JDBC百万数据插入
Posted 行者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDBC百万数据插入相关的知识,希望对你有一定的参考价值。
使用JDBC连接数据库时,如果插入的数据量大,一条一条地插入数据会变得非常缓慢。此时,我们需要用到预处理。
查阅Java开发文档,我们可以看到:
接口 PreparedStatement
表示预编译的 SQL 语句的对象。
SQL 语句被预编译并存储在 PreparedStatement 对象中。然后可以使用此对象多次高效地执行该语句。
我的理解是,preparedstatement对象相当于sql语句执行前的一个加工站,对sql语句进行具体的数据填充。
大概的使用流程是:
1:使用BufferedString构建一个同时插入N条数据的语句模版;
2:利用模版生成字符串语句,将该语句作为参数构建一个PreparedStatement对象pst,意指用pst对参数语句进行预处理;
3:用pst对象调用方法对参数语句进行预处理:pst.setXX(index,value)等语句把参数语句进行具体的数据填充;
4:执行经过pst处理过后的具体sql语句:pst.execute();
5:关闭pst对象;
画图理解:
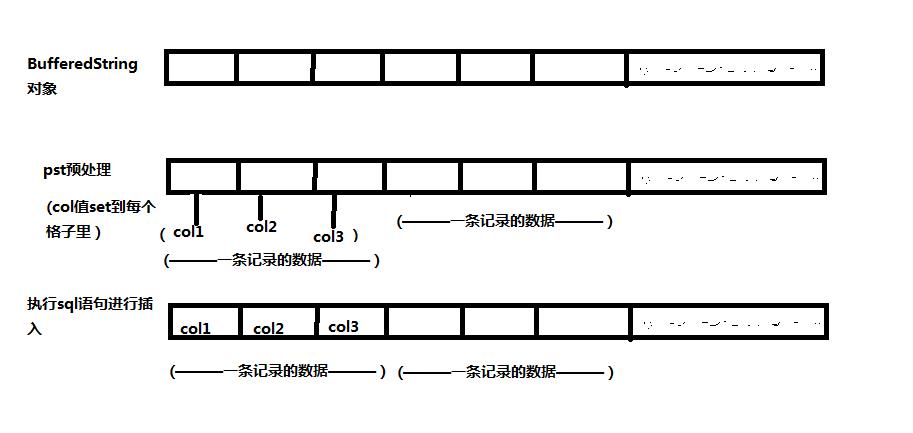
代码示例:
import java.net.*;
import java.io.*;
import java.sql.*;
public class Insert
{
public static void main(String[] args)
{ Connection conn=null;
try{
Class.forName("com.mysql.jdbc.Driver");
conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/inserttest","root","123456");
conn.setAutoCommit(false);
//使用缓冲字符串构造一个同时插入10000条数据的语句模版
StringBuffer sqlBuffer = new StringBuffer(
"insert into test (Col1,Col2,Col3) values");
sqlBuffer.append("(?,?,?)");
for (int j = 2; j <= 10000; j++) {
sqlBuffer.append(",(?,?,?)");
}
sqlBuffer.append(";");
String sql = new String(sqlBuffer);
//SQL语句被预编译并存储在 PreparedStatement 对象中。然后可以使用此对象多次高效地执行该语句。在使用该语句时可以根据下标自行更改具体数据
PreparedStatement pst = conn.prepareStatement(sql);
System.out.println("start!");
Long beginTime = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
System.out.println("No."+(i+1)+"round...");
for (int j = 0; j < 10000; j++) {
//每次插入时,具体的数据通过pst.setXXX(index,value)来赋值
pst.setInt(3 * j + 1, (int) (Math.random() * 11)+1);
pst.setInt(3 * j + 2, (int) (Math.random() * 112)+2);
pst.setInt(3 * j + 3, (int) (Math.random() * 133)+5);
}
//每条sql语句插入10000条数据,执行100条sql
pst.execute();
}
conn.commit();
pst.close();
Long endTime = System.currentTimeMillis();
System.out.println("end!");
System.out.println("total time: " + (double) (endTime - beginTime)/1000 + " s");
System.out.println();
}catch(Exception ex){
}
}
}
以上是关于JDBC百万数据插入的主要内容,如果未能解决你的问题,请参考以下文章