Python全栈--7.3--模块补充configparser--logging--subprocess--os.system--shutil
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python全栈--7.3--模块补充configparser--logging--subprocess--os.system--shutil相关的知识,希望对你有一定的参考价值。
模块补充:
一、configparser用于处理特定格式的文件,其本质是利用open来操作文件
继承到2版本 configparser 实现了更多智能特征,更有壳预见性,新的应用更偏好这个版本,
处理 配置文件类似如下:


# 注释1 ; 注释2 [section1] k1 = v1 # 值 k2 = v2 # 值 [section2] k1 = v1 # 值 [mysql] client_ip = 10.0.0.1 port = 4444 [mysqld] server_ip = 10.0.0.3 port = 3306 [liujianzuo2]
1、获取所有的节点
import configparser obj = configparser.ConfigParser() # 创建编辑对象 obj.read("ini",encoding="utf-8") #读取 文件 ret = obj.sections() # 选项 print(ret)
2、获取指定节点下的所有的键值对
import configparser # 获取指定节点下的键值 obj = configparser.ConfigParser() # 创建编辑对象 obj.read("ini",encoding="utf-8") #读取 文件 ret = obj.items("mysql") # 键值 # [(\'client_ip\', \'10.0.0.1\'), (\'port\', \'3306\')] print(ret)
3、获取指定节点下的所有的键
import configparser obj = configparser.ConfigParser() # 创建编辑对象 obj.read("ini",encoding="utf-8") #读取 文件 ret = obj.options("mysql") # 选项下的key [\'client_ip\', \'port\'] print(ret)
4、获取指定节点下指定key的值
#获取指定节点下的值 obj = configparser.ConfigParser() # 创建编辑对象 obj.read("ini",encoding="utf-8") #读取 文件 ret = obj.get("mysql","client_ip") # 选项下的key 10.0.0.1 # ret = obj.getint("mysql","client_ip") # 选项下的key 10.0.0.1 # ret = obj.getfloat("mysql","client_ip") # 选项下的key 值为float类型 # ret = obj.getboolean("mysql","client_ip") # 选项下的的所有key必须都是布尔类型 print(ret)
# ret = obj.getfloat("mysql","client_ip") # 选项下的key 值为float类型
# ret = obj.getboolean("mysql","client_ip") # 选项下的的所有key必须是布尔类型
5、检查删除添加节点
import configparser # 检查 删除 添加节点 obj = configparser.ConfigParser() # 创建编辑对象 obj.read("ini",encoding="utf-8") #读取 文件 # 检查 has_sec = obj.has_section("mysql1") # false print(has_sec) # 添加节点 obj.add_section("liujianzuo") obj.add_section("liujianzuo1") obj.add_section("liujianzuo2") obj.write(open("ini","w",encoding="utf-8")) # [\'section1\', \'section2\', \'mysql\', \'mysqld\', \'liujianzuo\', \'liujianzuo1\', \'liujianzuo2\'] obj.read("ini",encoding="utf-8") ret = obj.sections() print(ret) # 删除节点 obj.remove_section("liujianzuo") obj.remove_section("liujianzuo1") obj.write(open("ini","w",encoding="utf-8")) # [\'section1\', \'section2\', \'mysql\', \'mysqld\', \'liujianzuo2\'] obj.read("ini",encoding="utf-8") ret = obj.sections() print(ret)
6、检查、删除、设置指定的组内的键值对
import configparser # 检查 删除 添加 指定组内的键值对 obj = configparser.ConfigParser() # 创建编辑对象 obj.read("ini",encoding="utf-8") #读取 文件 # 检查 has_opt = obj.has_option("mysql","port") print(has_opt) # 删除 obj.remove_option("mysql","port") obj.write(open("ini","w",encoding="utf-8")) ret = obj.sections() print(ret) # # 设置 obj.set("mysql","port","4444") obj.write(open("ini","w",encoding="utf-8")) ret = obj.values() print(ret)
二、shutil
高级的 文件 文件夹 压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutil shutil.copyfileobj(open(\'old.xml\',\'r\'), open(\'new.xml\', \'w\'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile(\'f1.log\', \'f2.log\')
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode(\'f1.log\', \'f2.log\')
shutil.copystat(src, dst)
拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat(\'f1.log\', \'f2.log\')
shutil.copy(src, dst)
拷贝文件和权限
import shutil shutil.copy(\'f1.log\', \'f2.log\')
shutil.copy2(src, dst)
拷贝文件和状态信息
import shutil shutil.copy2(\'f1.log\', \'f2.log\')
以上的方法练习
import shutil # shutil.copyfileobj(open(\'log.log\',\'r\'), open(\'a/a\', \'w\')) #将文件内容拷贝到另一个文件中 # shutil.copyfile(\'first.xml\', \'a/a\') # 拷贝文件 first.xml ===> a/a # shutil.copymode(\'first.xml\', \'a/a\') # 仅拷贝权限。内容、组、用户均不变 # shutil.copystat(\'first.xml\', \'a/a\') # 拷贝状态的信息,包括:mode bits, atime, mtime, flags # shutil.copy(\'log.log\', \'a/a\') # 拷贝文件和权限 # shutil.copy2(\'first.xml\', \'a/a\') # 拷贝文件和状态信息
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
# shutil.copytree(\'folder1\', \'folder2\', ignore=shutil.ignore_patterns(\'*.pyc\', \'tmp*\')) # 将folder1下的内容 复制到folder2下面 注意 folder2 必须不存在
# 例子
# import os,sys
# shutil.copytree(os.path.dirname(__file__),os.path.dirname(__file__)+"/c",ignore=shutil.ignore_patterns(\'*.py\',"*.pyc", \'l*\',"*.xml"))
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutil shutil.rmtree(\'folder1\') # import os,sys # shutil.rmtree(os.path.dirname(__file__)+"/c") # 删除 c目录 类似 rm -fr 不存在目录则报错
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
import shutil
shutil.move(\'folder1\', \'folder3\')
# shutil.move("c","b1") # 剪切c目录到b目录下 ,src即c目录不存在则报错 ,dst即b目录不存在就是重命名
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("wwwwwwwwww", \'gztar\', root_dir=\'/Users/wupeiqi/Downloads/test\')
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录
import shutil
ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", \'gztar\', root_dir=\'/Users/wupeiqi/Downloads/test\')
# import os,sys
# shutil.make_archive("my_bak","gztar",root_dir=os.path.dirname(__file__)+"/b1")
# shutil.make_archive(os.path.dirname(__file__)+"/a/my_bak","gztar",root_dir=os.path.dirname(__file__)+"/b1")
#
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
import zipfile # 压缩 # z = zipfile.ZipFile(\'laxi.zip\', \'w\') # z.write(\'log.log\') # z.write(\'first.xml\') # z.close() # 添加一个文件 # z = zipfile.ZipFile(\'laxi.zip\', \'a\') # z.write(\'first1.xml\') # z.write(\'a/a\') # 将a目和其下面的a文件一同录压缩到里面 如果存在会保存,但是仍然压缩进入 # z.write(\'b/c\') # 将b目录和其下面的c文件一同压缩到里面 # z.write(\'b/b\') # 将b目录和其下面的c文件一同压缩到里面 # z.close() # 解压 # z = zipfile.ZipFile(\'laxi.zip\', \'r\') # z.extractall("log.log") # 解药所有文件到log.log目录 # z.extract("log.log") # 解压单个文件log.log到当前目录 文件如果存在也无报错 # z.extract("first.xml") # 解压单个文件log.log到当前目录 文件如果存在也无报错 # z.close()
import tarfile,os # 压缩 # tar = tarfile.open("your.tar",\'w\') # 已存在不报错 # tar.add(os.path.dirname(__file__),arcname="nonosd") #将前面的目录重新改名为nonosd目录名 归档到your.tar中 # tar.add("first.xml",arcname="first.xml") #将前面的目录重新改名为nonosd目录名 归档到your.tar中 # tar.close() # tar = zipfile.ZipFile(\'laxi.zip\', \'a\') # tar.write(\'first1.xml\') # tar.write(\'a/a\') # 将a目和其下面的a文件一同录压缩到里面 如果存在会保存,但是仍然压缩进入 # tar.write(\'b/c\') # 将b目录和其下面的c文件一同压缩到里面 # tar.write(\'b/b\') # 将b目录和其下面的c文件一同压缩到里面 # tar.close() # 压缩 tar = tarfile.open(\'your.tar\',\'r\') # print(tar.getmembers()) print(tar.getnames()) #查看所有的文件名 tar.extract(\'first.xml\') #解压单个文件 tar.extractall(path="a/") # 解压所有到 path tar.close()
linux下的 压缩 和 归档
压缩工具:
zip: 解压缩 #可以压缩目录 不会归档链接文件
windows直接就指出
zip filename.zip srcfilename
unzip filename.zip #保留原文件
zip dir.zip dir
zip dir.zip dir/* 解压的话会自动创建目录
gzip:压缩 gunzip:=gzid -d 解压 #不能压缩目录 #所有先归档打包成一个文件再压缩
zcat:查看压缩包文件,会放到临时目录,关闭就删了
gzip:
-c :输出流改变,默认送往标准输出即屏幕,可以使用重定向将其保存为压缩文件 可以保留源
gzip -c file > file.gz
bzip:压缩 bunzip2:=bzip -d 解压 #不能压缩目录 #所有先归档打包成一个文件再压缩
bzcat : 查看压缩包文件,会放到临时目录,关闭就删了
格式:bz2
-k :保留原文件
xz:压缩 unzx:=xz -d 解压 #压缩性能更好 查看压缩包文件,会放到临时目录,关闭就删了
xz #不能压缩目录 #所有先归档打包成一个文件再压缩
格式 .xz
共有参数
-num:指定压缩比 1-9 如果不指 ,默认是6 越大压缩比越大月消耗cpu性能
bzip 跟gzip 不同的压缩算法,bzip比gzip压缩大文件更小,但是可能压缩小文件更大
归档工具: #即多个文件规程一个文件 即打包
tar #f必须在最后 不要随意调换次序,f 后必须是归档压缩文件名
tar [ options ] -f file.tar FLIE1,FILE2,FILE3...,
-c: 创建归档
-x:展开归档
-t :查看归档tar文件的内容如果是目录则看到文件列表 不展开而直接查看被归档的文件
压缩参数:
-z:调用用gzip
tar -zcf dir.tar.gz dir
tar -zxf dir.tar.gz
-j:调用bzip
tar -zcf dir.tar.bz2 dir
-J :调用 xz
tar -Jcf dir.tar.xz dir
归档: tar -fc dir.tar dir
此时合一压缩
xz dir.tar #比例特别高
unxz dir.tar.xz #解压为dir.tar
还原归档:-x
不管是什么压缩的归档文件,我们直接 tar xf 即可
tar xf dir.tar.{gz|bz2|xz}
三、系统命令
可以执行shell命令的相关模块和函数:
- os.system
- os.spawn*
- os.popen* --废弃
- popen2.* --废弃
- commands.* --废弃,3.x中被移除
import commands result = commands.getoutput(\'cmd\') result = commands.getstatus(\'cmd\') result = commands.getstatusoutput(\'cmd\')
以上执行shell命令的相关的模块和函数的功能均在 subprocess 模块中实现,并提供了更丰富的功能。
call
执行命令,返回状态码
ret = subprocess.call(["ls", "-l"], shell=False)
ret = subprocess.call("ls -l", shell=True)
check_call
执行命令,如果执行状态码是 0 ,则返回0,否则抛异常
import subprocess
ret = subprocess.check_output("ipconfig") # 默认返回是字节类型
print(str(ret,encoding="gbk")) # windows下是gbk
subprocess.Popen(...)
用于执行复杂的系统命令
参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 - shell:同上
- cwd:用于设置子进程的当前目录 即 你执行命令的工作目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用 \\n
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
执行普通命令:
import subprocess
ret1 = subprocess.Popen(["mkdir","t1"])
ret2 = subprocess.Popen("mkdir t2", shell=True)
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
切换到其他的工作目录进行命令操作
import subprocess
obj = subprocess.Popen("mkdir t3", shell=True, cwd=\'/home/dev\',)
执行交互命令,运用标准输入 输出 错误输出 管道获取相应的结果
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
obj.stdin.write("print(1)\\n")
obj.stdin.write("print(2)")
obj.stdin.close()
cmd_out = obj.stdout.read()
obj.stdout.close()
cmd_error = obj.stderr.read()
obj.stderr.close()
print(cmd_out)
print(cmd_error)
交互命令 communicate 获取所有的结果
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
obj.stdin.write("print(1)\\n")
obj.stdin.write("print(2)")
out_error_list = obj.communicate()
print(out_error_list)
扩展
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
out_error_list = obj.communicate(\'print("hello")\')
print(out_error_list)
四、logging
用于便捷记录日志且线程安全的模块
1、单文件日志
import logging
logging.basicConfig(filename=\'log.log\',
format=\'%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s\',
datefmt=\'%Y-%m-%d %H:%M:%S %p\',
level=10)
logging.debug(\'debug\')
logging.info(\'info\')
logging.warning(\'warning\')
logging.error(\'error\')
logging.critical(\'critical\')
logging.log(10,\'log\')
日志等级:
CRITICAL = 50 FATAL = CRITICAL ERROR = 40 WARNING = 30 WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0
注:只有【当前写等级】大于【日志等级】时,日志文件才被记录。
日志记录格式:
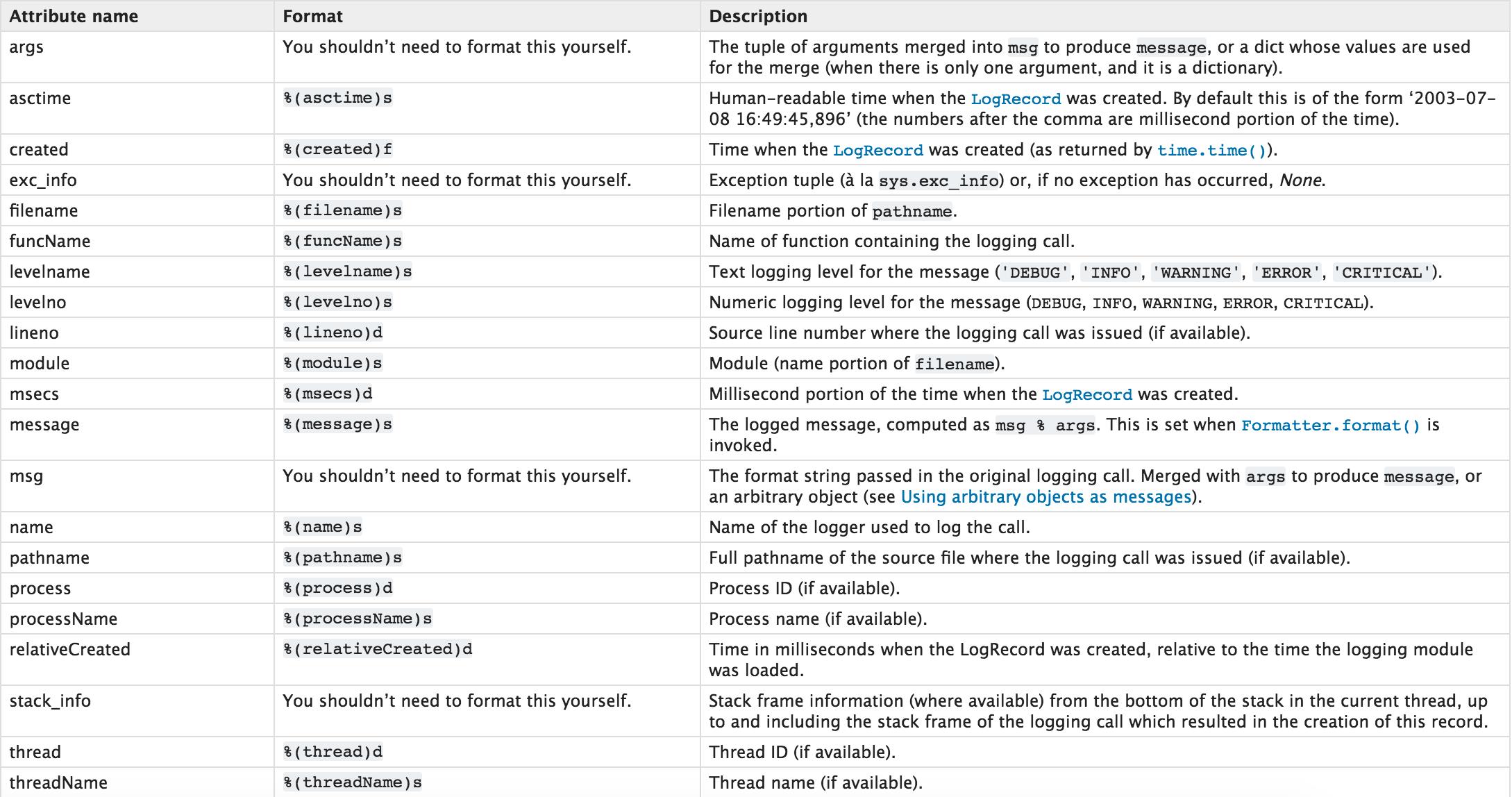
多文件写入日志的处理格式addHandler;
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import logging
#1 创建文件
file_1_1 = logging.FileHandler("l1_1.log","a")
# 创建格式
fmt = logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s")
# 文件应用格式
file_1_1.setFormatter(fmt)
file_1_2 = logging.FileHandler("l1_2.log","a")
fmt = logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s")
file_1_2.setFormatter(fmt)
logger1 = logging.Logger("s1",level=logging.ERROR) # s1 为 格式的name
logger1.addHandler(file_1_1)
logger1.addHandler(file_1_2)
以上是关于Python全栈--7.3--模块补充configparser--logging--subprocess--os.system--shutil的主要内容,如果未能解决你的问题,请参考以下文章