Hadoop基于文件的数据结构及实例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop基于文件的数据结构及实例相关的知识,希望对你有一定的参考价值。
基于文件的数据结构
两种文件格式:
1、SequenceFile
2、MapFile
SequenceFile
1、SequenceFile文件是Hadoop用来存储二进制形式的<key,value>对而设计的一种平面文件(Flat File)。
2、能够把SequenceFile当做一个容器,把全部文件打包到SequenceFile类中能够高效的对小文件进行存储和处理。
3、SequenceFile文件并不依照其存储的key进行排序存储。SequenceFile的内部类Writer**提供了append功能**。
4、SequenceFile中的key和value能够是随意类型Writable或者是自己定义Writable类型。
SequenceFile压缩
1、SequenceFile的内部格式取决于是否启用压缩。假设是。要么是记录压缩。要么是块压缩。
2、三种类型:
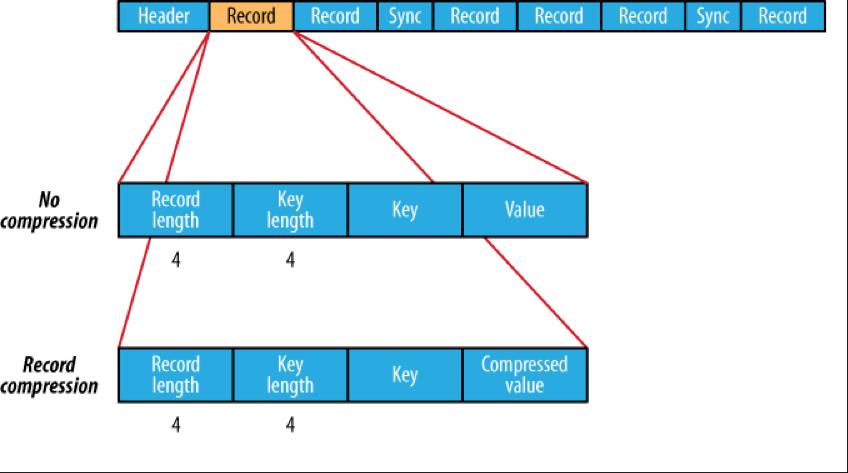
A.无压缩类型:假设没有启用压缩(默认设置),那么每一个记录就由它的记录长度(字节数)、键的长度。键和值组成。长度字段为四字节。
B.记录压缩类型:记录压缩格式与无压缩格式基本同样。不同的是值字节是用定义在头部的编码器来压缩。注意,键是不压缩的。
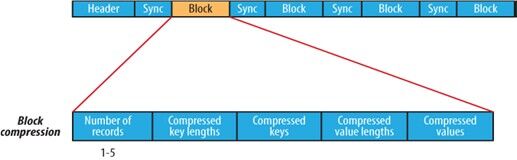
C.块压缩类型:块压缩一次压缩多个记录。因此它比记录压缩更紧凑,并且一般优先选择。
当记录的字节数达到最小大小,才会加入到块。
该最小值由io.seqfile.compress.blocksize中的属性定义。
默认值是1000000字节。
格式为记录数、键长度、键、值长度、值。
无压缩格式与记录压缩格式
块压缩格式
SequenceFile文件格式的优点:
A.支持基于记录(Record)或块(Block)的数据压缩。
B.支持splittable,能够作为MapReduce的输入分片。
C.改动简单:主要负责改动对应的业务逻辑,而不用考虑详细的存储格式。
SequenceFile文件格式的坏处:
坏处是须要一个合并文件的过程。且合并后的文件将不方便查看。由于它是二进制文件。
读写SequenceFile
写过程:
1)创建Configuration
2)获取FileSystem
3)创建文件输出路径Path
4)调用SequenceFile.createWriter得到SequenceFile.Writer对象
5)调用SequenceFile.Writer.append追加写入文件
6)关闭流
读过程:
1)创建Configuration
2)获取FileSystem
3)创建文件输出路径Path
4)new一个SequenceFile.Reader进行读取
5)得到keyClass和valueClass
6)关闭流
org.apache.hadoop.io
Class SequenceFile
There are three SequenceFile Writers based on the SequenceFile.CompressionType used to compress key/value pairs:
1、Writer : Uncompressed records.
2、RecordCompressWriter : Record-compressed files, only compress values.
3、BlockCompressWriter : Block-compressed files, both keys & values are collected in ‘blocks‘ separately and compressed. The size of the ‘block‘ is configurable无压缩方式、记录压缩、块压缩实例
package SequenceFile;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.util.ReflectionUtils;
public class Demo01 {
final static String uri= "hdfs://liguodong:8020/liguodong";
final static String[] data = {
"apache,software","chinese,good","james,NBA","index,pass"
};
public static void main(String[] args) throws IOException {
//1
Configuration configuration = new Configuration();
//2
FileSystem fs = FileSystem.get(URI.create(uri),configuration);
//3
Path path = new Path("/tmp.seq");
write(fs,configuration,path);
read(fs,configuration,path);
}
public static void write(FileSystem fs,Configuration configuration,Path path) throws IOException{
//4
IntWritable key = new IntWritable();
Text value = new Text();
//无压缩
/*@SuppressWarnings("deprecation")
SequenceFile.Writer writer = SequenceFile.createWriter
(fs,configuration,path,key.getClass(),value.getClass());*/
//记录压缩
@SuppressWarnings("deprecation")
SequenceFile.Writer writer = SequenceFile.createWriter
(fs,configuration,path,key.getClass(),
value.getClass(),CompressionType.RECORD,new BZip2Codec());
//块压缩
/*@SuppressWarnings("deprecation")
SequenceFile.Writer writer = SequenceFile.createWriter
(fs,configuration,path,key.getClass(),
value.getClass(),CompressionType.BLOCK,new BZip2Codec());*/
//5
for (int i = 0; i < 30; i++) {
key.set(100-i);
value.set(data[i%data.length]);
writer.append(key, value);
}
//6、关闭流
IOUtils.closeStream(writer);
}
public static void read(FileSystem fs,Configuration configuration,Path path) throws IOException {
//4
@SuppressWarnings("deprecation")
SequenceFile.Reader reader = new SequenceFile.Reader(fs, path,configuration);
//5
Writable key = (Writable) ReflectionUtils.newInstance
(reader.getKeyClass(), configuration);
Writable value = (Writable) ReflectionUtils.newInstance
(reader.getValueClass(), configuration);
while(reader.next(key,value)){
System.out.println("key = " + key);
System.out.println("value = " + value);
System.out.println("position = "+ reader.getPosition());
}
IOUtils.closeStream(reader);
}
}执行结果:
key = 100
value = apache,software
position = 164
key = 99
value = chinese,good
position = 197
key = 98
value = james,NBA
position = 227
key = 97
value = index,pass
position = 258
key = 96
value = apache,software
position = 294
key = 95
value = chinese,good
position = 327
......
key = 72
value = apache,software
position = 1074
key = 71
value = chinese,good
position = 1107MapFile
public class MapFile {
/** The name of the index file. */
public static final String INDEX_FILE_NAME = "index";
/** The name of the data file. */
public static final String DATA_FILE_NAME = "data";
}MapFile是经过排序的索引的SequenceFile,能够依据key进行查找。
与SequenceFile不同的是。 MapFile的Key一定要实现WritableComparable接口 ,即Key值是可比較的,而value是Writable类型的。
能够使用MapFile.fix()方法来重建索引,把SequenceFile转换成MapFile。
它有两个静态成员变量:
static final String INDEX_FILE_NAME
static final String DATA_FILE_NAME通过观察其文件夹结构能够看到MapFile由两部分组成,各自是data和index。
index作为文件的数据索引,主要记录了每一个Record的key值,以及该Record在文件里的偏移位置。
在MapFile被訪问的时候,索引文件会被载入到内存,通过索引映射关系可迅速定位到指定Record所在文件位置。
因此。相对SequenceFile而言, MapFile的检索效率是高效的。缺点是会消耗一部分内存来存储index数据。
需注意的是, MapFile并不会把全部Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为改动,通过MapFIle.Writer的setIndexInterval()方法。或改动io.map.index.interval属性。
读写MapFile
写过程:
1)创建Configuration
2)获取FileSystem
3)创建文件输出路径Path
4)new一个MapFile.Writer对象
5)调用MapFile.Writer.append追加写入文件
6)关闭流
读过程:
1)创建Configuration
2)获取FileSystem
3)创建文件输出路径Path
4)new一个MapFile.Reader进行读取
5)得到keyClass和valueClass
6)关闭流
详细操作与SequenceFile类似。
命令行查看二进制文件
hdfs dfs -text /liguodong/tmp.seq
以上是关于Hadoop基于文件的数据结构及实例的主要内容,如果未能解决你的问题,请参考以下文章