.NET面试题系列[13] - LINQ to Object
Posted Chobits的文集
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.NET面试题系列[13] - LINQ to Object相关的知识,希望对你有一定的参考价值。
.NET面试题系列目录
名言警句
"C# 3.0所有特性的提出都是更好地为LINQ服务的" - Learning Hard
LINQ是Language Integrated Query(语言集成查询)的缩写,读音和单词link相同。不要读成“lin-Q”。
LINQ to Object将查询语句转换为委托。LINQ to Entity将查询语句转换为表达式树,然后再转换为SQL。
LINQ的好处:强类型,相比SQL语句它更面向对象,对于所有的数据库给出了统一的操作方式。
LINQ的一些问题:要时刻关注转换的SQL来保持性能,另外,某些操作不能转换为SQL语句,以及很难替代存储过程。
在面试时,大部分面试官都不会让你手写LINQ查询,至少就我来说,写不写得出LINQ的Join并没所谓,反正查了书肯定可以写得出来。但面试官会对你是否理解了LINQ的原理很感兴趣。实际上自有了委托起,LINQ就等于出现了,后面的特性都可以看成是语法糖。如果你可以不用LINQ而用原始的委托实现一个类似LINQ中的where,select的功能,那么你对LINQ to Object应该理解的不错了。
Enumerable是什么?
Enumerable是一个静态类型,其中包含了许多方法,绝大部分都是扩展方法(它也有自己的方法例如Range),返回IEnumerable (因为IEnumerable是延迟加载的,每次访问的时候才取值),而且绝大部分扩展的是IEnumerable<T>。
Enumerable是一个静态类型,不能创建Enumerable类型的实例。
Enumerable是LINQ to Object的基础。因为LINQ to Object绝大多数时候都是和IEnumerable<T>以及它的派生类打交道,扩展了IEnumerable<T>的Enumerable类,赋予IEnumerable<T>强大的查询能力。
序列 (Sequence)
序列就像数据项的传送带,你每次只能获取一个,直到你不想获取或者序列没有数据为止。序列可能是无限的(例如你可以写一个随机数的无限序列),当你从序列读取数据的时候,通常不知道还有多少数据项等待读取。
LINQ的查询就是获得序列,然后通常在中间过程会转换为其他序列,或者和额外的序列连接在一起。
延迟执行 (Lazy Loading)
大部分LINQ语句是在最终结果的第一个元素被访问的时候(即在foreach中调用MoveNext方法)才真正开始运算的,这个特点称为延迟执行。一般来说,返回另外一个序列(通常为IEnumerable<T>或IQueryable<T>)的操作,使用延迟执行,而返回单一值的运算,使用立即执行。
例如下面的例子:实际上,当这两行代码运行完时,ToUpper根本没有运行过。

或者下面更极端的例子,虽然语句很多,但其实在你打算遍历结果之前,这一段语句根本不会占用任何时间:

那么如果我们这样写,会不会有任何东西打印出来呢?

答案是不会。问题的关键是,IEnumerable<T>是延迟执行的,当没有触发执行时,就不会进行任何运算。Select方法不会触发LINQ的执行。一些触发的方式是:
- foreach循环
- ToList,ToArray,ToDictionary方法等
例如下面的代码:

它的输出是:

注意所有名字都打印出来了,而全部大写的名字,只会打印长度大于3的。为什么会交替打印?这是因为在开始foreach枚举时,uppercase的成员还没确定,我们在每次foreach枚举时,都先运行select,打印原名,然后筛选,如果长度大于3,才在foreach中打印,所以结果是大写和原名交替的。
利用ToList强制执行LINQ语句
下面的代码和上面的区别在于我们增加了一个ToList方法。思考会输出什么?
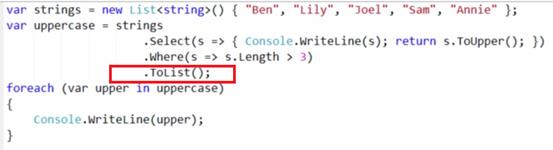
ToList方法强制执行了所有LINQ语句。所以uppercase在Foreach循环之前就确定了。其将仅仅包含三个成员:Lily,Joel和Annie(都是大写的)。故将先打印5个名字,再打印uppercase中的三个成员,打印的结果是:

LINQPad
LINQPad工具是一个很好的LINQ查询可视化工具。它由Threading in C#和C# in a Nutshell的作者Albahari编写,完全免费。它的下载地址是http://www.linqpad.net/
进入界面后,LINQPad可以连接到已经存在的数据库(不过就仅限微软的SQL Server系,如果要连接到其他类型的数据库则需要安装插件)。某种程度上可以代替SQL Management Studio,是使用SQL Management Studio作为数据库管理软件的码农的强力工具,可以用于调试和性能优化(通过改善编译后的SQL规模)。

你可以使用Northwind演示数据库进行LINQ的学习。Northwind演示数据库的下载地址是https://www.microsoft.com/en-us/download/details.aspx?id=23654。连接到数据库之后,LINQPad支持使用SQL或C#语句(点标记或查询表达式)进行查询。你也可以通过点击橙色圈内的各种不同格式,看到查询表达式的各种不同表达方式:
- Lambda:查询表达式的Lambda表达式版本
- SQL:由编译器转化成的SQL,通常这是我们最关心的部分
- IL:IL语言

查询操作
假设我们有一个类productinfo,并在主线程中建立了一个数组,其含有若干productinfo的成员。我们在写查询之前,将传入对象Product,其类型为productinfo[]。
基本的选择语法
获得product中,所有的产品的所有信息(注意p是一个别名,可以随意命名):
From p in products
select p
SQL: select * from products
获得product中,所有的产品名称:
From p in products
select p.name
SQL: select name from products
Where子句
获得product中,所有的产品的所有信息,但必须numberofstock属性大于25:
From p in products
where p. numberofstock > 25
select p
SQL: select * from products where numberofstock > 25
Where子句中可以使用任何合法的C#操作符,&&,||等,这等同于sql的and和or。
注意最后的select p其实是没有意义的,可以去掉。如果select子句什么都不做,只是返回同给定的序列相同的序列,则编译器将会删除之。编译器将会把这个LINQ语句转译为product.Where(p => p. numberofstock > 25)。注意后面没有Select跟着了。
但如果将最后的select子句改为select p.Name,则编译器将会把这个LINQ语句转译为product.Where(p => p. numberofstock > 25).Select(p => p.Name)。
Orderby子句
获得product中,所有的产品名称,并正序(默认)排列:
From p in products
order by p.name
select p.name
SQL: select name from products order by name
ThenBy子句必须永远跟在Orderby之后。
Let子句
假设有一个如下的查询:
var query = from car in myCarsEnum orderby car.PetName.Length select car.PetName; foreach (var name in query) { Console.WriteLine("{0}: {1}", name.Length, name); }
我们发现,对name.Length引用了两次。我们是否可以引入一个临时变量呢?上面的查询将会被编译器改写为:
myCarsEnum.OrderBy(c => c.PetName.Length).Select(c => c.PetName)。
我们可以使用let子句引入一个临时变量:
var query = from car in myCarsEnum let length = car.PetName.Length orderby length select new {Name = car.PetName, Length = length}; foreach (var name in query) { Console.WriteLine("{0}: {1}", name.Length, name.Name); }
上面的查询将会被编译器改写为:
myCarsEnum
.Select(car => new {car, length = car.Length})
.OrderBy(c => c.Length)
.Select(c => new { Name = c.PetName, Length = c.Length})。
可以通过LINQPad获得编译器的改写结果。
在此处,我们可以看到匿名类型在LINQ中发挥了作用。select new {Name = car.PetName, Length = length} (匿名类型)使我们不费吹灰之力就得到了一个新的类型。
连接
考察下面两个表格:
表Defect:

表NotificationSubscription:

我们发现这两个表都存在一个外码ProjectID。故我们可以试着进行连接,看看会发生什么。
使用join子句的内连接
在进行内连接时,必须要指明基于哪个列。如果我们基于ProjectID进行内连接的话,可以预见的是,对于表Defect的ProjectID列,仅有1和2出现过,所以NotificationSubscription的第一和第四行将会在结果集中,而其他两行不在。
查询:
from defect in Defects join subscription in NotificationSubscriptions on defect.ProjectID equals subscription.ProjectID select new { defect.Summary, subscription.EmailAddress }
如果我们调转Join子句前后的表,结果的记录数将相同,仅是顺序不同。LINQ将会对连接延迟执行。Join右边的序列被缓存起来,左边的则进行流处理:当开始执行时,LINQ会读取整个右边序列,然后就不需要再读取右边序列了,这时就开始迭代左边的序列。所以如果要连接一个巨大的表和一个极小的表时,请尽量将小表放在右边。
编译器的转译为:
Defects.Join ( NotificationSubscriptions, defect => defect.ProjectID, subscription => subscription.ProjectID, (defect, subscription) => new { Summary = defect.Summary, EmailAddress = subscription.EmailAddress } )
使用join into子句进行分组连接
查询:
from defect in Defects join subscription in NotificationSubscriptions on defect.Project equals subscription.Project into groupedSubscriptions select new { Defect=defect, Subscriptions=groupedSubscriptions }
其结果将会是:

内连接和分组连接的一个重要区别是:分组连接的结果数一定和左边的表的记录数相同(例如本例中左边的表Defects有41笔记录,则分组连接的结果数一定是41),即使某些左边表内的记录在右边没有对应记录也无所谓。这类似SQL的左外连接。与内连接一样,分组连接缓存右边的序列,而对左边的序列进行流处理。
编译器的转译为简单的调用GroupJoin方法:
Defects.GroupJoin ( NotificationSubscriptions, defect => defect.Project, subscription => subscription.Project, (defect, groupedSubscriptions) => new { Defect = defect, Subscriptions = groupedSubscriptions } )
使用多个from子句进行叉乘
查询:
from user in DefectUsers from project in Projects select new { User = user, Project = project }
在DefectUsers表中有6笔记录,在Projects表中有3笔记录,则结果将会是18笔:
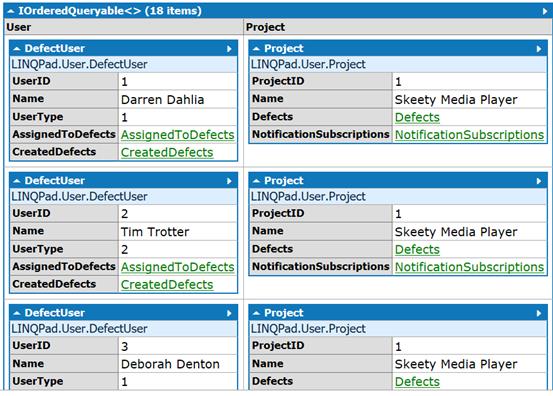
编译器将会将其转译为方法SelectMany:
DefectUsers.SelectMany ( user => Projects, (user, project) => new { User = user, Project = project } )
即使涉及两个表,SelectMany的做法完全是流式的:一次只会处理每个序列中的一个元素(在上面的例子中就是处理18次)。SelectMany不需要将右边的序列缓存,所以不会一次性向内存加载很多的内容。
在查询表达式和点标记之间做出选择
很多人爱用点标记,点标记这里指的是用普通的C#调用LINQ查询操作符来代替查询表达式。点标记并非官方名称。对这两种写法的优劣有很多说法:
- 每个查询表达式都可以被转换为点标记的形式,而反过来则不一定。很多LINQ操作符不存在等价的查询表达式,例如Reverse,Sort等等。
- 既然点标记是查询表达式编译之后的形式,使用点标记可以省去编译的一步。
- 点标记比查询表达式具有更高的可读性(并非对所有人来说,见仁见智)
- 点标记体现了面向对象的性质,而在C#中插入一段SQL让人觉得不伦不类(见仁见智)
- 点标记可以轻易的接续
- Join时查询表达式更简单,看上去更像SQL,而点标记的Join非常难以理解
C# 3.0所有的特性的提出都是更好地为LINQ服务的
下面举例来使用普通的委托方式来实现一个where(o => o > 5):
public delegate bool PredicateDelegate(int i); public static void Main(string[] args) { var seq = Enumerable.Range(0, 9); var seqWhere = new List<int>(); PredicateDelegate pd = new PredicateDelegate(Predicate); foreach (var i in seq) { if (pd(i)) { seqWhere.Add(i); } } } //The target predicate delegate public static bool Predicate(int input) { return input > 5; }
由于where是一个判断,它返回一个布尔值,所以我们需要一个形如Func<int, bool>的委托,故我们可以构造一个方法,它接受一个int,返回一个bool,在其中实现筛选的判断。最后,对整个数列进行迭代,并一一进行判断获得结果。如果使用LINQ,则整个过程将会简化为只剩一句话。
C# 2.0中匿名函数的提出使得我们可以把Predicate方法内联进去。如果没有匿名函数,每一个查询你都要写一个委托目标方法。
public delegate bool PredicateDelegate(int i); public static void Main(string[] args) { var seq = Enumerable.Range(0, 9); var seqWhere = new List<int>(); PredicateDelegate pd = delegate(int input) { return input > 5; }; foreach (var i in seq) { if (pd(i)) { seqWhere.Add(i); } } }
C#是在Where方法中进行迭代的,所以我们看不到foreach。由于Where是Enumerable的扩展方法,所以可以对seq对象使用Where方法。
有时候我们需要从数据库中选择几列作为结果,此时匿名类型的存在使得我们不需要为了这几列去辛辛苦苦的建立一个新的类型(除非它们经常被用到,此时你可能就需要一个ViewModel层)。隐式类型的存在使得我们不需要思考通过查询语句获得的类型是何种类型(大部分时候,我们也不关心它的类型),只需要简单的使用var就可以了。
var seq = Enumerable.Range(0, 9); var seq2 = seq.Select(o => new { a = o, b = o + 1 });
以上是关于.NET面试题系列[13] - LINQ to Object的主要内容,如果未能解决你的问题,请参考以下文章