HBase: HBase运维管理
Posted 天戈朱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase: HBase运维管理相关的知识,希望对你有一定的参考价值。
HBase自带的很多工具可用于管理、分析、修复和调试,这些工具一部分的入口是hbase shell 客户端,另一部分是在hbase的Jar包中。
目录:
- hbck
- hfile
- 数据备份与恢复
- Snapshots
- Replication
- Export
- CopyTable
- HTable API
- Offline backup of HDFS data
hbck:
- hbck 工具用于Hbase底层文件系统的检测与修复,包含Master、RegionServer内存中的状态及HDFS上数据的状态之间的一致性、黑洞问题、定位元数据不一致问题等
- 命令: hbase hbck -help 查看参数帮助选项
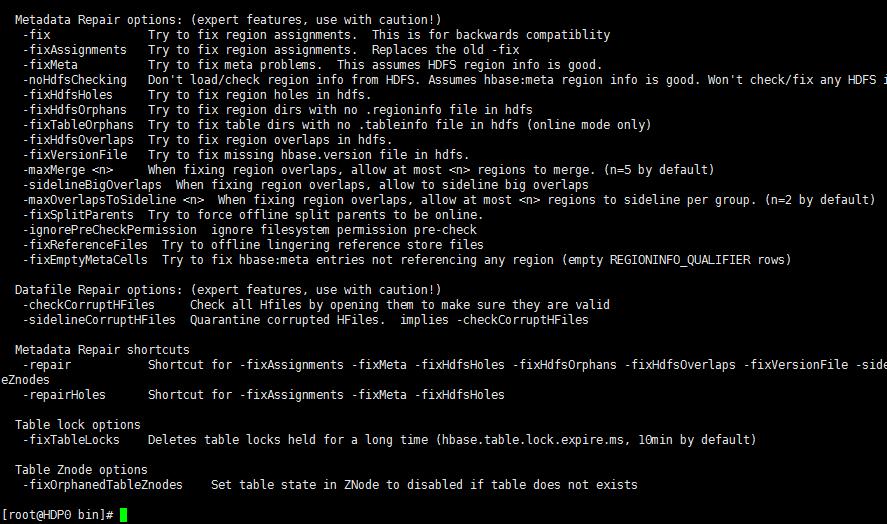
- 命令: hbase hbck -details 显示所有Region的完整报告
- 命令: hbase hbck -metaonly 只检测元数据表的状态,如下图:

- 快捷修复命令:
- 命令:hbase hbck -repair -ignorePreCheckPermission
- 命令:hbase hbck -repairHoles -ignorePreCheckPermission
- 应用示例,参见:HBase(三): Azure HDInsigt HBase表数据导入本地HBase
hfile:
- 查看HFile文件内容工具,命令及参数如下:

- 命令:hbase hfile -p -f /apps/hbase/data/data/default/PerTest/7685e6c39d1394d94e26cf5ddafb7f9f/d/3ef195ca65044eca93cfa147414b56c2
- 效果如下图:

数据备份与恢复:
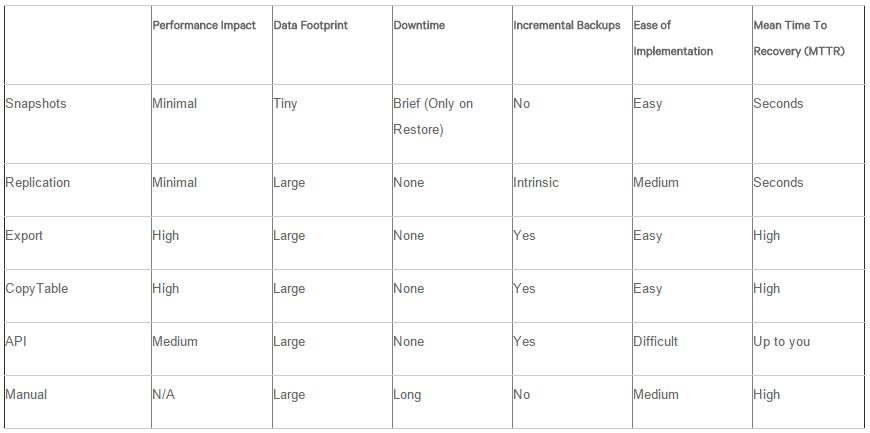
- 常用的备份恢复方法如下图:参考文档: http://blog.cloudera.com/blog/2013/11/approaches-to-backup-and-disaster-recovery-in-hbase/
snapshots:
- HBase快照功能丰富,有很多特征,创建时不需要关闭集群
- 快照在几秒内就可以完成,几乎对整个集群没有任何性能影响。并且,它只占用一个微不足道的空间
- 启用快速需设置 hbase-site.xml 文件的 hbase.snapshot.enabled 为True
- 命令: snapshot \'PerTest\',\'snapPerTest\' 基于表 PerTest 创建名为 snapPerTest 的快照
- 命令: list_snapshots 查看快照列表
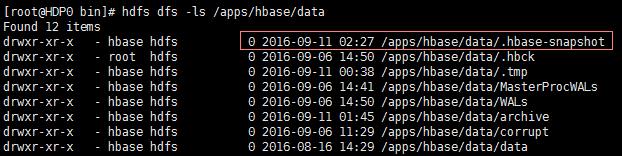
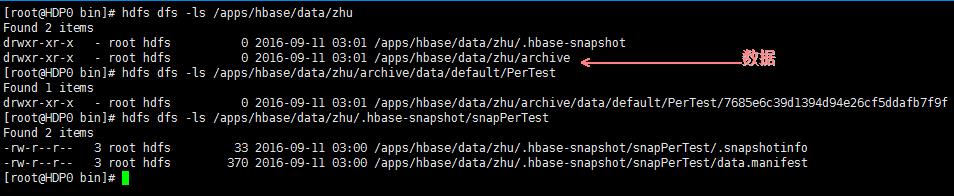
- 创建完快照后,在hbase 目录下会生成 .hbase-snapshots 目录,存放快照信息,如右下角图

- 命令:delete_snapshot \'snapPerTest\' 删除快照
- 恢复快照需要对表进行离线操作。一旦恢复快照,那任何在快照时刻之后做的增加/更新数据都会丢失,命令如下:
disable \'PerTest\' restore_snapshot \'snapPerTest\' enable \'PerTest\' -
命令:clone_snapshot \'snapPerTest\',\'PerTest1\' 根据快照clone新表(注:clone出来的新表不带数据副本)
- ExportSnapshot tool 快照导出工具命令: hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot \'snapPerTest\' -copy-to /apps/hbase/data/zhu
- 注意: 如果能访问到另一集群,则后面的地址可直接改为另一集群hdfs目录
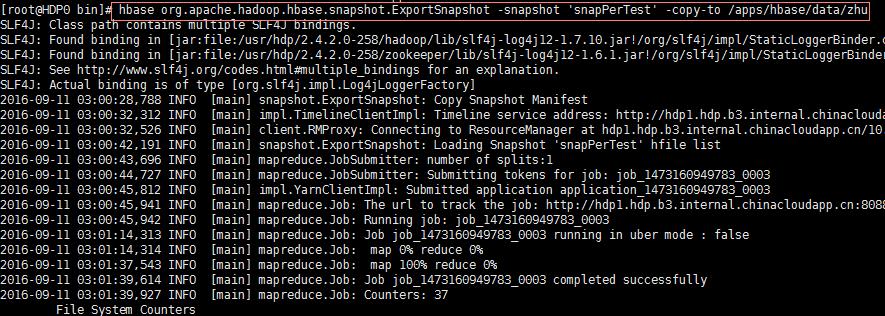
- 导出的文件结构如下
Replication:
- HBase replication是另外一个负载较轻的备份工具。被定义为列簇级别,可以工作在后台并且保证所有的编辑操作在集群复制链之间的同步
- 复制有三种模式:主->从(master->slave),主<->主(master<->master)和循环(cyclic)。这种方法给你灵活的从任意数据中心获取数据并且确保它能获得在其他数据中心的所有副本。在一个数据中心发生灾难性故障的情况下,客户端应用程序可以利用DNS工具,重定向到另外一个备用位置
- 注:对于一个存在的表,你需要通过本文描述的其他方法,手工的拷贝源表到目的表。复制仅仅在你启动它之后才对新的写/编辑操作有效

- 复制是一个强大的,容错的过程。它提供了“最终一致性”,意味着在任何时刻,最近对一个表的编辑可能无法应用到该表的所有副本,但是最终能够确保一致。
Export:
- Export是HBase一个内置的实用功能,它使数据很容易将hbase表内容输出成HDFS的SequenceFiles文件
- 使用map reduce任务,通过一系列HBase API来获取指定表格的每一行数据,并且将数据写入指定的HDFS目录中
- 示例说明:集群A:基于HDInsight创建的windows系统下的hbase 集群, 集群B 基于Azure 虚拟机创建的liunx系统下 hbase集群,将A集群中表StocksInfo表导出至集群B的hdfs目录,遗憾的是两个集群无法通信,只能先导到本地,再手工上传
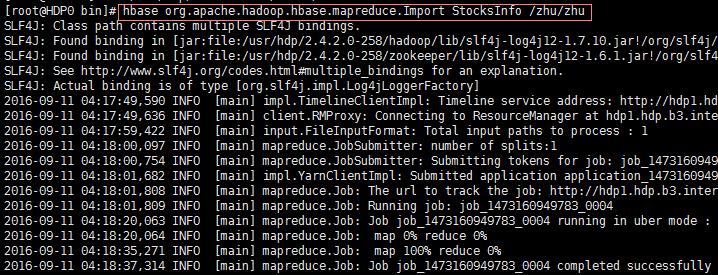
- 命令语法: hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> 示例如下:

- 导出的文件结构如下:

- 命令:hdfs dfs -get /zhu c:/zhu 下载到A集群某节点c盘,手工上传至liunx,如下图

- 使用import命令导入数据至B集群HBase表,如下:(注:输入目录的文件必须是Export命令导出的文件格式)
- 命令语法:hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir> 如下图:
- 查看Hbase 表,如下图则OK

copyTable:
- 和导出功能类似,拷贝表也使用HBase API创建了一个mapreduce任务,以便从源表读取数据。不同的地方是拷贝表的输出是hbase中的另一个表,这个表可以在本地集群,也可以在远程集群
- 它使用独立的“puts”操作来逐行的写入数据到目的表。如果你的表非常大,拷贝表将会导致目标region server上的memstore被填满,会引起flush操作并最终导致合并操作的产生,会有垃圾收集操作等等
- 必须考虑到在HBase上运行mapreduce任务所带来的性能影响。对于大型的数据集,这种方法的效果不太理想
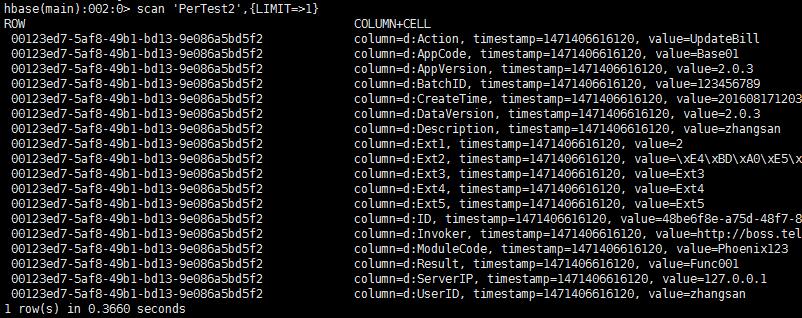
- 命令语法:hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=PerTest2 PerTest (copy名为PerTest的表到集群中的另外一个表PerTest2) 如下图
- 注意:若用到--new.name =xxx,首先这个新表要之前就被定义
Offline backup of HDFS data:
以上是关于HBase: HBase运维管理的主要内容,如果未能解决你的问题,请参考以下文章