关于最小生成树的Prim算法和Kruskal算法
Posted chenxinabcd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于最小生成树的Prim算法和Kruskal算法相关的知识,希望对你有一定的参考价值。
针对一些城市之间建造公路或者造桥问题,我们需要的是以最小代价完成任务,看了一下别人的代码,思想其实都是差不多,但是感觉不大好理解,比如Kruskal算法中有人写了利用递归实现判断是否形成环,本人愚钝,没有想通。。。现在就算重新整理一遍,也帮自己梳理一下。
这两段代码已经经过本人调试,能够完美运行,希望对大家有帮助。
(1)Prim算法
Prim算法实际上是属于贪心算法吧,每走一步,遍历一次是为了寻找对于当前最需要的点,即最小的邻接边,这点实际上与寻找单源最短路径的Dijkstra算法一样,不过在更新每点路径权值的时候处理方式不大一样,毕竟目的不同。Prim算法的思想是从起点开始选择未访问过的且与起点相邻接的最短边,之后将此邻接点置为已访问,记录该点,然后再更新其他点与这些已经置为访问过的点的距离权值:如果新置的pos点与其他相邻而未访问的点的距离map[pos][j]小于先前距离起始点的low[j],则需要更新low[j],因为low[j]始终要保存的是距离已标记点的最短距离。废话不多说,直接上代码。
#include <iostream>
using namespace std;
#define MaxInt 9999//最大权值
#define N 100//最大定点数
int n,map[N][N],low[N],visited[N];
int Prim()
{
int pos,result=0;
memset(visited,0,sizeof(visited));//所有点置为未访问
visited[1] = 1;//从第一个点开始
pos = 1;
for (int i=1;i<=n;i++)
{
if(i!=pos) low[i] = map[pos][i];//low[]初始化
}
for (int i=1;i<n;i++)//再循环n-1次,因为第一个点已经确定
{
int tmp = MaxInt;
for (int j=1;j<=n;j++)//寻找邻接最小权值点
{
if (visited[j]==0 && low[j]<tmp)
{
tmp = low[j];
pos = j;
}
}
visited[pos] = 1;//新增最小权值点
result += tmp;//记录权值和
for (int j=1;j<=n;j++)//更新权值
{
if (visited[j]==0 && low[j]>map[pos][j])
{
low[j] = map[pos][j];
}
}
}
return result;
}
void PrintMatrix()
{
for (int i=1;i<=n;i++)
{
for (int j=1;j<=n;j++)
{
cout<<map[i][j];
if (j==n)
{
continue;
}
cout<<" ";
}
cout<<endl;
}
}
//为了便于统一录入数据,将数据存入了一个txt文本中
/*
6 10
1 2 6
1 3 1
1 4 5
2 3 5
2 5 3
3 4 5
3 5 6
3 6 4
4 6 2
5 6 6
*/
int main()
{
freopen("Primdata.txt","r",stdin);
int len;
cin>>n>>len;
/*在这里顺便提一下之前我的错误,对memset函数不是很了解,一开始在这里使用的是memset(map,MaxInt,sizeof(map)),发现打印出来的值很不对劲,原来memset只能将存储数据置为0.*/
for(int i=1;i<=n;i++)
{
for (int j=1;j<=n;j++)
{
map[i][j] = MaxInt;//先将权值均置为最大
}
}
int p,q,weight;
for (int i=1;i<=len;i++)
{
cin>>p>>q>>weight;//按照图修改权值
map[p][q] = map[q][p] = weight;//无向图
}
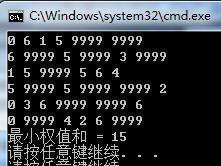
PrintMatrix();
int res = Prim();
cout<<"最小权值和 = "<<res<<endl;
system("pause");
return 0;
}
(2)Kruskal算法
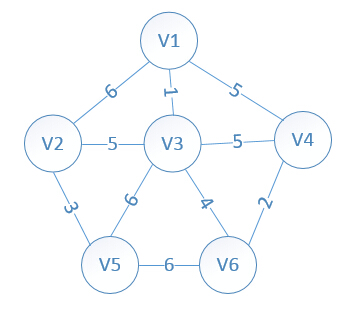
Kruskal算法与Prim算法有所不同,Prim算法主要依赖于节点,所以适用于密集图,算法复杂度为O(n^2),而Kruskal算法依赖于对边的处理,所以适用与稀疏图,反正就是边比较少的图吧,算法复杂度为O(nlogn),两种算法主要区别就是后者首先是对所有边根据权值进行了一次排序,同时适用与权值相同的情况,之后将边的权值从小到大一个个拼接,拼接依据就是看是否能够形成环,如果能,则舍弃该条边,继续处理下一条边,直至所有的边处理完毕,则形成了一颗最小生成树。这里图就懒得画了,借用一下别人的图。
这节内容的源地址是http://blog.chinaunix.net/uid-25324849-id-2182925.html,在此解决了一些问题。

接下来就是代码了:
#include <iostream>
using namespace std;
#define MaxLen 100
#define N 20
int n,len;//顶点数以及边数
int father[N];//定义父节点数组
struct edge//用一结构体存储边以及两个节点的信息
{
int x,y;//两个邻接点
int w;
}e[MaxLen];
void Father_Initialize()//对每条边的节点进行初始化,父节点初始化都为自己
{
for (int i=1;i<=n;i++)
{
father[i] = i;
}
}
bool Is_Same(int i,int j)//判断一条边两个节点是否有同一父节点
{
while (father[i]!=i)//寻找父节点
{
i = father[i];
}
while (father[j]!=j)
{
j = father[j];
}
return i==j? true:false;
}
void Union_Group(int i,int j)//将新加入的边进行处理,统一父节点
{
if (i>j) swap(i,j);//固定顺序,保证节点顺序从小到大
while (i!=father[i])
{
i = father[i];
}
while (j!=father[j])//
{
j = father[j];
}
father[j] = i;//j的父节点置为i,即最终父节点
}
int sortcmp(const void *a,const void *b)//比较函数,用于qsort()的边排序
{
edge aa = *(const edge*)a;
edge bb = *(const edge*)b;
return aa.w - bb.w;
}
/*//Kruskaldata.txt数据,数据与Primdata.txt一样,说明结果
6 10
1 2 6
1 3 1
1 4 5
2 3 5
2 5 3
3 4 5
3 5 6
3 6 4
4 6 2
5 6 6
*/
int main()
{
int result = 0;
freopen("Kruskaldata.txt","r",stdin);
cin>>n>>len;
for (int i=1;i<=len;i++)
{
cin>>e[i].x>>e[i].y>>e[i].w;
}
qsort(e,len,sizeof(edge),sortcmp);
Father_Initialize();
for (int i=1;i<=len;i++)
{
if (!Is_Same(e[i].x,e[i].y))//如果不能构成环,即符合条件
{
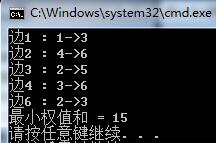
result += e[i].w;
cout<<"边"<<i<<" : "<<e[i].x<<"->"<<e[i].y<<endl;
Union_Group(e[i].x,e[i].y);
}
}
cout<<"最小权值和 = "<<result<<endl;
system("pause");
return 0;
}
本来想继续再写一下Dijkstra算法的,但发现似乎与标题不符,下次再写吧,本人第一次写博客,理解问题可能不到位,如有错误或需改进之处,还望提出,不甚感激!
以上是关于关于最小生成树的Prim算法和Kruskal算法的主要内容,如果未能解决你的问题,请参考以下文章