错题纠正
Posted 美味的你
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了错题纠正相关的知识,希望对你有一定的参考价值。

此题目考查的是对Hibernate中交叉连接的理解。HQL支持SQL风格的交叉连接查询,交叉连接适用于两个类之间没有定义任何关联时。在where字句中,通过属性作为筛选条件,如统计报表数据。使用交叉连接时应避免“from Dept,Emp”这样的语句出现。执行这条HQL查询语句,返回DEPT表和EMP表的交叉组合,结果集的记录数为两个表的记录数之积,也就是数据库中的笛卡尔积。这样的查询结果没有实际意义,因此选项b是正确的。A和C答案都是符合上述描述的,是适合使用交叉连接的场合。D答案认为以上三种都适合,与上述描述冲突。由于题目要求选择不适合使用交叉连接的选项,因此选项B、C、D是错误的。

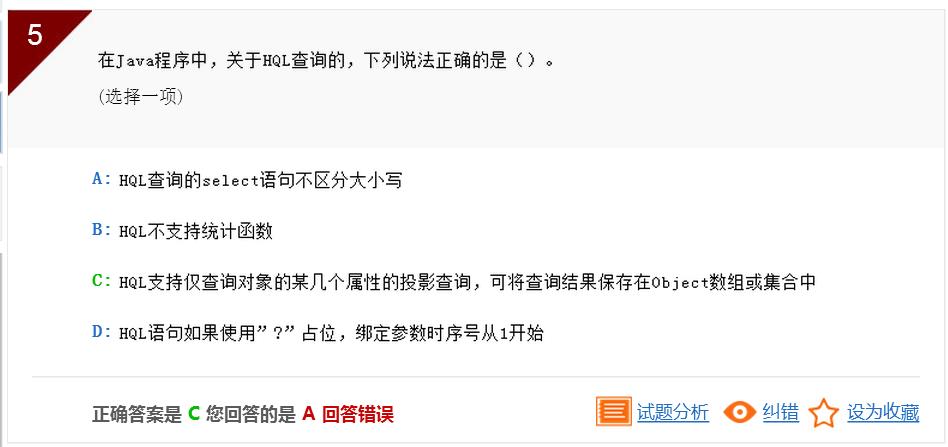
本题考核的是Hibernate-HQL查询中的HQL概述。答案A中,HQL的select语句中的类名和属性名是区分大小写的;答案B中,HQL是支持统计函数的;答案D中,绑定参数的序号从0开始。所以ABD都不正确,只有C是正确的。因此答案是c。
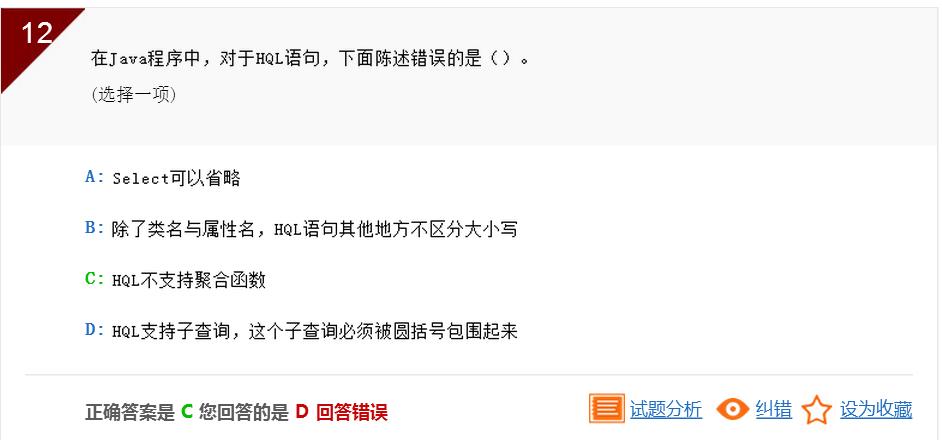
此题考查的是:HQL查询语句,及HQL语句的别名的命名规则,答案A中,select可以省略,是正确的;答案B中,表达的也是正确的;答案C中,HQL是支持聚合函数的,所以C的表达式错误的;答案D中,表达的也是正确的。本题选择的是错误的表达,所以ABD都不符合,只有C符合。因此答案是c。
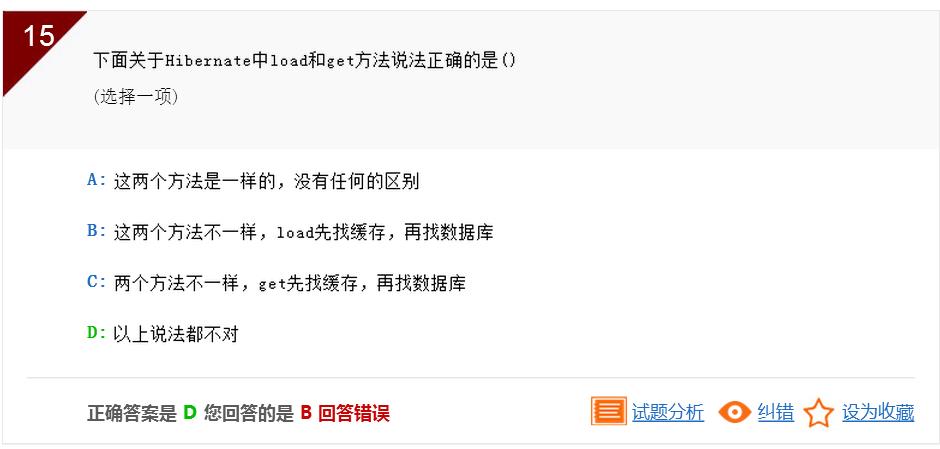
load()和get()都是先找缓存,再找数据库。 不同点是在检索时: load()是延迟检索,先返回代理对象,访问对象时在发出sql命令 Get()是立即检索,直接发出sql命令,返回对象 因此abc都是错误的,d是正确答案

one-to-one配置的查询,必须查询到另一个实体
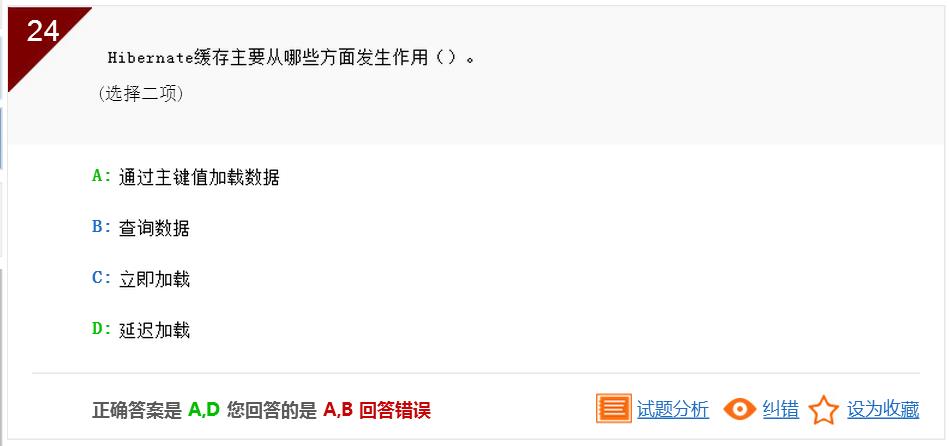

此题考查的是各种连接的效果 因为如 A right join B 即取出B表的所有数据,由on条件关联的A表数据,有则显示,没有则为空;所以B错;

此题目考查的是对Hibernate中迫切连接的简单应用。Hibernate中的迫切连接是通过fetch关键字实现的,fetch关键字表明“左边”对象用于与“右边”对象关联的属性会立即被初始化,但可能会有一些重复的“左边”对象。在一个Dept部门下有多个Emp员工的情况下,左外连接使用一个部门匹配一个员工的方式返回结果,因此造成结果集中出现重复的Dept部门对象的情况,因此选项B是正确的。A答案中的异常可能在session对象为null的情况下抛出,但题目的假设是session对象是正常开启的并且未关闭,再者,就算是hql语句没有查到结果,query.list方法也不会抛出NullPointerException异常,因此选项A是错误的。C答案是对迫切连接的原理理解不透彻造成的,迫切连接返回的List会采用“左边”对象的泛型,而不是Object[],因此选项C是错误的。D答案只考虑了简单的情况,在简单情况下,即一个部门只有一个员工的情况,题目代码是没有问题的。但是考虑到一个Dept部门下有多个Emp员工的情况,题目代码会返回包含重复Dept对象的List集合,因此,因此选项D是错误的。

此题目考查的是Hibernate连接查询类型的掌握。 inner join [fetch]为内连接的语法,left [outer] join 为左外连接的语法,right [outer] join为左外连接的语法,[inner] join fetch为迫切内连接的语法,所以本题正确选项是C。

本题考查的是HQL内连接与迫切内连接的区别。选项A的说法不正确,因为只有迫切内连接才会立即加载连接数据,普通内连接在初始化时set集合并不会立即加载数据。 选项B的说法是正确的,emps集合不会被初始化。选项C的说法也是正确的,第二句是迫切内连接,所以数据会立即加载。选项D是误导选项。
此题目考查的是Hibernate关系映射的使用。每个人有不同的名字这说明是一对一的关系人和人名不重复,多个人可以是同一个名字为对第一的关系。所以本题正确选项是AC。

此题目考查的是对Hibernate中隐式和显示内连接的简单应用。在HQL查询语句中,如果通过对Emp类赋别名“e”,可以通过e.dept.dname的形式访问dept对象的dname属性,使用隐式内连接按部门条件查询员工信息,因此选项B是正确的。另外也可以显式使用inner join关键字内连接e.dept对象,因此选项C也是正确的。A答案中虽然使用了inner join关键字,但是连接对象使用不正确,这样做会导致“could not found the property Dept of Emp”的错误,即在Emp类中找不到叫作Dept的属性。原因是Hibernate是一款基于ORM的解决方案,在HQL语句执行之前已经对表和持久化对象作了映射,Hibernate只知道Emp中有dept属性,而不知道Dept,因此选项A是错误的。B答案是照搬SQL语句的写法,该写法用在HQL中会导致将“研发部”这个部门对象与每一个Emp员工对象匹配的结果,总记录数等于Emp员工的记录数,因此选项B是错误的。
此题目考查的是Hibernate查询缓存适用的场合,对于经常使用的查询语句,如果启用了查询缓存,当第一次执行查询语句时,Hibernate会把查询结果存放在第二缓存中。以后再次执行该查询语句时,只需从缓存中获得查询结果,从而提高查询性能。所以本题正确选项是AB。

此题目考查的是对缓存的理解,查询少,变更多时,使用缓存反而会降低性能,所以a、b错误。如果按照id查询,可在id列上增加索引,但如果对每一列都增加索引可能会降低插入和修改性能,因此d错误。应选择c
以上是关于错题纠正的主要内容,如果未能解决你的问题,请参考以下文章