MySQL数据类型
Posted 编程人,在天涯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL数据类型相关的知识,希望对你有一定的参考价值。
一、数值类型
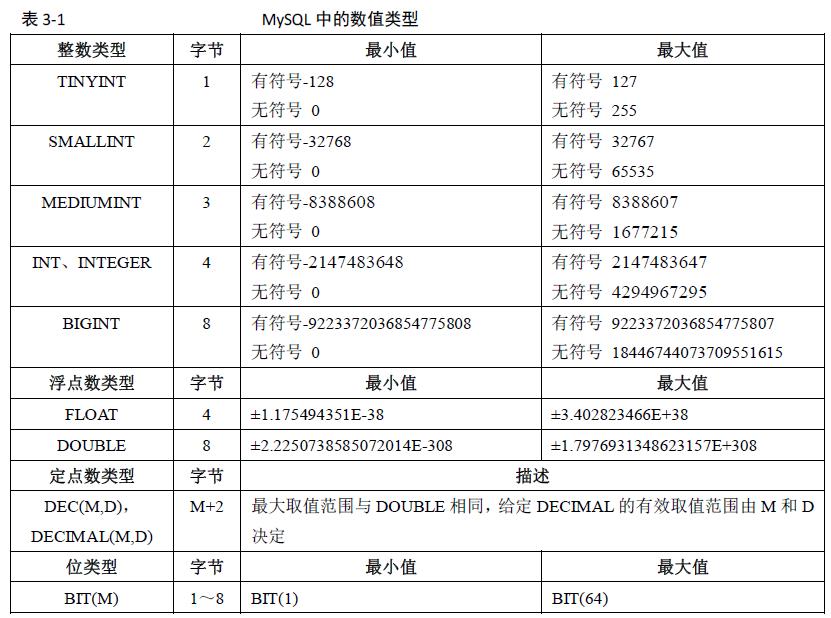
1. 对于整型数据,mysql支持在类型名称后面的小括号内指定显示宽度,如果不指定则默认为int(11),一般配合zerofill使用,数字位数不够的空间使用字符 “0”填满。字段定义示例:phone int zerofill;
2. 如果一个列指定为zerofill,则Mysql自动为该列添加unsigned属性。
3. 一个表最多只能有一个auto_increment列。
4. 定点数decimal在Mysql内部以字符串形式存放,比浮点数更精确。(默认整数位为10,小数位为0)。浮点数存储数据存在误差问题,浮点数的比较也有误差,应尽量避免,如果非要使用浮点数比较则最好使用范围比较而不要使用“==”比较。
5. Decimal的高精度计算是由MySQL服务器自身实现的,需要额外的空间和计算开销。数据量比较大时可以使用bigint来存储乘以相应倍数的小数,这可以同时避免浮点存储计算不精确和decimal精确计算代价高的问题。
6. BIT类型用于存放位字段值。对于位字段,直接使用select命令查询将看不到结果,可以使用bin()或者hex()函数进行读取,分别将其显示为二进制和十六进制格式。若位数超出bit类型字段长度,则无法插入。
7. 浮点数当插入数据的精度超过字段精度定义时,会将数据进行四舍五入后插入,该过程浮点数不会报错,但是定点数可能会进行警告然后插入,或者直接报错,无法插入,这取决于SQLMode。
8. Myisam会打包存储所有bit列,使用一个位来存储一个bit列,而其他引擎为每个bit列使用一个足够存储的最小整数类型来存储。Mysql把bit当作字符串类型。
二、日期时间类型
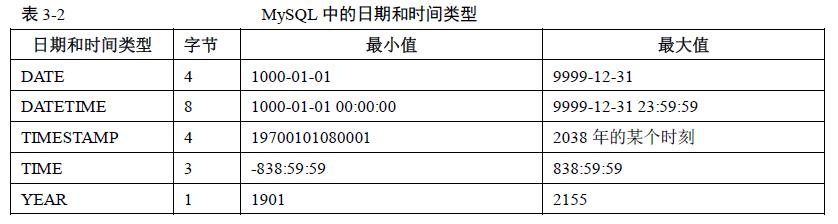
1. Mysql只给表中的第一个TIMESTAMP字段设置默认值为系统时间current_timestamp,如果有第二个TIMESTAMP类型字段,则默认值设置为0。更新记录的时候也会默认更新第一个timestamp列的值。
2. TIMESTAMP还和时区相关,当插入日期时,会先转换为本地时区后存放,而从数据库里面取出时,也同样需要将日期转换为本地时区后显示。这样,两个不同时区的用户看到的同一个日期可能是不一样的。
3. Mysql每种日期时间类型都有一个有效值范围,如果超出这个范围,在默认的SQLMode下,系统会提示错误,并将以零值来进行存储。
4. TIMESTAMP的取值范围为1970年到2038年的某一天,所以它不适合存放比较久远的日期。
5. TIMESTAMP的属性受Mysql版本和服务器SQLMode的影响很大。
6. 日期时间类型的使用原则:选择能够满足应用的最小存储的日期类型。
7. Mysql能存储的最小时间粒度为秒,若想存储更小粒度的时间值可以使用bigint存储微秒级别的时间戳或者使用double存储秒之后的小数部分。
注意:
Mysql的时间类型都不能赋值时间戳。。。而应该按YYYYMMDDHHMMSS这样的时间格式(年月日时分秒之间可以加入多种不同分隔符),或者使用Mysql的now()等函数赋值。
三、字符串类型
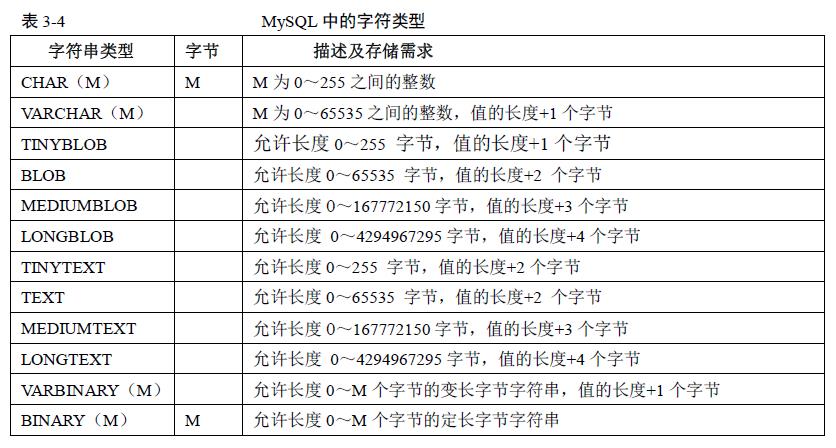
1. 在检索的时候,char列删除了字符串尾部的空格,而varchar则保留这些空格。binary和varbinary类似于char和varchar,不同的是他们包含二进制字符串而不包含非二进制字符串。当保存binary值时,在值的最后通过填充零字节以达到指定的字段定义长度,如:在定义为binary(3)的字段中插入‘a’,使用hex函数查看是610000.
2.由于char是固定长度的,所以它的处理速度比varchar快得多,但其缺点是浪费存储空间,程序需要对行尾空格进行处理。对于那些长度变化不大并且对查询速度有较高要求的数据可以考虑使用char类型来存储。
3. 在MySQL 中,不同的存储引擎对CHAR和VARCHAR的使用原则有所不同:
(1)MyISAM 存储引擎:建议使用固定长度的数据列代替可变长度的数据列。
(2)MEMORY 存储引擎:目前都使用固定长度的数据行存储,因此无论使用CHAR或VARCHAR列都没有关系。两者都是作为CHAR类型处理。
(3)InnoDB 存储引擎:建议使用VARCHAR类型。对于InnoDB 数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好,主要的性能因素是数据行使用的存储总量,由于CHAR平均占用的空间多于VARCHAR,所以使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O 是比较好的。
4. varchar需要使用1或2个额外字节记录字符串的长度,更新时需要做一些额外工作。对于Char,mysql会删除末尾空格。
适合使用varchar的情况:
字符串列的最大长度比平均长度大很多;
列的更新很少,所以碎片不是问题;
使用了像utf-8这样复杂的字符集,每个字符都使用不同的字节数进行存储。
适合使用char的情况:
存储很短的字符串;
所有值都接近同一个长度;
经常变更。
5. Text和blob的主要区别是blob能用来保存二进制数据比如照片,而text只能保存字符数据,比如一篇文章或日记。
6. Blob和text值会引起一些性能问题,特别是在执行了大量的删除操作时,会在表中留下很大的“空洞”,以后填入这些“空洞”的记录在插入的性能上会有影响。为了提高性能,建议定期使用optimize table功能对这类表进行碎片整理,避免因为“空洞”导致性能问题。
由此也可以看出:MySQL数据表删除记录之后,数据表文件大小并不会减小,记录删除的地方会留下一些空白,以后插入记录的时候就会先去填满这些空白。当然,可以手动使用optimize table命令去除这些空白,使数据文件变小。
7. 可以使用合成的索引来提高大文本字段的查询性能:
简单来说,合成索引就是根据大文本字段的内容建立一个散列值(例如使用md5函数),并把这个散列值存储在单独的数据列中,接下来就可以通过检索散列值找到数据行了。这在一定程度上减少I/O,从而提高查询效率。但是这种技术只能用于精确匹配的查询,对于类似<或>=等范围搜索操作符是没有作用的。如果需要对大文本字段进行模糊查询,可以只为字段的前n个字符创建索引,例如:Create index idx_blob on t(content(100)),其中content为text类型字段。这样对content的前100个字符进行模糊查询就可以使用到前缀索引了,但是查询条件中“%”不能放在最前面,否则索引将不会被使用。
8.当BLOB和TEXT值太大时,InnoDB会使用专门的“外部”存储区域来进行存储,此时每个值在行内需要1-4个字节存储一个指针,然后在外部存储区域存储实际的值。Mysql只对blob和text列的最前max_sort_length字节而不是整个字符串做排序。
9.因为memory引擎不支持blob和text类型,所以如果查询使用了blob或text列并且需要使用隐式临时表,将不得不使用myisam磁盘临时表,这会导致严 重的性能开销。可以使用substring(cloumn,length)将列值转换为字符串,这样就可以使用内存临时表了。
10. ENUM类型是忽略大小写的。对于插入不存在ENUM指定范围内的值时,并没有返回警告(Mysql5.7插入失败),而是插入了enum中的第一个值,enum 类型只允许从值集合中选取单个值。
11. Mysql在存储枚举时非常紧凑,会根据列表值的数量压缩到一个或两个字节中,将每个值在列表中的位置保存为整数,并且在.frm文件中保存“数字-字符串”映射关系的“查找表”,实际的数据行中存储的是对应的整数而不是字符串,将整数转换为字符串需要一定的开销。如果能将varchar、char转换为enum会使表大小减小很多。
12. 枚举字段是按照内部存储的整数而不是字符串进行排序的,也可以使用order by field(字段名,’’,’’,’’)显示地指定排序顺序,但这会导致mysql无法利用索引消除排序。把char、varchar列与枚举列进行关联可能比直接关联char、varchar列更慢,但是enum列和enum列关联很快。
13. 相比ENUM,SET可以存储的成员数量比较少,而且需要的字节数比较多,但是set可以一次选取多个成员。对于超出允许值范围的值不允许插入,对于包含重复成员的集合将只取一个。
四、数据类型优化原则
1. 更小的通常更好:一般情况下应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,处理时需要的CPU周期也更少。
2.简单就好:简单数据类型的操作通常需要更少的CPU周期。例如,整型比字符操作代价更低(字符集和校对规则)。例子:使用时间类型而不是字符串来存储日期和时间,使用32位无符号整数存储IP地址,使用INET_ATON()、INET_NTOA()函数进行整数和IP形式的转换。
3.尽量避免使用NULL:
可为NULL值的列会使得索引、索引统计和值比较都更复杂;
可为NULL值的列会使用更多的存储空间,在MySQL需要特殊处理;
可为NULL的列被索引时,每个索引记录需要一个额外的字节。
以上是关于MySQL数据类型的主要内容,如果未能解决你的问题,请参考以下文章