朴素贝叶斯分类器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯分类器相关的知识,希望对你有一定的参考价值。
所谓分类,就是根据事物的特征(Feature)对其归类(Class)
特征的数据特点有两种可能:
1. 标签式
2. 实数(大样本/小样本)
下面我们分别来看
一、标签式
这是一个病人分类的例子
某个医院早上收了六个门诊病人,如下表。
症状 职业 疾病
打喷嚏 护士 感冒
打喷嚏 农夫 过敏
头痛 建筑工人 脑震荡
头痛 建筑工人 感冒
打喷嚏 教师 感冒
头痛 教师 脑震荡
现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:
P(A|B) = P(B|A) P(A) / P(B)
可得
P(感冒|打喷嚏x建筑工人)
= P(打喷嚏x建筑工人|感冒) x P(感冒)
/ P(打喷嚏x建筑工人)
假定"打喷嚏"和"建筑工人"这两个特征是独立的,因此,上面的等式就变成了
P(感冒|打喷嚏x建筑工人)
= P(打喷嚏|感冒) x P(建筑工人|感冒) x P(感冒)
/ P(打喷嚏) x P(建筑工人)
如何计算: P(打喷嚏|感冒)?
特征1:病人症状统计表
| 打喷嚏 | 头痛 | 合计 | |
|---|---|---|---|
| 感冒 | 2 | 1 | 3 |
| 过敏 | 1 | 0 | 1 |
| 脑震荡 | 0 | 2 | 2 |
| 合计 | 3 | 3 | 6 |
P(打喷嚏|感冒) = 2/3 = 0.67
如何计算: P(建筑工人|感冒)?
特征2:病人职业统计表
| 护士 | 农夫 | 建筑工人 | 教师 | 合计 | |
|---|---|---|---|---|---|
| 感冒 | 1 | 0 | 1 | 1 | 3 |
| 过敏 | 0 | 1 | 0 | 0 | 1 |
| 脑震荡 | 0 | 0 | 1 | 1 | 2 |
| 合计 | 1 | 1 | 2 | 2 | 6 |
P(建筑工人|感冒) = 1/3 = 0.33
因此,这个打喷嚏的建筑工人,得了感冒的概率不难计算得:
P(感冒|打喷嚏x建筑工人)
= P(打喷嚏|感冒) x P(建筑工人|感冒) x P(感冒)
/ P(打喷嚏) x P(建筑工人)= 0.67 x 0.33 x 0.5 / 0.5 x 0.33
= 0.67
同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
二、实数(大样本,分区间)
第二个是账号分类的例子
这个问题是这样的,对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类。
运营商决定考察账号的三个特征:日志数量/注册天数、好友数量/注册天数、是否使用真实头像。
运维人员曾经人工检测过的1万个账号,得到这三个特征的先验统计概率
特征1(F1):日志数量/注册天数 统计表
| [0, 0.05) | [0.05, 0.2) | [0.2, +∞) | 合计 | |
|---|---|---|---|---|
| 真实 | 0.12 | 0.30 | 0.28 | 0.60 |
| 虚假 | 0.25 | 0.10 | 0.05 | 0.40 |
| 合计 | 0.37 | 0.40 | 0.33 | 1 |
P(F1_2|真实) = 0.30/0.60 = 0.5
特征2(F2):好友数量/注册天数 统计表
| [0, 0.1 ) | [0.1, 0.5) | [0.5, +∞) | 合计 | |
|---|---|---|---|---|
| 真实 | 0.10 | 0.20 | 0.30 | 0.60 |
| 虚假 | 0.15 | 0.15 | 0.10 | 0.40 |
| 合计 | 0.25 | 0.35 | 0.40 | 1 |
P(F2_2|真实) = 0.20/0.60 = 0.33
特征3(F3):是否使用真实头像(1/0) 统计表
| 1 | 0 | 合计 | |
|---|---|---|---|
| 真实 | 0.48 | 0.12 | 0.60 |
| 虚假 | 0.01 | 0.39 | 0.40 |
| 合计 | 0.49 | 0.51 | 1 |
P(F3_2|真实) = 0.12/0.60 = 0.20
因此,下面这个账号(0.1, 0.2, 0)为真实账号的概率,分析如下:
日志数量/注册天数:0.1 ~ F1_2
好友数量/注册天数:0.2 ~ F2_2
是否使用真实头像:0 ~ F3_2
故
P(真实|F1_2 x F2_2 x F3_2)
= P(F1_2|真实) x P(F1_2|真实)x P(F3_2|真实) x P(真实)
/ P(F1_2) x P(F2_2) x P(F3_2)= 0.5 x 0.33 x 0.2 x 0.6 / 0.4 x 0.35 x 0.51
= 0.28
同理,可以计算
P(虚假|F1_2 x F2_2 x F3_2) = 0.51
三、实数(小样本,设正态)
这是一个性别分类的例子
下面是一组人类身体特征的统计资料。
性别 身高(英尺) 体重(磅) 脚掌(英寸)
男 6 180 12
男 5.92 190 11
男 5.58 170 12
男 5.92 165 10
女 5 100 6
女 5.5 150 8
女 5.42 130 7
女 5.75 150 9
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?
根据朴素贝叶斯分类器,计算下面这个式子的值。
P(身高|性别) x P(体重|性别) x P(脚掌|性别) x P(性别)
这里的困难在于,由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办?
这时,
首先假设男性和女性的身高、体重、脚掌都是正态分布;
然后,通过样本计算出均值和方差;
接着,由正态分布的密度函数,计算出各自条件概率密度。
比如,男性的身高是均值5.855、方差0.035的正态分布。
所以,男性的身高为6英尺的条件概率密度为:
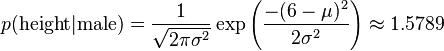
有了这些数据以后,就可以计算(身高,体重,脚掌)=(6、130、8)的性别分类了。
P(身高=6|男) x P(体重=130|男) x P(脚掌=8|男) x P(男)
= 6.1984 x e-9P(身高=6|女) x P(体重=130|女) x P(脚掌=8|女) x P(女)
= 5.3778 x e-4
可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
参考:
http://www.ruanyifeng.com/blog/2013/12/naive_bayes_classifier.html
以上是关于朴素贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章