linux内核的idr学习
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux内核的idr学习相关的知识,希望对你有一定的参考价值。
今天在看mtd驱动的时候发现idr, 之后网上找了很多资料, 其中我觉得这份参考资料比较好:http://www.2cto.com/kf/201301/186066.html.
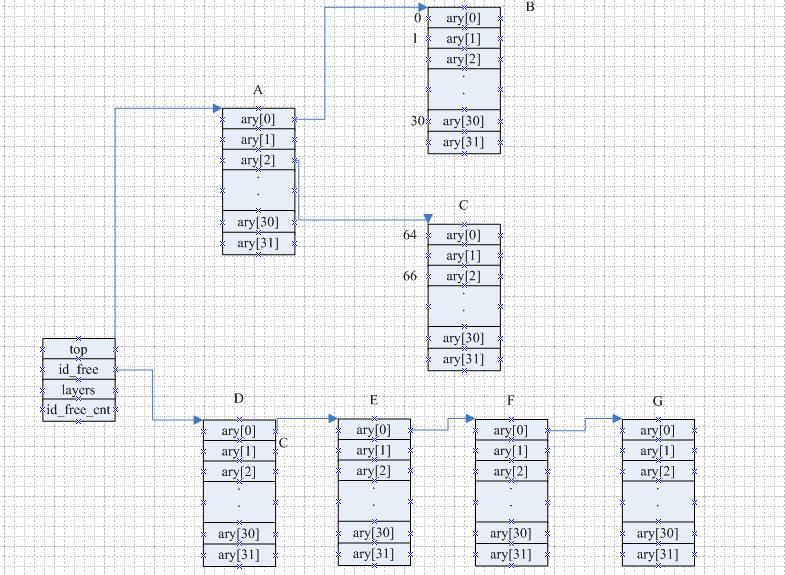
idr主要是实现id与数据结构地址的绑定, 一般是结构体的地址. 如果地址比较少的情况下, 可以直接定义一个全局的指针数组, 以数组的下标作为id与地址对应. 但是当地址数量很大的时候, 固定的指针数组无法满足我们的需求, 而且由于用下标作为id的原因使得id无法根据用户的需求改变. 那这个时候一般会想到用链表存储, 这样id就可以很大, 但是链表很长时, 查找时间变慢了. idr就是将数组与链表的优点结合起来. 它利用1个4字节的32位来对应32个地址, 用1个位图和32个地址作为1组结构体. 看起来1个结构体只能存放32个数据, 其实结构体里的32个地址除了可以存放你想放的数据, 也可以分别指向另一个结构体地址, 这样就相当于存放32^2个数据了, 如果继续这样下去, 就是可以存放32^3, 32^4, 32^5...个数据, 达到32^7个数据就已经超过4字节可以表示的最大数了. 所以只要7层这样的结构就足够了. 然后idr查找就是按照层索引的方式, 前面说过32个地址作为1组, 每一层的索引只需要5位2进制就可以了, 将4字节按5位拆开, 得到这样:
31 30 | 29 28 27 26 25 | 24 23 22 21 20 | 19 18 17 16 15 | 14 13 12 11 10 | 9 8 7 6 5 | 4 3 2 1 0
比如要查找ID为0x12345678, 分开后就是00 | 01001 | 00011 | 01000 | 10101 | 10011 | 11000, 高层向底层索引, 内核代码就写好的, 不用自己算.
idr的优势还有, 它有效的利用内存, 可以用下面的图来说明, A是顶层, B与C是下一层, B负责存放0-31的ID对应的数据, C负责存放64-95的ID对应的数据,而A的ary[1]并没有开辟空间, 因为并没有申请32-63的ID, 所有不必申请这样的空间.
以上是关于linux内核的idr学习的主要内容,如果未能解决你的问题,请参考以下文章