Matlab source code that was used to generate this animation is provided below. It shows the process of specifying initial conditions, projecting these initial conditions onto the eigenvalues of the Laplacian Matrix, and simulating the exponential decay of these projected initial conditions.
N = 20;%The number of pixels along a dimension of the image
A = zeros(N, N);%The image
Adj = zeros(N*N, N*N);%The adjacency matrix
%Use 8 neighbors, and fill in the adjacency matrix
dx = [-1, 0, 1, -1, 1, -1, 0, 1];
dy = [-1, -1, -1, 0, 0, 1, 1, 1];
for x = 1:N
for y = 1:N
index = (x-1)*N + y;
for ne = 1:length(dx)
newx = x + dx(ne);
newy = y + dy(ne);
if newx > 0 && newx <= N && newy > 0 && newy <= N
index2 = (newx-1)*N + newy;
Adj(index, index2) = 1;
end
end
end
end
%%%BELOW IS THE KEY CODE THAT COMPUTES THE SOLUTION TO THE DIFFERENTIAL
%%%EQUATION
Deg = diag(sum(Adj, 2));%Compute the degree matrix
L = Deg - Adj;%Compute the laplacian matrix in terms of the degree and adjacency matrices
[V, D] = eig(L);%Compute the eigenvalues/vectors of the laplacian matrix
D = diag(D);
%Initial condition (place a few large positive values around and
%make everything else zero)
C0 = zeros(N, N);
C0(2:5, 2:5) = 5;
C0(10:15, 10:15) = 10;
C0(2:5, 8:13) = 7;
C0 = C0(:);
C0V = V‘*C0;%Transform the initial condition into the coordinate system
%of the eigenvectors
for t = 0:0.05:5
%Loop through times and decay each initial component
Phi = C0V.*exp(-D*t);%Exponential decay for each component
Phi = V*Phi;%Transform from eigenvector coordinate system to original coordinate system
Phi = reshape(Phi, N, N);
%Display the results and write to GIF file
imagesc(Phi);
caxis([0, 10]);
title(sprintf(‘Diffusion t = %3f‘, t));
frame = getframe(1);
im = frame2im(frame);
[imind, cm] = rgb2ind(im, 256);
if t == 0
imwrite(imind, cm, ‘out.gif‘, ‘gif‘, ‘Loopcount‘, inf, ‘DelayTime‘, 0.1);
else
imwrite(imind, cm, ‘out.gif‘, ‘gif‘, ‘WriteMode‘, ‘append‘, ‘DelayTime‘, 0.1);
end
end
Approximation to the negative continuous Laplacian
The graph Laplacian matrix can be further viewed as a matrix form of an approximation to the (positive semi-definite) Laplacian operator obtained by the finite difference method.[6] In this interpretation, every graph vertex is treated as a grid point; the local connectivity of the vertex determines the finite difference approximation stencil at this grid point, the grid size is always one for every edge, and there are no constraints on any grid points, which corresponds to the case of the homogeneous Neumann boundary condition, i.e., free boundary.
In Directed Multigraphs
An analogue of the Laplacian matrix can be defined for directed multigraphs.[7] In this case the Laplacian matrix L is defined as
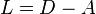
where D is a diagonal matrix with Di,i equal to the outdegree of vertex i and A is a matrix with Ai,j equal to the number of edges from i to j (including loops).
See also
References
- Weisstein, Eric W., "Laplacian Matrix", MathWorld.
- "The Deformed Consensus Protocol", F. Morbidi, Automatica, vol. 49, n. 10, pp. 3049-3055, October 2013.
- Chung, Fan R.K. (1997). Spectral graph theory (Repr. with corr., 2. [pr.] ed.). Providence, RI: American Math. Soc. ISBN 0-8218-0315-8.
- Chung, Fan (1997) [1992]. Spectral Graph Theory. American Mathematical Society. ISBN 0821803158.
- Newman, Mark (2010). Networks: An Introduction. Oxford University Press. ISBN 0199206651.
- Smola, Alexander J.; Kondor, Risi (2003), "Kernels and regularization on graphs", Learning Theory and Kernel Machines: 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT/Kernel 2003, Washington, DC, USA, August 24-27, 2003, Proceedings, Lecture Notes in Computer Science 2777, Springer, pp. 144–158, doi:10.1007/978-3-540-45167-9_12.
- Chaiken, S. and Kleitman, D. (1978). "Matrix Tree Theorems". Journal of Combinatorial Theory, Series A 24 (3): 377–381. doi:10.1016/0097-3165(78)90067-5. ISSN 0097-3165.
- T. Sunada, Discrete geometric analysis, Proceedings of Symposia in Pure Mathematics, (ed. by P. Exner, J. P. Keating, P. Kuchment, T. Sunada, A. Teplyaev), 77 (2008), 51-86.
- B. Bollobaás, Modern Graph Theory, Springer-Verlag (1998, corrected ed. 2013), ISBN 0-387-98488-7, Chapters II.3 (Vector Spaces and Matrices Associated with Graphs), VIII.2 (The Adjacency Matrix and the Laplacian), IX.2 (Electrical Networks and Random Walks).
以上是关于Laplacian matrix(转)的主要内容,如果未能解决你的问题,请参考以下文章