递归神经网络的不可思议的有效性 [ 译 / 转 ]
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了递归神经网络的不可思议的有效性 [ 译 / 转 ]相关的知识,希望对你有一定的参考价值。
递归神经网络(Recurrent Neural Networks,RNNs)就像一种神奇的魔法。我至今仍对于我第一次训练递归网络记忆犹新。那个网络是被用于生成图像说明(Image Captioning)的。仅仅进行了几十分钟的训练,我的第一个模型(这个模型中相当一部分超参数都是我随意选取的)就开始能给图片生成看起来非常不错的描述,而这些描述基本上能称得上是有意义的。有时结果的质量和模型复杂度之间的关联性完全超出你的预期,而我的第一次实验就是一个例子。为什么当时这些训练结果看起来如此惊人?是因为大家本来都认为RNNs很难训练(而我的经验告诉我恰恰相反)。简单的回顾一下之前一年的工作,我一直在训练RNNs的模型,并且我已经一次又一次地见证了它们的力量和鲁棒性,但是它们魔法般的输出仍然总能让我眼前一亮。这篇博文就是来和你分享一下这种神奇的魔法。
我们将训练通过字符生成文本字符的递归神经网络,然后好好考虑这个问题“这怎么可能?”
另外,作为这篇博文的配套内容,我在GitHub上发布了代码,可以用于训练基于多层LSTMs的字符等级的语言模型。你输入一堆文本数据,它就会学着一次一个地生成与之类似的文本。你也可以用那些代码重现我写在下面的实验。我们已经开始超越自己了,毕竟这可是RNNs啊!
递归神经网络
序列(Sequences)。基于你的背景,你可能很想知道:什么让递归神经网络如此特别?Vanilla神经网络(和卷积网络)的一个重要的局限性是他们的API被严格的约束:它接受的输入是一个固定维数的向量(例如一幅图像)并且生成的输出也是一个固定维数的向量(例如不同类的概率)。不仅仅如此,这些模型执行绘制过程时经过固定数目的计算步骤(例如模型层的数量)。这种递归网络更使人兴奋的核心原因是它允许我们对向量的序列进行操作:输入的序列、输出的序列抑或最常见情况的序列。下面的一些例子可以证实这一点:
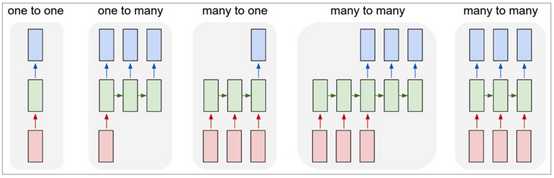
矩形代表向量,箭头代表函数(例如矩阵乘法)。输入向量是红色的,输出向量是蓝色的,绿色则代表RNN的状态(许多情况下这种状态都是一闪而过的)。从左到右依次是:(1)没有使用RNN的Vanilla模型,固定维数的输入,固定维数的输出(例如图像分类)(2)序列输出(例如图像说明,输入一幅图像,输出一串单词)(3)序列输入(例如情感分析,输入一个句子,分类它是积极的情感还是消极的情感)(4)序列输入和序列输出(例如机器翻译,一个RNN系统输入英语的句子,输出法语的句子)(5)同步的序列输入输出(例如视频分类,对每一帧给出一个标签)。请注意,每一种情况没有预先明确对于序列长度的限制,因为递归变换(绿色的)是固定的并且可以根据我们的需求多次执行。
你可以已经发现,对于运算的序列化管理,比那些从一开始就被固定的运算步骤所限制的固定网络要强大得多。因此,这也对于我们中那些立志于构建更加智能的系统的研究者更具吸引力。此外,正如我们将看到的,RNNs通过固定(但是已知的)的函数来结合输入向量的状态向量,从而生成新的状态向量。这一点从编程角度而言可以理解为执行一个对于确定输入和中间变量的固定程序。从这种角度看来,RNNs本质上描述了一套程序。事实上,众所周知, RNNs是图灵完备的 ,即它们可以模拟任意程序(使用恰当的权值向量)。但是,类似于通用逼近定理神经网络,你还不应该深入阅读。就当我没说过这些吧。
如果训练Vanilla神经网络是优化功能,那么训练递归神经网络则是优化程序。
序列缺失情况下的序列处理。你可能会想,有序列作为输入或输出可能是相对少见的,但关键是,即使你的输入/输出是固定向量,仍然有可能使用这种强大的以序列的方式来处理它们。比如,下图显示了 DeepMind 中两篇非常棒的论文的结果。在左边,一个算法学习了一种递归网络策略,可以将它的注意力集中在图像周围;特别的,它学会了从左到右阅读门牌号码( Ba等人 )。在右边,一个递归网络通过学习在画布上序列化地添加颜色然后生成一张数字图像( Gregor等人 );


左边:RNN学习阅读门牌号。右边:RNN学习学习绘制门牌号。
即使你的数据不是序列形式的,你仍然可以制定并训练出强大的模型来学习处理它。你可以学习有状态的程序来处理固定大小的数据。
RNN计算。那么这些是如何工作的呢?主要是,RNNs有一个非常简洁的API:它们将向量x作为输入,然后输出结果向量y.然而,关键的是这个输出向量的内容不仅受到前一次输入数据的影响,而且还会受整个历史输入数据的影响。这个API编写成了一个类,它由一个step方法构成:
rnn = RNN()
y = rnn.step(x) # x is an input vector, y is the RNN‘s output vector
RNN类有一些内部的状态,会在每一次调用 step方法的时候进行更新。最简单的情况是,这个状态由单个隐藏向量h构成。下面是Vanilla RNN中对step方法的一种实现:
classRNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
上面的代码指明了vanilla RNN的前馈操作。这个RNN的参数是以下三个矩阵:w_hh,w_xh,w_hy。隐藏状态self.h由两个零向量初始化。np.tanh函数实现了非线性的方法,将活化结果压缩到范围[-1,1]之内。简单介绍工作原理:tanh中有两种形式:一种是基于前面的隐藏状态,另一种是基于当前的输入。numpy中的np.dot是矩阵乘法。这两种中间体相加,然后由tanh函数将它压缩成一个新的状态向量。如果你适合看数学公式的话,我们同样可以将隐藏状态写成 ht+1 =tanh(Whh ht+ Wxhx t), tanh函数是元素智能的。
我们用随机数来初始化RNN矩阵,通过大量的训练找到一个令人满意的矩阵,并且用一些损失函数来度量,你可以在输入序列x上得到你希望的输出y。
更深层次说明。RNNs是一种神经网络,而且如果你开始学习深度学习并开始像堆煎饼一样积累模型,它们将会工作得更好(如果做得正确的话)。例如,我们可以通过以下方式建立一个2层的递归网络:
y1 = rnn1.step(x)
y = rnn2.step(y1)
换句话说,我们有两个独立的RNNs:一个RNN接收输入向量,另一个将前一个RNN的输出作为输入。这两个RNN没有本质区别——这不外乎就是向量的输入输出而已,而且在反向传播过程中每个模块都伴随着梯度操作。
来点更奇特的。我会简要说明,实际上我们大多数人使用一种与上面我所提及稍微不同的网络,它叫做长短期记忆(LSTM)网络。LSTM是一种特殊类型的递归网络,在实践中工作效果更佳,这归功于其强大的更新方程和一些吸引人的动态反向传播功能。我不会详细介绍,除了用于更新计算(self.h=···)的数学形式有点更复杂外,与其他RNNs没有多大区别。从现在开始,我将会交替使用术语“RNN/LSTM”,但是这篇文章中所有的实验都是用LSTM完成的。
字符级语言模型
好,我们现在已经初步了解了什么是RNNs,为什么它们如此令人兴奋,还有它们是如何工作的。我们现在就用它来实现一个有趣的应用:我们将要训练字符级的语言RNN模型。具体来说就是,我们将会向RNN输入大量的文本数据,然后在一个序列中给定一个前面的字符,用它来建立计算这个序列下一个字符概率的模型。这将会让我们在同一时间产生新文本字符。
作为一个案例,假设我们只有四种字母的词汇“helo”,然后我们想要用训练序列“hello”训练一个RNN。这个训练序列实际上是来自于4个独立的训练案例:1.字母e应该在字母h出现的情况下才可能出现,2.字母l应该出现在he出现的情况下,3.字母l同样可以出现在hel出现的情况下,最后4.字母o应该出现在hell出现的情况下。
具体来说,我们将用1-of-k编码(所有都是0,除了词汇中字符的索引)将每个字符编码成一个向量,然后用step函数每次向RNN中输入一个字符。然后我们会看到一个4维序列的输出向量(每个字符代表一个维度),我们将此作为RNN分配给序列下一个字符的置信度。下面是一张案例图:
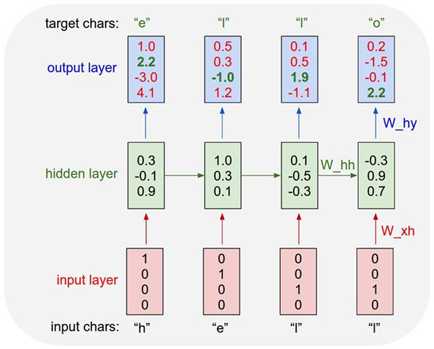
一个有四维输入输出层和一个有着3个单元(神经元)的隐藏层的实例。这张图显示了当将“helo”作为RNN的输入时前馈操作的活化结果。输出层包含了RNN对下一个出现字符(这里词汇是“h,e,l,o”)的置信度。我们希望使得绿色的数字尽可能高而红色数字尽可能低。
比如,我们可以看出,在第一次执行step函数的时候,RNN读取到字符“h”然后将它之后可能出现字符“h”的置信度设置为1.0,可能出现字符“e”的置信度设置为2.2,可能出现字符“l”的置信度设置为-3.0,可能出现字符“o”的置信度设置为4.1。因为在我们的训练数据中,下一个出现的字符是“e”,我们将要提高这个字符的置信度(绿色数字)并且降低其他字符的置信度(红色数字)。通常的做法是使用一个交叉熵损失函数,这相当于在每个输出向量上使用Softmax分类器,将下一个出现的字符的索引作为一个正确的分类。一旦损失进行了反向传播并且RNN权值得到更新,在输入相同的情况下,下一个正确的字符将会有更高的分数。技术解释:该RNN是由小批量随机梯度下降训练的。我喜欢使用 RMSProp (每个参数的自适应学习率)来稳定更新。
同样可以注意到,字符“l”第一次输入时,得到的结果是“l”,但是第二得到的结果是“o”。因此,这个RNN不能单独依赖于输入数据,必须使用它的递归连接来跟踪内容以达到准确结果。
在测试的时候,我们向RNN输入一个字符,然后得到了下一个可能出现字符的分布。我们从这个分布中抽样,然后又将这些样本输入到RNN中得到下一个字符。重复这个过程,你就在做取样的工作了!现在让我们在不同数据集上训练RNN,看看会有什么发生。
为进一步说明,出于教育目的我还写了一篇文章 minimal character-level RNN language model in Python/numpy 。只有大约100行代码,如果你更擅长阅读代码而不是文字,你可以从中得到简明的、具体的、有用的结论。现在我们将深入到实例结果,使用更高效的Lua/Torch代码库来编程。
使用RNNs的有趣之处
下面的5个字符模型案例都是使用我发布在Github上的代码进行训练的。每个实例的输入都是单个文本文件,然后我们训练RNN预测序列中下一个可能出现的字符。
保罗·格雷厄姆生成器
首先让我们尝试用一个小英语数据集作一个全面检查。我个人最喜欢的数据集是 Paul Graham散文串联集。其基本思路是,散文中有很多智慧,不幸的是Paul Graham是一个相对缓慢的生成器。如果我们能够按需生成智慧样本,那不是很强大?RNNs在这里就起到了作用。
连接过去5年所有的论文,我们得到了大约1MB的文本文件,或者说是大约100万个字符(这是一个非常小的数据集)。技术方面:我们用512个隐藏节点(大约350万个参数)来训练一个2层的LSTM,然后在每层之后设定参数为0.5的dropout层。我们将每批训练100个实例,然后每超过100个字符则停止反向传播。通过这些设置,每一批在TITAN Z GPU上处理完成大约需要0.46秒(这通过性能代价忽略不计的50个字符的BPTT算法将它分为两半)。事不宜迟,让我们看看RNN中的样本:
"The surprised in investors weren‘t going to raise money. I‘m not the company with the time there are all interesting quickly, don‘t have to get off the same programmers. There‘s a super-angel round fundraising, why do you can do. If you have a different physical investment are become in people who reduced in a startup with the way to argument the acquirer could see them just that you‘re also the founders will part of users‘ affords that and an alternation to the idea. [2] Don‘t work at first member to see the way kids will seem in advance of a bad successful startup. And if you have to act the big company too."
好了,很明显上面的样本不会很快随时取代Paul Graham,但请记住, RNN不得不完全从一个小的数据集(包括逗号,顿号和空格的位置)开始学习英语。我同样喜欢让它来学习支持自己的论证(比如上面的[2])。有时,它会提供一些可洞察的东西,比如“ a company is a meeting to think to investors”。如果你想了解更多,点击这个 链接,它有5万个字符样本数据。
温度。我们同样可以在Softmax取样的时候对温度进行操作。将温度从1降至更低的数字(比如0.5)可以让RNN有更高的置信度,但是样本就会更保守。相反地,较高的温度将会得到更多元化的结果,但是失误就更多(比如拼写错误等)。特别地,将温度设置成与0接近的数字就会得到与Paul Graham相似的言论:
"is that they were all the same thing that was a startup is that they were all the same thing that was a startup is that they were all the same thing that was a startup is that they were all the same"
看起来我们陷入了startups的死循环了。
莎士比亚
看样子好像我们的模型可以学习拼写英语单词,但是数据更结构化更风格化又会怎样呢?为了检测这一点,我下载了莎士比亚所有的作品并将它们串起来组成一个单一的(4.4MB)文件。现在我们可以训练一个更大的网络了,在这个例子中,我们尝试使用每层上都拥有512个隐藏节点的3层RNN网络。在我们训练网络几小时后,我们得到了如下样本:
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain‘d into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
DUKE VINCENTIO:
Well, your wit is in the care of side and that.
Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I‘ll have the heart of the wars.
Clown:
Come, sir, I will make did behold your worship.
VIOLA:
I‘ll drink it.
切记,RNN只认识字符,所以它将说话者的名字和内容一起生成为样本。有时,我们还可以得到相对延伸的独白段落,比如:
VIOLA:
Why, Salisbury must find his flesh and thought
That which I am not aps, not a man and in fire,
To show the reining of the raven and the wars
To grace my hand reproach within, and not a fair are hand,
That Caesar and my goodly father‘s world;
When I was heaven of presence and our fleets,
We spare with hours, but cut thy council I am great,
Murdered and by thy master‘s ready there
My power to give thee but so much as hell:
Some service in the noble bondman here,
Would show him to her wine.
KING LEAR:
O, if you were a feeble sight, the courtesy of your law,
Your sight and several breath, will wear the gods
With his heads, and my hands are wonder‘d at the deeds,
So drop upon your lordship‘s head, and your opinion
Shall be against your honour.
在这些样本中,我几乎认不出这是莎士比亚的作品:)如果你喜欢莎士比亚,你可能会重视这份100,000个字符的样本。当然,你也可以用我提供的代码,在不同温度下生成许多你自己的样本。
维基百科
我们看到,LSTM可以学习拼写单词和复制一般的句法结构。让我来加大难度,在结构化markdown语言上训练网络。特别的,让我们使用 Hutter Prize 的100MB的Wikipedia原始数据训练一个LSTM。在Graves等人 之后,我使用前96MB数据来训练,剩下的则花一个晚上用来验证和运行几个模型。现在我们可以取样Wikipedia文章了!下面是几个有趣的节选。首先,一些基本的markdown输出:
Naturalism and decision for the majority of Arab countries‘ capitalide was grounded
by the Irish language by [[John Clair]], [[An Imperial Japanese Revolt]], associated
with Guangzham‘s sovereignty. His generals were the powerful ruler of the Portugal
in the [[Protestant Immineners]], which could be said to be directly in Cantonese
Communication, which followed a ceremony and set inspired prison, training. The
emperor travelled back to [[Antioch, Perth, October 25|21]] to note, the Kingdom
of Costa Rica, unsuccessful fashioned the [[Thrales]], [[Cynth‘s Dajoard]], known
in western [[Scotland]], near Italy to the conquest of India with the conflict.
Copyright was the succession of independence in the slop of Syrian influence that
was a famous German movement based on a more popular servicious, non-doctrinal
and sexual power post. Many governments recognize the military housing of the
[[Civil Liberalization and Infantry Resolution 265 National Party in Hungary]],
that is sympathetic to be to the [[Punjab Resolution]]
(PJS)[http://www.humah.yahoo.com/guardian.
cfm/7754800786d17551963s89.htm Official economics Adjoint for the Nazism, Montgomery
was swear to advance to the resources for those Socialism‘s rule,
was starting to signing a major tripad of aid exile.]]
你可能会想,上面的雅虎url并不真实存在,该模型只是将它作为假想事物。同样,可以注意到模型学会正确打开和关闭插入语。模型同样学会了许多结构化markdown语言,比如,有时候它创建了头部信息和列表等:
{{citejournal|id=CerlingNonforestDepartment|format=Newlymeslated|none}}
‘‘www.e-complete‘‘.
‘‘‘Seealso‘‘‘:[[Listofethicalconsentprocessing]]
==Seealso==
*[[IenderdomeoftheED]]
*[[Anti-autism]]
===[[Religion|Religion]]===
*[[FrenchWritings]]
*[[Maria]]
*[[Revelation]]
*[[MountAgamul]]
==Externallinks==
*[http://www.biblegateway.nih.gov/entrepre/WebsiteoftheWorldFestival.ThelabourofIndia-countydefeatsattheRipperofCaliforniaRoad.]
==Externallinks==
*[http://www.romanology.com/ConstitutionoftheNetherlandsandHispanicCompetitionforBilabialandCommonwealthIndustry(RepublicanConstitutionoftheExtentoftheNetherlands)]
有时模型会生成随机但是有效的XML文件:
<page>
<title>Antichrist</title>
<id>865</id>
<revision>
<id>15900676</id>
<timestamp>2002-08-03T18:14:12Z</timestamp>
<contributor>
<username>Paris</username>
<id>23</id>
</contributor>
<minor />
<comment>Automated conversion</comment>
<text xml:space="preserve">#REDIRECT [[Christianity]]</text>
</revision>
</page>
这个模型完全拼凑出了timestamp,id等等。同样,注意到它以正确的嵌套顺序适当的闭合了正确的标签。如果你有兴趣了解更多,这里有 100,000 characters of sampled wikipedia。
代数几何(Latex)
以上结果表明,该模型在学习复杂句法结构方面表现得相当不错。这些结果令人印象深刻,我的实验伙伴( Justin Johnson )和我打算在结构上再深入研究,我们使用这本关于代数栈/几何的 书 。我们下载了Latex的源文件(16MB),然后训练了一个多层的LSTM。令人惊讶的是,由Latex产生的样本几乎是已经汇总好了的。我们不得不介入并手动修复了一些问题,这样你就得到了合理的数学推论,这是相当惊人的:

代数几何样本(假的), 真正的PDF文件在这 。
这是另一份样本:

产生了更多假的代数几何,尝试处理图像(右)
正如上面你所看到的那样,有些时候这个模型试图生成LaTeX图像,但很明显它并不明白图像的具体意思。同样我很喜欢模型选择跳过证明过程的那部分(“Proof omitted”,左上角)。当然,Latex有相对困难的结构化句法格式,我自己都还没有完全掌握。为举例说明,下面是模型中的一个原始样本(未被编辑):
\\begin{proof}
We may assume that $\\mathcal{I}$ is an abelian sheaf on $\\mathcal{C}$.
\\item Given a morphism $\\Delta : \\mathcal{F} \\to \\mathcal{I}$
is an injective and let $\\mathfrak q$ be an abelian sheaf on $X$.
Let $\\mathcal{F}$ be a fibered complex. Let $\\mathcal{F}$ be a category.
\\begin{enumerate}
\\item \\hyperref[setain-construction-phantom]{Lemma}
\\label{lemma-characterize-quasi-finite}
Let $\\mathcal{F}$ be an abelian quasi-coherent sheaf on $\\mathcal{C}$.
Let $\\mathcal{F}$ be a coherent $\\mathcal{O}_X$-module. Then
$\\mathcal{F}$ is an abelian catenary over $\\mathcal{C}$.
\\item The following are equivalent
\\begin{enumerate}
\\item $\\mathcal{F}$ is an $\\mathcal{O}_X$-module.
\\end{lemma}
这份样本来自一个相对合适的模型,其中显示出了一些常见错误。比如,模型打开了一个\\begin{proof}环境,但是却以\\end{lemma}结束。这个问题我们必须手动修复,这可能是由于依赖关系太长而导致的:当这个模型做完了 proof过程,它就忘记了它是在做proof还是lemma了。同样的,当模型打开了一个\\begin{enumerate}环境,然后却忘记关闭它了。我们发现,当我们使用更大/更好的模型的时候,这种情况出现得就较少了,尽管如此,这些问题还是会出现。
Linux源代码
我想看看这个模型处理结构化数据的极限,所以为了这一终极目标,我打算开始编写一些代码,特别的,我浏览了 Github上Linux repo 所有的原始资料和头文件,把它们串在一起形成一个单一的巨大文件(474MB大小的C代码)(我本来打算只训练内核,但是它只有16MB)。然后,我花了几天时间训练出了大小刚好适合我GPU的3层LSTM网络。这些模型有大约1000万个参数,然而这对于RNN网络来说还是微不足道的。结果非常有趣:
/*
* Increment the size file of the new incorrect UI_FILTER group information
* of the size generatively.
*/
staticintindicate_policy(void)
{
int error;
if (fd == MARN_EPT) {
/*
* The kernel blank will coeld it to userspace.
*/
if (ss->segment < mem_total)
unblock_graph_and_set_blocked();
else
ret = 1;
goto bail;
}
segaddr = in_SB(in.addr);
selector = seg / 16;
setup_works = true;
for (i = 0; i < blocks; i++) {
seq = buf[i++];
bpf = bd->bd.next + i * search;
if (fd) {
current = blocked;
}
}
rw->name = "Getjbbregs";
bprm_self_clearl(&iv->version);
regs->new = blocks[(BPF_STATS << info->historidac)] | PFMR_CLOBATHINC_SECONDS << 12;
return segtable;
}
这代码整体上看起来非常棒。我认为它不会马上就能编译通过,但是当你滚动查看这些代码的时候给你的感觉是这是一个非常强大的C代码库。注意到,RNN到处随机生成代码片段和注释。它很少会犯语法错误。比如,它适当的使用了字符类型、指针概念等。同样它正确打开和关闭了代码块{[,并且学习将代码缩进。一处常见的错误就是它不能跟踪变量名:它常常会使用未定义的变量(比如上面出现的rw),或者声明它从来不用的变量(比如上面的int error),或者返回一个不存在的变量。让我们来看看更多的案例。下面是另外一个代码片段,显示了RNN学习操作数组的情况:
/*
* If this error is set, we will need anything right after that BSD.
*/
staticvoidaction_new_function(struct s_stat_info *wb)
{
unsignedlong flags;
int lel_idx_bit = e->edd, *sys & ~((unsignedlong) *FIRST_COMPAT);
buf[0] = 0xFFFFFFFF & (bit << 4);
min(inc, slist->bytes);
printk(KERN_WARNING "Memory allocated %02x/%02x, "
"original MLL instead\\n"),
min(min(multi_run - s->len, max) * num_data_in),
frame_pos, sz + first_seg);
div_u64_w(val, inb_p);
spin_unlock(&disk->queue_lock);
mutex_unlock(&s->sock->mutex);
mutex_unlock(&func->mutex);
return disassemble(info->pending_bh);
}
staticvoidnum_serial_settings(struct tty_struct *tty)
{
if (tty == tty)
disable_single_st_p(dev);
pci_disable_spool(port);
return 0;
}
staticvoiddo_command(struct seq_file *m, void *v)
{
int column = 32 << (cmd[2] & 0x80);
if (state)
cmd = (int)(int_state ^ (in_8(&ch->ch_flags) & Cmd) ? 2 : 1);
else
seq = 1;
for (i = 0; i < 16; i++) {
if (k & (1 << 1))
pipe = (in_use & UMXTHREAD_UNCCA) +
((count & 0x00000000fffffff8) & 0x000000f) << 8;
if (count == 0)
sub(pid, ppc_md.kexec_handle, 0x20000000);
pipe_set_bytes(i, 0);
}
/* Free our user pages pointer to place camera if all dash */
subsystem_info = &of_changes[PAGE_SIZE];
rek_controls(offset, idx, &soffset);
/* Now we want to deliberately put it to device */
control_check_polarity(&context, val, 0);
for (i = 0; i < COUNTER; i++)
seq_puts(s, "policy ");
}
注意到,在第二个函数中,模型进行了这样的比较tty == tty,这是永远成立的。但是,至少这次变量tty只在这个函数中起作用!最后一个函数,注意到代码没有返回任何值,但是这是正确的因为函数的返回值声明成了void。但是,前两个函数同样声明成了void返回类型,却返回了数值。这又是一个由于长期迭代导致的常见错误。
有些时候模型会决定现在是时候产生一个新的文件了。这通常是有趣的部分:首先模型一个一个字符记住GNU许可证,然后include几个头文件,声明一些宏,然后就开始生成代码部分:
/*
* Copyright (c) 2006-2010, Intel Mobile Communications. All rights reserved.
*
* This program is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 as published by
* the Free Software Foundation.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
*
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software Foundation,
* Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
*/
#include <linux/kexec.h>
#include <linux/errno.h>
#include <linux/io.h>
#include <linux/platform_device.h>
#include <linux/multi.h>
#include <linux/ckevent.h>
#include <asm/io.h>
#include <asm/prom.h>
#include <asm/e820.h>
#include <asm/system_info.h>
#include <asm/setew.h>
#include <asm/pgproto.h>
#define REG_PG vesa_slot_addr_pack
#define PFM_NOCOMP AFSR(0, load)
#define STACK_DDR(type) (func)
#define SWAP_ALLOCATE(nr) (e)
#define emulate_sigs() arch_get_unaligned_child()
#define access_rw(TST) asm volatile("movd %%esp, %0, %3" : : "r" (0)); \\
if (__type & DO_READ)
staticvoid stat_PC_SEC __read_mostly offsetof(struct seq_argsqueue, \\
pC>[1]);
staticvoid
os_prefix(unsignedlong sys)
{
#ifdef CONFIG_PREEMPT
PUT_PARAM_RAID(2, sel) = get_state_state();
set_pid_sum((unsignedlong)state, current_state_str(),
(unsignedlong)-1->lr_full; low;
}
这里有太多有趣的地方可以讲述了,关于这部分我可能可以写一篇完整的博客来讲述。但是在这里我就省略这部分了,如果你有兴趣查看,请点击 1MB of sampled Linux code。
生成婴儿的名字
让我们尝试另一件有趣的事情。我们给RNN一个列出8000个婴儿名字的大文本文件,一行一个(包含的名字都在这儿)。我们能将这些输入给RNN然后生成新的名字!这是一些名字的示例,我们展示的都是训练数据中没有的名字(90%都不是训练数据中出现的名字):
Rudi Levette Berice Lussa Hany Mareanne Chrestina Carissy Marylen Hammine Janye Marlise Jacacrie Hendred Romand Charienna Nenotto Ette Dorane Wallen Marly Darine Salina Elvyn Ersia Maralena Minoria Ellia Charmin Antley Nerille Chelon Walmor Evena Jeryly Stachon Charisa Allisa Anatha Cathanie Geetra Alexie Jerin Cassen Herbett Cossie Velen Daurenge Robester Shermond Terisa Licia Roselen Ferine Jayn Lusine Charyanne Sales Sanny Resa Wallon Martine Merus Jelen Candica Wallin Tel Rachene Tarine Ozila Ketia Shanne Arnande Karella Roselina Alessia Chasty Deland Berther Geamar Jackein Mellisand Sagdy Nenc Lessie Rasemy Guen Gavi Milea Anneda Margoris Janin Rodelin Zeanna Elyne Janah Ferzina Susta Pey Castina
如果你想看更多的结果,请点击这儿。我最喜欢的有包括如下几个:"Baby" (haha), "Killie", "Char", "R", "More", "Mars", "Hi", "Saddie", "With" 和 "Ahbort"。很有趣吧。当然,我们能够想象这种功能在写小说的时候或者给一个新公司命名时会发挥奇效J
了解到底发生了什么
我们可以看出,最终训练出的结果是令人印象深刻的,但是这一切都是如何工作的?让我们通过运行两个快速的实验来简要探索下。
训练中样本的演变
首先,探索模型训练过程中样本文本是如何演变的是件有趣的事,比如,我用列夫·托尔斯泰的《战争与和平》训练了一个LSTM网络,然后每100次迭代训练就生成样本。100次迭代后模型生成了随机、混乱的样本:
tyntd-iafhatawiaoihrdemot lytdws e ,tfti, astai f ogoh eoase rrranbyne ‘nhthnee e
plia tklrgd t o idoe ns,smtt h ne etie h,hregtrs nigtike,aoaenns lng
但是,注意到模型最少知道了要在每个“单词”间加上空格。有些时候会加上两个空格。同样模型不知道逗号后面通常跟着空格。300次迭代后我们可以看到模型开始有了引号和句号的概念:
"Tmont thithey" fomesscerliund
Keushey. Thom here
sheulke, anmerenith ol sivh I lalterthend Bleipile shuwy fil on aseterlome
coaniogennc Phe lism thond hon at. MeiDimorotion in ther thize."
这次单词之间同样由空格隔开,而且模型开始知道在句子末尾加上句号。500次迭代:
we counter. He stutn co des. His stanted out one ofler that concossions and was to gearang reay Jotrets and with fre colt otf paitt thin wall. Which das stimn
现在模型会拼写最短、最常见单词,比如“we”,“He”,“His”,“Which”,“and”等。700次迭代的时候,我们得到了更像英语的文本:
Aftair fall unsuch that the hall for Prince Velzonski‘s that me ofher hearly, and behs to so arwage fiving were to it beloge, pavu say falling misfort how, and Gogition is so overelical and ofter.
在经过1200次迭代后,我们发现模型开始使用引号和问号/感叹号了,与此同时也学会了更长的单词:
"Kite vouch!" he repeated by her
door. "But I would be done and quarts, feeling, then, son is people...."
经过2000次迭代,模型能够正确拼写的单词,引号,名字等:
"Why do what that day," replied Natasha, and wishing to himself the fact theprincess, Princess Mary was easier, fed in had oftened him.Pierre aking his soul came to the packs and drove up his father-in-law women.
大体上我们可以这么认为,首先模型发现了单词-空格这样普遍的结构,然后迅速学会拼写单词;从学习拼写简单单词开始到最后学习拼写长单词。在单词中显现出主题内容(一般依赖于长期性)在很多次迭代后才出现。
RNN预测结果和神经元激活可视化
可视化有趣的另一个方面是可以按字符来观察预测分布。在下面的可视化图中,我们向Wikipedia RNN模型中输入了校验好的数据集(蓝色/绿色的行)中的字符,然后在每个字符下面,我们列出了(红色部分)模型预测会出现的前5个字符,颜色深浅根据它们概率大小决定(深红:预测准确,白色:不准确)。比如,注意到有一连串字符是模型非常有信心能够预测准确的(对http://www.序列模型置信度非常高)。
输入字符序列(蓝色/绿色)的颜色取决于RNN隐藏层中随机选择的神经元的激活情况。定义绿色=非常兴奋,蓝色=不是那么兴奋(对于那些熟悉LSTMs细节的人来说,这些就是隐藏向量中[-1,1]范围内的值,也就是经过门限操作和tanh函数的LSTM单元状态)。直观的,下图显示了在RNN“大脑”读取输入序列时一些神经元的激活情况。不同的神经元可能有不同的模式;下面我们将会看到我找到的4个不同的神经元,我认为这几个是有趣的,并且是可解释的(许多其他的并不容易解释):

此图中高亮的神经元似乎对URL极度兴奋,URL以外的地方就不那么兴奋。LSTM似乎会用这种神经元来记住它是否在URL之中。

在这张图中,当RNN在[[]]标记之中时,高亮的神经元表现极度兴奋,所以在这种标记之外就没那么兴奋,在神经元碰到字符“[”的时候不会表现得兴奋,它一定要等到出现第二个“[”才会激活。计算模型是否碰到了一个还是两个“[”的任务似乎可以用一个不同的神经元完成。

在这里,我们可以看出在[[]]环境中,神经元有着线性的变化。换句话说,它的激活函数给了RNN中[[]]范围的一种基于时间的坐标系统。RNN可以通过这些信息或多或少的依赖于字符在[[]]中出现的早/晚来生成不同的字符(有可能是这样)。

这是另外一个神经元,它有着更个性化的行为:它整体上比较平淡无常,但是碰到“www”中第一个“w”的时候突然就开始变得兴奋。RNN可能可以使用这种神经元来计算“www”序列的长度,这样它就知道是否应该再添加一个“w”还是开始添加URL。
当然,由于RNN隐藏状态的庞大性,高维度性和分布式特性,很多这样的结论都稍微要加上特别说明才能理解。这些可视化效果通过定制的html/CSS/javascript生成,如果你想做一些相似的功能,你可以从这儿查看设计的构架。
我们也可以通过排除最接近的预测项和仅可视化通过细胞单元激活而被上色的文本使可视化效果得以压缩。我们可以发现大部分细胞单元不发生可中断现象,但大约有5%最后习得了很有趣的可中断算法。
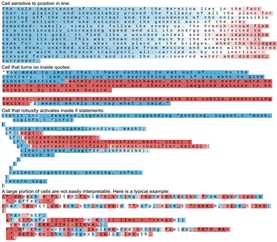


又一次地,让人感到美妙的是当我们在预测下一个可能的字符时,我们不是必须对任何的点都使用硬解码,例如当我们在跟踪你是否正在引文之中时。我们刚刚在LSTM上训练了未加工的数据并且这决定了对于跟踪有意义的量。换言之,在训练中,一个细胞单元逐渐使自己变成引文的检测细胞单元,因为这样的话这对于实现最终的任务有帮助。这正是一个最简明清晰的展现深度学习模型(更广义的讲,即点对点的训练)的力量之源。
源代码
我希望通过我上面的讲述,你会觉得训练一个字符级语言模型是一次有趣的练习。你可以使用我在Github(拥有MIT许可)上发布的 char-rnn code 来训练你自己的模型。它将大量文本文件作为输入,训练出一个字符级模型,然后你就可以从中得到样本文件。同时,如果你有一个GPU的话会对你有所帮助,否在在CPU上训练的话会花大约10多倍的时间。不管怎样如果你完成了训练并且得到了有趣的结果,请告知我!如果你在使用Torch/Lua代码库的时候碰到困难,请记住,这只是 100-line gist 的一个版本。
一些题外话。代码是由 Torch7 编写的,它最近成了我最喜欢的深度学习框架。我是最近几个月才开始使用Torch/Lua的,它们并不简单(我花了大量时间来阅读Github上Torch源码,向它的发布者提问才掌握它),但是一旦你掌握了足够的知识,它就会给你带来很大的灵活性和速度提升。我以前同样使用过Caffe和Theano,我认为Torch并不完美,但是它的抽象层次和原理比其他的要优秀。在我看来,一个有效框架应该具有以下功能:
1. 有许多功能(slicing,array/matrix等操作)的CPU / GPU透明的Tensor库。
2. 一个完全独立的代码库,它基于脚本语言(最好是 Python),工作在Tensors上,实现了所有深度学习方面的东西(前馈/后馈,图形计算等)。
3. 它应该可以轻松共享预训练模型(Caffe在这方面做的很好,其他几个则存在不足),这也是至关重要的。
4. 没有编译过程(或者说不要像Theano目前那样做)。深度学习是朝着更大更复杂的网络发展,所以在复杂图算法中花费的时间会成倍增加。重要的是,长时间或者是在开发阶段不进行编译所带来的影响是非常巨大的。而且,进行编译的话就会丢失可解释性和有效进行日志记录/调试的能力。如果为提高效率在图算法开发好后立即编译,那么这样做是可取的。
延伸阅读
在结束这篇文章之前,我还想再介绍更多关于RNNs的东西,并大致提供目前的研究方向。最近在深度学习领域,RNNs颇受欢迎。和卷积网络一样,它们已经存在了几十年,但它们的潜力最近才开始得到广泛的认可,这在很大程度上是因为我们不断增长的计算资源。下面是一些最近事态发展的简要介绍(这绝对不是完整的列表,很多这样的工作让研究界好像回到了上世纪90那种研究热潮,来看看相关的工作部分):
在NLP/语音领域,RNNs将 语音转录成文本 ,使用 机器翻译 , 生成手写文本 ,当然,它们已经被用来当做强大的语言模型( Sutskever等人 )( Graves )( Mikolov等人 )(都是在字符和单词层面)。目前看来,单词级的模型比字符级的模型要更好,但这肯定是暂时的。
计算机视觉。在计算机视觉方面,RNNs也很快成为了无处不在的技术。比如,我们会见到RNNs在帧层面 分类视频 , 添加图片字幕 (同样包括我和其他人的工作), 添加视频字幕 ,最近又用来 视觉问答 。我个人最喜欢的RNNs计算机视觉方面的论文是 Recurrent Models of Visual Attention ,这是因为它有着高层次方向特性(glance顺序处理图像)和低层次建模(REINFORCE学习规定它是强化学习中一个特定的梯度方法,可以训练出进行不可微计算的模型(以图像周边glance处理为例))。我相信,这种混合模型类型——由CNN形成的原始感知器再加上RNN glance策略,将会在感知器中普遍存在,特别是对于比分类更复杂的任务。
归纳推理,存储和关注模块。另一个非常令人兴奋的研究方向是面向解决Vanilla递归网络的局限性。它的一个问题是RNNs不是数学归纳的:它们能够非常好的记住序列,但是并不一定总能够得到正确的结果(我会举几个例子来具体说明)。第二个问题是,它们不必每步都将代表大小和计算数量结合起来。具体来说,如果你把隐藏状态向量的大小增加一倍,由于矩阵乘法,每步中FLOPS的数量会变成原来的四倍。理想情况下,我们想保持庞大的代表性/存储(比如,包含维基百科所有的内容或者多个中间状态变量),而同时保持计算的每个时间步长固定的能力。
在这些方向上,第一个有说服力的例子在DeepMind上的 Neural Turing Machines 这篇论文中讲述了。这篇论文描述了在计算开始时,模型在大的、外部的存储阵列和更小寄存器之间执行读写操作的方法(把它想象成是你自己的工作存储器)。至关重要的是,这篇论文也同样介绍了有趣的内存寻址机制,这是用一个(平缓的,完全可微的)关注模块实现的。平缓关注模块的概念是一个强大的建模特征,同时也是 Neural Machine Translation by Jointly Learning to Align and Translate 这篇文章再机器翻译上的一大特色,网络存储则用来问答。事实上,我不得不说:
关注模块的概念在最近的神经网络架构创新中是最有趣的。
现在,我不想讲太多的细节,但是内存寻址的平缓关注模块机制是非常方便的,因为它让模型完全可微,但不幸的是,这会牺牲一些效率,因为所有可以被关注的都被关注了(平缓的)。你可以把它想象成C语言中的指针,它不指向具体的地址,而是定义了在整个内存中分布的所有地址,并将指针返回的所指向内容的加权总和值非关联化(这个操作代价会很大!)。这促使多位作者在给多块内存进行关注操作的时候使用平缓关注方式而不是猛烈关注方式(比如,对某些内存单元进行读取操作,而不是从内存单元中读出/写入到某些地方)。这种模型有着更显著的哲学吸引力,可扩展性和高效率性,但是不幸的是,它是不可微的。这就要使用强化学习文献(比如REINFORCE)中使用到的技术来解决,人们将它完美地用于不可微的模型之中。这是正在进行的工作,但是针对这些困难的关注模型进行了探讨,你可以在 Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets ,Reinforcement Learning Neural Turing Machines , Show Attend and Tell 这几篇论文中了解到。
人物。如果你愿意阅读我推荐的 Alex Graves , Ilya Sutskever 和 Tomas Mikolov 所写的文章。你可以从 David Silver 或 Pieter Abbeel 的公开课中了解到更多的关于REINFORCE,强化学习和策略梯度方法的知识。
代码。如果你想实践实践训练RNNs,我推荐你使用Theano的 keras 和 passage ,也可以使用连同这篇文章一同发布的Torch 代码 ,或者使用我先前写好的numpy源代码 要点 ,它实现了一个有效率的、批量处理的LSTM前馈和后馈处理。你也可以看看我基于numpy的 NeuralTalk ,它用了RNN/LSTM来给图片加字幕,或者你可以使用Jeff Donahue写的 Caffe 。
总结
我们已经学习了RNNs是如何工作的,它们为什么变得至关重要,我们在几个有趣的数据集上训练了一个字符级的RNN模型,并且我们看到了RNNs的执行情况。你完全可以毫无顾忌的用RNNs进行大量创新,并且我相信它们会在智能系统中成为一种普遍存在并且至关重要的组成部分。
最后,在这篇文章中加上一些元数据,我用这篇文章的源文件训练了一个RNN。不幸的是,我只有46K的字符,没有足够的字符给RNN,但是返回的样本(使用低温度以得到更典型的样本)如下所示:
I‘ve the RNN with and works, but the computed with program of the RNN with and the computed of the RNN with with and the code
好了,这篇文章是讲述关于RNN和它工作状况的,很明显它工作良好 :)。我们下回见!
EDIT (extra links):
Videos:
· I gave a talk on this work at the London Deep Learning meetup (video).
Discussions:
· Reddit discussion on r/machinelearning
· Reddit discussion on r/programming
Replies:
· Yoav Goldberg compared these RNN results to n-gram maximum likelihood (counting) baseline
· @nylk trained char-rnn on cooking recipes. They look great!
· @MrChrisJohnson trained char-rnn on Eminem lyrics and then synthesized a rap song with robotic voice reading it out. Hilarious :)
· @samim trained char-rnn on Obama Speeches. They look fun!
· João Felipe trained char-rnn irish folk music and sampled music
· Bob Sturm also trained char-rnn on music in ABC notation
· RNN Bible bot by Maximilien
· Learning Holiness learning the Bible
· Terminal.com snapshot that has char-rnn set up and ready to go in a browser-based virtual machine (thanks@samim)
部分翻译和整理:[email protected]
本文绝大部分翻译来自于http://blog.csdn.net/memray/article/details/48652647 译者/刘翔宇审校/刘帝伟、朱正贵、李子健责编/周建丁
本文原文链接为http://karpathy.github.io/2015/05/21/rnn-effectiveness/
原作者:Andrej Karpathy