Win7 单机Spark和PySpark安装
Posted 见贤思小齐,知足常乐呵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Win7 单机Spark和PySpark安装相关的知识,希望对你有一定的参考价值。
欢呼一下先。软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了。加油加油!!!
1. 安装方法参考:
已安装Pycharm 和 Intellij IDEA。
win7 PySpark 安装:
http://blog.csdn.net/a819825294/article/details/51782773
win7 Spark安装:
http://blog.csdn.net/a819825294/article/details/51627083
2. 遇到的那些问题:
1) Scala 需要安装两次:
Scala 本地安装,然后配置环境。在cmd 输入 scala 验证是否成功。
Intellij IDEA 安装scala插件。
2) 提示 no Module SDK for Scala
no Module SDK for Scala (in IntelliJ Idea)
方案:点击该提示,选择download SDK 添加即可。
3)
15/05/27 11:20:53 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(lenovo); users with modify permissions: Set(lenovo) Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
Scala 和 Spark BAN版本不兼容的问题。
方案:重新下载安装Scala.
4)
Exception in thread "main" java.lang.ClassNotFoundException: WordCount
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.deploy.SparkSubmit$.launch(SparkSubmit.scala:289)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:55)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
方案: 确认一下路径是否正确,以及类的大小写是否有误。
5)
14/07/02 19:59:31 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/07/02 19:59:31 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\\bin\\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:318) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:333) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:326) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76) at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:93) at org.apache.hadoop.security.Groups.<init>(Groups.java:77) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:240) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:255) at org.apache.hadoop.security.UserGroupInformation.setConfiguration(UserGroupInformation.java:283) at org.apache.spark.deploy.SparkHadoopUtil.<init>(SparkHadoopUtil.scala:36) at org.apache.spark.deploy.SparkHadoopUtil$.<init>(SparkHadoopUtil.scala:109) at org.apache.spark.deploy.SparkHadoopUtil$.<clinit>(SparkHadoopUtil.scala) at org.apache.spark.SparkContext.<init>(SparkContext.scala:228) at org.apache.spark.SparkContext.<init>(SparkContext.scala:97)
方案:
下载 winutils.exe 文件,然后设置环境变量
intellij IDEA 版 Scala:
System.setProperty("hadoop.home.dir","E:\\\\zhuangji\\\\winutil\\\\")
Pycharm 版Python:
import os os.environ["HADOOP_HOME"]="E:\\\\zhuangji\\\\winutil\\\\"
当然也可以在计算机---〉右键属性--〉环境变量。。。
但是不知道即使重启了计算机还是依然报错。最后在代码中设置环境变量,问题解决。
6)按照3的步骤重新安装后还是同样的错误。
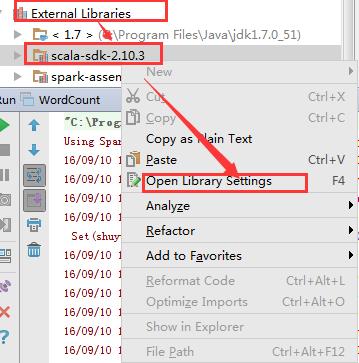
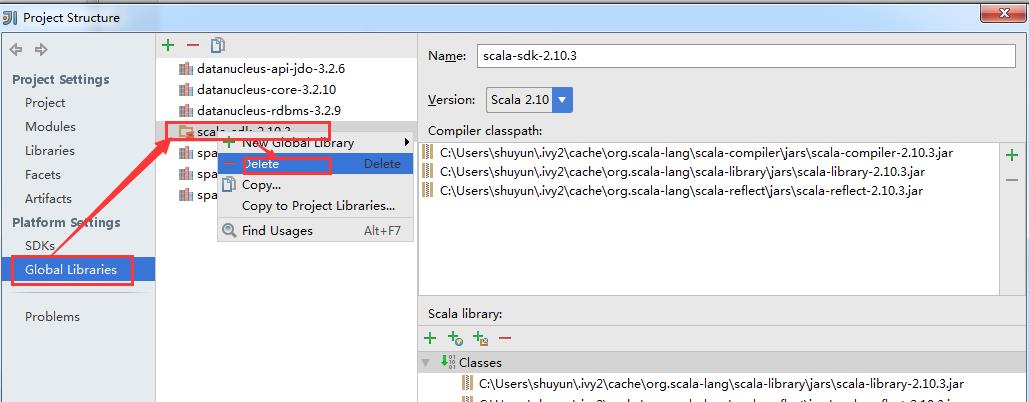
检查后发现,Intellij IDEA的library中出现多个版本的Scala, 显然新安装的Scala 并未取代旧的Scala.
需要删除旧的scala。
以上是关于Win7 单机Spark和PySpark安装的主要内容,如果未能解决你的问题,请参考以下文章
spark 集群处理后转单机pyspark 或 pands 数据处理 的方法