Python 正则表达式
Posted Jesson
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 正则表达式相关的知识,希望对你有一定的参考价值。
 正则表达式,又称规则表达式(英语:Regular Expression,在代码中常简写为regex、regexp 或RE),本质而言是一种小型的,高度专业化的编程语言,在(Python)中它内嵌在Python中,并通过RE模块实现。是计算机科学的一个概念。
正则表达式,又称规则表达式(英语:Regular Expression,在代码中常简写为regex、regexp 或RE),本质而言是一种小型的,高度专业化的编程语言,在(Python)中它内嵌在Python中,并通过RE模块实现。是计算机科学的一个概念。
「正则表达式」
一 简介:
正则表达式,是一个特殊的字符序列,又称规则表达式(英语:Regular Expression,在代码中常简写为regex、regexp 或RE),本质而言是一种小型的,高度专业化的编程语言,在(Python)中它内嵌在Python中,并通过RE模块实现;能帮你方便的检查一个字符串是否与某种模式(规则)匹配。
正则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本;正则表达式模式被编译成一系列的字节码,然后用C编写的匹配引擎执行。
Python 自1.5版本起增加了re 模块,re 模块使Python语言拥有全部的正则表达式功能。
使用正则表达式进行匹配的流程:
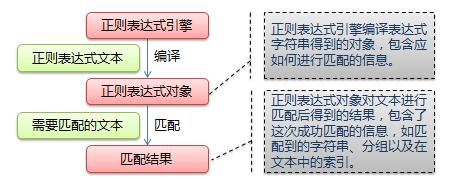
# 导入re正则模块 import re
二 字符匹配:
正则表达式涉及到的字符,分为普通字符和元字符;元字符是具有特殊功能的字符。
1.普通字符: 大多数字符和字母都可以看作是普通字符。
#实例: >>> re.findall(\'jesson\',"dsjkdfjsWRFDd jessonFFEEGsddeed\') # 这里调用了方法re.findall() 该方法的主要功能是,符合条件的结果全部匹配;下文会单独介绍。 >>>[\'jesson\'] #完全匹配 这里基本没有用到正则
2. 元字符:(11个)
. ^ $ * + ? {} [] \\ | ()
(1)元字符“.” 通配符,可以代指所有字符,除了换行符号"\\n",一个点,对应一个字符
#实例1: ret = re.findall(\'w...d\',\'hello world\') print(ret) #实例2: ret = re.findall(\'w...d\',\'hello wor\\nd\') # 不能匹配“\\n” print(ret) # 输出结果为空[],说明"."匹配不到"\\n"
(2)元字符“^” 从整个字符串开头的地方匹配
#实例: ret = re.findall(\'^h...o\',\'hello world\') print(ret) #输出结果:[\'hello\']
(3)元字符“$” 从整个字符串的结尾开始匹配。 可以理解成:从后往前匹配
#实例1: ret = re.findall(\'h...o$\',\'hello world awdx\') print(ret) # 输出结果为空 从整个字符的结尾,不是hello的结尾 #实例2: ret = re.findall(\'a..x$\',\'hello world awdx\') print(ret) #输出结果:[\'awdx\'] 匹配成功
(4)元字符“*” 重复匹配 (表达式中的*表示重复*号前边字符 个数从0到正无穷)
#实例1:想匹配的 以a开头,以li 结尾的字符 #普通写法: ret = re.findall(\'a........li\',\'hello world alex88888li\') print(ret) # 输出结果:[\'alex88888li\'] #采用“*”来写: ret = re.findall(\'a.*li\',\'hello world alex88888li\') print(ret) # 输出结果:[\'alex88888li\'] #实例2: ret = re.findall(\'ba*\',\'sjfjslafjbaaaaaaaaaaaa\') print(ret) # 输出结果:[\'baaaaaaaaaaaa\']
ret = re.findall(\'f*\',\'hellof\')
print(ret) # 输出结果:[\'\', \'\', \'\', \'\', \'\', \'f\', \'\']
ret = re.findall(\'f*\',\'hello\')
print(ret) # 输出结果:[\'\', \'\', \'\', \'\', \'\', \'\']
# 表示取*前边的f,如果有f,可以匹配出,但是,注意没有f的情况下,也会匹配,结果为none值
(5)元字符"+" 表示匹配“+”前边的字符 个数从1到正无穷都能匹配
#实例1: ret = re.findall(\'ab+\',\'dsljfsfjslfaaa\') print(ret) # 输出结果为空 [] 说明没有找到字符b ret = re.findall(\'ab+\',\'dsljfsfjslfaaabbbbbbbbbbb\') print(ret) # 输出结果:[\'abbbbbbbbbbb\'] #实例2: ret = re.findall(\'a+b\',\'adadfwdbaaaaaablkls;flsabb\') print(ret) # 输出结果:[\'aaaaaab\', \'ab\'] ret = re.findall(\'f+\',\'hellof\') print(ret) # 输出结果:[\'f\'] ret = re.findall(\'f+\',\'fhello\') print(ret) # 输出结果:[\'f\'] ret = re.findall(\'f+\',\'hello\') print(ret) # 输出结果:[] # 上述实例说明:取+前边的f 个数,如果有f 则匹配出,如果没有f,匹配结果为空,对比*
(6)元字符"?" 表示匹配"?"前边的字符 个数为闭区间[0,1] 即:0个或者1个
#实例: ret = re.findall(\'a?b\',\'aaaabkshkgabsdbannndbab\') print(ret) # 输出结果:[\'ab\', \'ab\', \'b\', \'b\', \'ab\']
(7)元字符"{}" 表示匹配"{}"前边的字符 指定个数为"{}"里边的数值
#实例1: ret = re.findall(\'a{5}b\',\'aaaaab\') #匹配字符a 并且指定个数为5 即:表示匹配连续的5个a加上b print(ret) # 输出结果:[\'aaaaab\'] #实例2: ret = re.findall(\'a{}b\',\'aaaaab\') # 如果中括号里边不加任何值 则表示{} 按照普通字符来匹配。 print(ret) # 输出结果为空[] 因为字符串\'aaaaab\'中没有"{}",将字符串\'aaaaab\'改成\'aaaaa{}b\' 就可以匹配到了。 #实例3: ret = re.findall(\'a{1,3}b\',\'jksjablskflskaabdlsfaaaaab\') # 大括号里边可以加参数{1,3}表示字符个数的范围。 print(ret) # 输出结果:[\'ab\', \'aab\', \'aaab\'] #实例4: ret = re.findall(\'a{1,3}b\',\'dlsfaaaaab\') # 如果目标匹配对象中,只有一个 个数大于等于3的字符串 那么默认匹配显示最多;即:aab 而不是ab 或者 abb [贪婪匹配] print(ret) # 输出结果:[\'aaab\']
(8)元字符"[]" 表示一个字符集,它常被用来指定一个字符类别,所谓字符类别就是你想匹配的一个字符集。字符可以单个列出,也可以用“-”号分隔的两个给定字符来表示一个字符区间。例如:[abc]将匹配"a","b",或者"c"中的任意一个字符;也可以用区间[a-c]来表示同一个字符集,和前者效果一致。如果只想匹配小写字符则可以写成[a-z]。
#实例1: ret = re.findall(\'a[c,d,e]x\',\'adx\') # []里边的内容 表示或者的关系 也就是说只要出现任意中括号中的内容 就会匹配。 print(ret) #实例2: ret = re.findall(\'[1-9,a-z,A-Z]\',\'123jskdjJWKJKJKS\') # ret = re.findall(\'[1-9a-zA-Z]\',\'123jskdjJWKJKJKS\') # 输出结果和上边的相同 只是解释器判断的逻辑顺序不同 print(ret) # 输出结果:[\'1\', \'2\', \'3\', \'j\', \'s\', \'k\', \'d\', \'j\', \'J\', \'W\', \'K\', \'J\', \'K\', \'J\', \'K\', \'S\'] #实例3: "^" 尖角号放在中括号中 表示:除了XXX字符 即:非 ret = re.findall(\'[^4,5]\',\'flja4slfj5\') # 表示非4 或则 非5 print(ret) # 输出结果:[\'f\', \'l\', \'j\', \'a\', \'s\', \'l\', \'f\', \'j\']
(9)元字符"\\" 反斜杠
反斜杠后边跟元字符,去除其特殊功能反斜杠
反斜杠后边跟普通字符,实现其特殊功能
\\d #表示:匹配任何十进制数,它相当于[0-9] \\D #表示:匹配任何 非 数字字符,它相当于[^0-9] \\s #表示:匹配任何空白字符,它相当于[\\t\\n\\r\\f\\v] \\S #表示:匹配任何 非 空白字符,它相当于[^\\t\\n\\r\\f\\v] \\w #表示:匹配任何字母数字字符,它相当于[a-zA-Z0-9] \\W #表示:匹配任何 非 字母数字字符,它相当于[^a-zA-Z0-9] \\b #表示:匹配一个单词边界,即:匹配字符和空格间的位置
#实例: print(re.findall(\'\\w\',\'fada sess\')) print(re.findall(\'\\W\',\'fada sess\')) # 匹配任何 非 字母数字字符 这里相当于“空格” print(re.findall(\'a\\b\',\'fada sess\')) # print(re.findall(r\'a\\b\',\'fada sess\')) # 加r表示 原生字符串读取
(10)元字符"()" 表示:分组 将括号中的内容 当作整体来对待
#实例1: print(re.findall(\'(as)\',\'ksjdksjasas\')) print(re.findall(\'(as)+\',\'ksjdksjasas\')) print(re.search(\'(as)\',\'ksjdksjasas\').group()) print(re.search(\'(as)+\',\'ksjdksjasas\').group()) # 输出结果对比: # [\'as\', \'as\'] # [\'as\'] # as # asas #实例2: print(re.search(\'(as)\',\'ksjdksjasas\').group()) print(re.search(\'(as)|222\',\'ksjdksjasas222\').group()) # | 管道符表示或者 # 输出结果:相同 因为管道符前边的匹配成功后,后边的条件“222”就不会去匹配。 # as # as #实例3: ret = re.search(\'(?P<id>\\d{3})/(?P<name>\\w{6})\',\'skejksd001/jessonadf002/pitterxd\') print(ret.group()) print(ret.group(\'id\')) # group(\'\')添加组成员参数 print(ret.group(\'name\')) # 输出结果: # 001/jesson # 001 # jesson #.findall() 对比上方的 .search() ret = re.findall(\'(?P<id>\\d{3})/(?P<name>\\w{6})\',\'skejksd001/jessonadf002/pitterxd\') print(ret) # 输出结果: #[(\'001\', \'jesson\'), (\'002\', \'pitter\')]
(11)元字符"|" 管道符 表示逻辑:或者
print(re.search(\'(as)|222\',\'ksjdksjasas222\').group()) print(re.findall(\'(as)|222\',\'jasas222\'))
元字符功能总结:
"." 通配符,匹配任意单个字符,默认不会匹配\\n换行符,加re.S可以实现匹配换行符 "^" 从整个字符串开头的地方匹配 "$" 从整个字符串的结尾开始匹配 即:从后往前匹配 "*" 重复匹配 (表示匹配重复的*号前边字符 个数从0到正无穷) "+" 匹配“+”前边的字符 个数从1到正无穷都能匹配 "?" 匹配"?"前边的字符 个数为闭区间[0,1] 即:0个或者1个 "{}" 匹配"{}"前边的字符 指定个数为"{}"里边的数值 "[]" 表示一个字符集,常被用来指定匹配一个字符类别 例如:[0-9,a-z,A-Z] "\\" 反斜杠 后边跟元字符,去除其特殊功能;后边跟普通字符,实现其特殊功能 "()" 表示:分组 将括号中的内容 当作整体来对待 "|" 管道符 表示逻辑:或者 常常配合分组使用;例如:print(re.findall(\'(as)|222\',\'jasas222\'))
三 方法
(1) 方法:findall() (即:全部找到,返回的是一个列表)
#实例: s = \'hello world\' ret = re.findall(\'w\\w{3}d\',\'hello world\') print(ret)
(2) 方法:search() (即:匹配出第一个满足条件的结果,返回的是一个对象) 可以通过调用.group()方法,可以将匹配的结果输出。
#实例: ret = re.search(\'h..\',\'hello hello world\') print(ret) # 输出结果:<_sre.SRE_Match object; span=(0, 3), match=\'hel\'> ret1 = re.search(\'h..\',\'hello hello world\').group() print(ret1) # 输出结果:hel 只输出第一个符合条件的结果
(3)方法:match() 返回匹配到的第一个对象,只在字符串开始匹配。同样,可以通过调用.group()方法,可以将匹配的结果输出。
#注意: # match() 只检测RE是不是在string的开始位置匹配, # search() 会扫描整个string查找匹配; # 也就是说match() 只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
#实例: ret = re.match(\'asd\',\'asdhskdjfksji\') print(ret) # 输出结果:<_sre.SRE_Match object; span=(0, 3), match=\'asd\'>返回的是一个对象。 ret1 = re.match(\'asd\',\'asdhskdjfasdksjiasd\').group() print(ret1) # 输出结果:asd 调用.group()方法,只返回匹配的第一个结果。
(4)方法:split() 分隔符 对比字符串里边的split方法。
实例1: ret = re.split(\'j\',\'dsdhsjdwakjdswddkdjsjwkjd\') print(ret) # 输出结果:[\'dsdhsjd\', \'jds\', \'jd\'] 以k为分隔符,将字符分隔,返回结果。 实例2: ret1 = re.split(\'[j,k]\',\'dsdhsjdwakjdswddkdjsjwkjd\') print(ret1) # 输出结果: [\'dsdhs\', \'dwak\', \'dswddkd\', \'s\', \'wk\', \'d\'] [\'dsdhs\', \'dwak\', \'dswddkd\', \'s\', \'wk\', \'d\'] [\'dsdhs\', \'dwa\', \'\', \'dswdd\', \'d\', \'s\', \'w\', \'\', \'d\'] # 对比上方的两个输出结果,可以发现:匹配的执行顺序是,先以中括号中的第一个规则字符“j”进行匹配, # 然后,在分隔结果的基础上,再以第二个规则字符“k”,对其进行分隔。匹配结果中单独的字符"k" 被分隔后,输出空\'\'
(5)方法: sub() 替换;类似字符串中的replace()方法。
ret = re.sub(\'a..x\',\'jesson\',\'hello,alex\') print(ret) # 输出结果:hello,jesson
(6)方法: compile(strPattern[,flag]): 这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。第二个参数flag是匹配模式,取值可以使用 按位 或 运算符“|” 表示同时生效。
简单来说,该方法的功能就是:可以把正则表达式编译成一个正则表达式对象。一定程度,可以提高效率。
#实例: # 未采用compile()方法: ret = re.findall(\'\\.com\',\'www.baidu.com___www.jingdong.com\') print("ret",ret) # 采用compile()方法: obj = re.compile(\'\\.com\') ret1 = obj.findall(\'www.baidu.com___www.jingdong.com\') print("ret1",ret1) # 两次输出结果:相同 # ret [\'.com\', \'.com\'] # ret1 [\'.com\', \'.com\']
以上是关于Python 正则表达式的主要内容,如果未能解决你的问题,请参考以下文章