一个“小小”的pagehelper
Posted eternal-heathens
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个“小小”的pagehelper相关的知识,希望对你有一定的参考价值。
分页
若是想要了解一个代码的底层,最好的方法仍是从官网的案例和配置说明开始,自顶向下,才能一路通畅
直接就某个类出发,可能在某个从顶层类就存在的参数的创建过程缺失,可能会让你丈二摸不着头脑,连往上都不知道怎么往上
前端分页
一次性请求数据表格中的所有记录(ajax),然后在前端缓存并且计算count和分页逻辑,一般前端组件(例如dataTable)会提供分页动作。
特点是:简单,很适合小规模的web平台;当数据量大的时候会产生性能问题,在查询和网络传输的时间会很长。
后端分页
在ajax请求中指定页码(pageNum)和每页的大小(pageSize),后端查询出当页的数据返回,前端只负责渲染。
特点是:复杂一些;性能瓶颈在mysql的查询性能,这个当然可以调优解决。一般来说,web开发使用的是这种方式。
我们说的也是后端分页。
MySQL对分页的支持:
limit关键字的用法是
LIMIT [offset,] rows
offset是相对于首行的偏移量(首行是0),rows是返回条数。
# 每页10条记录,取第一页,返回的是前10条记录
select * from tableA limit 0,10;
# 每页10条记录,取第二页,返回的是第11条记录,到第20条记录,
select * from tableA limit 10,10;
1. 引入分页插件
引入分页插件有下面2种方式,推荐使用 Maven 方式。
1). 引入 Jar 包
你可以从下面的地址中下载最新版本的 jar 包
- https://oss.sonatype.org/content/repositories/releases/com/github/pagehelper/pagehelper/
- http://repo1.maven.org/maven2/com/github/pagehelper/pagehelper/
由于使用了sql 解析工具,你还需要下载 jsqlparser.jar(需要和PageHelper 依赖的版本一致) :
2). 使用 Maven
在 pom.xml 中添加如下依赖:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>最新版本</version>
</dependency>
最新版本号可以从首页查看。
2. 配置拦截器插件
特别注意,新版拦截器是 com.github.pagehelper.PageInterceptor。 com.github.pagehelper.PageHelper 现在是一个特殊的 dialect 实现类,是分页插件的默认实现类,提供了和以前相同的用法。
1. 在 MyBatis 配置 xml 中配置拦截器插件
<!--
plugins在配置文件中的位置必须符合要求,否则会报错,顺序如下:
properties?, settings?,
typeAliases?, typeHandlers?,
objectFactory?,objectWrapperFactory?,
plugins?,
environments?, databaseIdProvider?, mappers?
-->
<plugins>
<!-- com.github.pagehelper为PageHelper类所在包名 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!-- 使用下面的方式配置参数,后面会有所有的参数介绍 -->
<property name="param1" value="value1"/>
</plugin>
</plugins>
2. 在 Spring 配置文件中配置拦截器插件
使用 spring 的属性配置方式,可以使用 plugins 属性像下面这样配置:
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 注意其他配置 -->
<property name="plugins">
<array>
<bean class="com.github.pagehelper.PageInterceptor">
<property name="properties">
<!--使用下面的方式配置参数,一行配置一个 -->
<value>
params=value1
</value>
</property>
</bean>
</array>
</property>
</bean>
3. 分页插件参数介绍
分页插件提供了多个可选参数,这些参数使用时,按照上面两种配置方式中的示例配置即可。
分页插件可选参数如下:
dialect:默认情况下会使用 PageHelper 方式进行分页,如果想要实现自己的分页逻辑,可以实现Dialect(com.github.pagehelper.Dialect) 接口,然后配置该属性为实现类的全限定名称。
下面几个参数都是针对默认 dialect 情况下的参数。使用自定义 dialect 实现时,下面的参数没有任何作用。
helperDialect:分页插件会自动检测当前的数据库链接,自动选择合适的分页方式。 你可以配置helperDialect属性来指定分页插件使用哪种方言。配置时,可以使用下面的缩写值:
oracle,mysql,mariadb,sqlite,hsqldb,postgresql,db2,sqlserver,informix,h2,sqlserver2012,derby
特别注意:使用 SqlServer2012 数据库时,需要手动指定为sqlserver2012,否则会使用 SqlServer2005 的方式进行分页。
你也可以实现AbstractHelperDialect,然后配置该属性为实现类的全限定名称即可使用自定义的实现方法。offsetAsPageNum:默认值为false,该参数对使用RowBounds作为分页参数时有效。 当该参数设置为true时,会将RowBounds中的offset参数当成pageNum使用,可以用页码和页面大小两个参数进行分页。rowBoundsWithCount:默认值为false,该参数对使用RowBounds作为分页参数时有效。 当该参数设置为true时,使用RowBounds分页会进行 count 查询。pageSizeZero:默认值为false,当该参数设置为true时,如果pageSize=0或者RowBounds.limit = 0就会查询出全部的结果(相当于没有执行分页查询,但是返回结果仍然是Page类型)。reasonable:分页合理化参数,默认值为false。当该参数设置为true时,pageNum<=0时会查询第一页,pageNum>pages(超过总数时),会查询最后一页。默认false时,直接根据参数进行查询。params:为了支持startPage(Object params)方法,增加了该参数来配置参数映射,用于从对象中根据属性名取值, 可以配置pageNum,pageSize,count,pageSizeZero,reasonable,不配置映射的用默认值, 默认值为pageNum=pageNum;pageSize=pageSize;count=countSql;reasonable=reasonable;pageSizeZero=pageSizeZero。supportMethodsArguments:支持通过 Mapper 接口参数来传递分页参数,默认值false,分页插件会从查询方法的参数值中,自动根据上面params配置的字段中取值,查找到合适的值时就会自动分页。 使用方法可以参考测试代码中的com.github.pagehelper.test.basic包下的ArgumentsMapTest和ArgumentsObjTest。autoRuntimeDialect:默认值为false。设置为true时,允许在运行时根据多数据源自动识别对应方言的分页 (不支持自动选择sqlserver2012,只能使用sqlserver),用法和注意事项参考下面的场景五。closeConn:默认值为true。当使用运行时动态数据源或没有设置helperDialect属性自动获取数据库类型时,会自动获取一个数据库连接, 通过该属性来设置是否关闭获取的这个连接,默认true关闭,设置为false后,不会关闭获取的连接,这个参数的设置要根据自己选择的数据源来决定。aggregateFunctions(5.1.5+):默认为所有常见数据库的聚合函数,允许手动添加聚合函数(影响行数),所有以聚合函数开头的函数,在进行 count 转换时,会套一层。其他函数和列会被替换为 count(0),其中count列可以自己配置。
重要提示:
当 offsetAsPageNum=false 的时候,由于 PageNum 问题,RowBounds查询的时候 reasonable 会强制为 false。使用 PageHelper.startPage 方法不受影响。
4. 如何选择配置这些参数
单独看每个参数的说明可能是一件让人不爽的事情,这里列举一些可能会用到某些参数的情况。
场景一
如果你仍然在用类似ibatis式的命名空间调用方式,你也许会用到rowBoundsWithCount, 分页插件对RowBounds支持和 MyBatis 默认的方式是一致,默认情况下不会进行 count 查询,如果你想在分页查询时进行 count 查询, 以及使用更强大的 PageInfo 类,你需要设置该参数为 true。
注: PageRowBounds 想要查询总数也需要配置该属性为 true。
场景二
如果你仍然在用类似ibatis式的命名空间调用方式,你觉得 RowBounds 中的两个参数 offset,limit 不如 pageNum,pageSize 容易理解, 你可以使用 offsetAsPageNum 参数,将该参数设置为 true 后,offset会当成 pageNum 使用,limit 和 pageSize 含义相同。
场景三
如果觉得某个地方使用分页后,你仍然想通过控制参数查询全部的结果,你可以配置 pageSizeZero 为 true, 配置后,当 pageSize=0 或者 RowBounds.limit = 0 就会查询出全部的结果。
场景四
如果你分页插件使用于类似分页查看列表式的数据,如新闻列表,软件列表, 你希望用户输入的页数不在合法范围(第一页到最后一页之外)时能够正确的响应到正确的结果页面, 那么你可以配置 reasonable 为 true,这时如果 pageNum<=0 会查询第一页,如果 pageNum>总页数 会查询最后一页。
场景五
如果你在 Spring 中配置了动态数据源,并且连接不同类型的数据库,这时你可以配置 autoRuntimeDialect 为 true,这样在使用不同数据源时,会使用匹配的分页进行查询。 这种情况下,你还需要特别注意 closeConn 参数,由于获取数据源类型会获取一个数据库连接,所以需要通过这个参数来控制获取连接后,是否关闭该连接。 默认为 true,有些数据库连接关闭后就没法进行后续的数据库操作。而有些数据库连接不关闭就会很快由于连接数用完而导致数据库无响应。所以在使用该功能时,特别需要注意你使用的数据源是否需要关闭数据库连接。
当不使用动态数据源而只是自动获取 helperDialect 时,数据库连接只会获取一次,所以不需要担心占用的这一个连接是否会导致数据库出错,但是最好也根据数据源的特性选择是否关闭连接。
3. 如何在代码中使用
阅读前请注意看重要提示
分页插件支持以下几种调用方式:
//第一种,RowBounds方式的调用
List<User> list = sqlSession.selectList("x.y.selectIf", null, new RowBounds(0, 10));
//第二种,Mapper接口方式的调用,推荐这种使用方式。
PageHelper.startPage(1, 10);
List<User> list = userMapper.selectIf(1);
//第三种,Mapper接口方式的调用,推荐这种使用方式。
PageHelper.offsetPage(1, 10);
List<User> list = userMapper.selectIf(1);
//第四种,参数方法调用
//存在以下 Mapper 接口方法,你不需要在 xml 处理后两个参数
public interface CountryMapper {
List<User> selectByPageNumSize(
@Param("user") User user,
@Param("pageNum") int pageNum,
@Param("pageSize") int pageSize);
}
//配置supportMethodsArguments=true
//在代码中直接调用:
List<User> list = userMapper.selectByPageNumSize(user, 1, 10);
//第五种,参数对象
//如果 pageNum 和 pageSize 存在于 User 对象中,只要参数有值,也会被分页
//有如下 User 对象
public class User {
//其他fields
//下面两个参数名和 params 配置的名字一致
private Integer pageNum;
private Integer pageSize;
}
//存在以下 Mapper 接口方法,你不需要在 xml 处理后两个参数
public interface CountryMapper {
List<User> selectByPageNumSize(User user);
}
//当 user 中的 pageNum!= null && pageSize!= null 时,会自动分页
List<User> list = userMapper.selectByPageNumSize(user);
//第六种,ISelect 接口方式
//jdk6,7用法,创建接口
Page<User> page = PageHelper.startPage(1, 10).doSelectPage(new ISelect() {
@Override
public void doSelect() {
userMapper.selectGroupBy();
}
});
//jdk8 lambda用法
Page<User> page = PageHelper.startPage(1, 10).doSelectPage(()-> userMapper.selectGroupBy());
//也可以直接返回PageInfo,注意doSelectPageInfo方法和doSelectPage
pageInfo = PageHelper.startPage(1, 10).doSelectPageInfo(new ISelect() {
@Override
public void doSelect() {
userMapper.selectGroupBy();
}
});
//对应的lambda用法
pageInfo = PageHelper.startPage(1, 10).doSelectPageInfo(() -> userMapper.selectGroupBy());
//count查询,返回一个查询语句的count数
long total = PageHelper.count(new ISelect() {
@Override
public void doSelect() {
userMapper.selectLike(user);
}
});
//lambda
total = PageHelper.count(()->userMapper.selectLike(user));
下面对最常用的方式进行详细介绍
1). RowBounds方式的调用
List<User> list = sqlSession.selectList("x.y.selectIf", null, new RowBounds(1, 10));
使用这种调用方式时,你可以使用RowBounds参数进行分页,这种方式侵入性最小,我们可以看到,通过RowBounds方式调用只是使用了这个参数,并没有增加其他任何内容。
分页插件检测到使用了RowBounds参数时,就会对该查询进行物理分页。
关于这种方式的调用,有两个特殊的参数是针对 RowBounds 的,你可以参看上面的 场景一 和 场景二
注:不只有命名空间方式可以用RowBounds,使用接口的时候也可以增加RowBounds参数,例如:
//这种情况下也会进行物理分页查询
List<User> selectAll(RowBounds rowBounds);
注意: 由于默认情况下的 RowBounds 无法获取查询总数,分页插件提供了一个继承自 RowBounds 的 PageRowBounds,这个对象中增加了 total 属性,执行分页查询后,可以从该属性得到查询总数。
2). PageHelper.startPage 静态方法调用
除了 PageHelper.startPage 方法外,还提供了类似用法的 PageHelper.offsetPage 方法。
在你需要进行分页的 MyBatis 查询方法前调用 PageHelper.startPage 静态方法即可,紧跟在这个方法后的第一个MyBatis 查询方法会被进行分页。
例一:
//获取第1页,10条内容,默认查询总数count
PageHelper.startPage(1, 10);
//紧跟着的第一个select方法会被分页
List<User> list = userMapper.selectIf(1);
assertEquals(2, list.get(0).getId());
assertEquals(10, list.size());
//分页时,实际返回的结果list类型是Page<E>,如果想取出分页信息,需要强制转换为Page<E>
assertEquals(182, ((Page) list).getTotal());
例二:
//request: url?pageNum=1&pageSize=10
//支持 ServletRequest,Map,POJO 对象,需要配合 params 参数
PageHelper.startPage(request);
//紧跟着的第一个select方法会被分页
List<User> list = userMapper.selectIf(1);
//后面的不会被分页,除非再次调用PageHelper.startPage
List<User> list2 = userMapper.selectIf(null);
//list1
assertEquals(2, list.get(0).getId());
assertEquals(10, list.size());
//分页时,实际返回的结果list类型是Page<E>,如果想取出分页信息,需要强制转换为Page<E>,
//或者使用PageInfo类(下面的例子有介绍)
assertEquals(182, ((Page) list).getTotal());
//list2
assertEquals(1, list2.get(0).getId());
assertEquals(182, list2.size());
例三,使用PageInfo的用法:
//获取第1页,10条内容,默认查询总数count
PageHelper.startPage(1, 10);
List<User> list = userMapper.selectAll();
//用PageInfo对结果进行包装
PageInfo page = new PageInfo(list);
//测试PageInfo全部属性
//PageInfo包含了非常全面的分页属性
assertEquals(1, page.getPageNum());
assertEquals(10, page.getPageSize());
assertEquals(1, page.getStartRow());
assertEquals(10, page.getEndRow());
assertEquals(183, page.getTotal());
assertEquals(19, page.getPages());
assertEquals(1, page.getFirstPage());
assertEquals(8, page.getLastPage());
assertEquals(true, page.isFirstPage());
assertEquals(false, page.isLastPage());
assertEquals(false, page.isHasPreviousPage());
assertEquals(true, page.isHasNextPage());
3). 使用参数方式
想要使用参数方式,需要配置 supportMethodsArguments 参数为 true,同时要配置 params 参数。 例如下面的配置:
<plugins>
<!-- com.github.pagehelper为PageHelper类所在包名 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!-- 使用下面的方式配置参数,后面会有所有的参数介绍 -->
<property name="supportMethodsArguments" value="true"/>
<property name="params" value="pageNum=pageNumKey;pageSize=pageSizeKey;"/>
</plugin>
</plugins>
在 MyBatis 方法中:
List<User> selectByPageNumSize(
@Param("user") User user,
@Param("pageNumKey") int pageNum,
@Param("pageSizeKey") int pageSize);
当调用这个方法时,由于同时发现了 pageNumKey 和 pageSizeKey 参数,这个方法就会被分页。params 提供的几个参数都可以这样使用。
除了上面这种方式外,如果 User 对象中包含这两个参数值,也可以有下面的方法:
List<User> selectByPageNumSize(User user);
当从 User 中同时发现了 pageNumKey 和 pageSizeKey 参数,这个方法就会被分页。
注意:pageNum 和 pageSize 两个属性同时存在才会触发分页操作,在这个前提下,其他的分页参数才会生效。
3). PageHelper 安全调用
1. 使用 RowBounds 和 PageRowBounds 参数方式是极其安全的
2. 使用参数方式是极其安全的
3. 使用 ISelect 接口调用是极其安全的
ISelect 接口方式除了可以保证安全外,还特别实现了将查询转换为单纯的 count 查询方式,这个方法可以将任意的查询方法,变成一个 select count(*) 的查询方法。
4. 什么时候会导致不安全的分页?
PageHelper 方法使用了静态的 ThreadLocal 参数,分页参数和线程是绑定的。
只要你可以保证在 PageHelper 方法调用后紧跟 MyBatis 查询方法,这就是安全的。因为 PageHelper 在 finally 代码段中自动清除了 ThreadLocal 存储的对象。
如果代码在进入 Executor 前发生异常,就会导致线程不可用,这属于人为的 Bug(例如接口方法和 XML 中的不匹配,导致找不到 MappedStatement 时), 这种情况由于线程不可用,也不会导致 ThreadLocal 参数被错误的使用。
但是如果你写出下面这样的代码,就是不安全的用法:
PageHelper.startPage(1, 10);
List<User> list;
if(param1 != null){
list = userMapper.selectIf(param1);
} else {
list = new ArrayList<User>();
}
这种情况下由于 param1 存在 null 的情况,就会导致 PageHelper 生产了一个分页参数,但是没有被消费,这个参数就会一直保留在这个线程上。当这个线程再次被使用时,就可能导致不该分页的方法去消费这个分页参数,这就产生了莫名其妙的分页。
上面这个代码,应该写成下面这个样子:
List<User> list;
if(param1 != null){
PageHelper.startPage(1, 10);
list = userMapper.selectIf(param1);
} else {
list = new ArrayList<User>();
}
这种写法就能保证安全。
如果你对此不放心,你可以手动清理 ThreadLocal 存储的分页参数,可以像下面这样使用:
List<User> list;
if(param1 != null){
PageHelper.startPage(1, 10);
try{
list = userMapper.selectAll();
} finally {
PageHelper.clearPage();
}
} else {
list = new ArrayList<User>();
}
这么写很不好看,而且没有必要。
5、梦开始的地方
-
探究原理我们就需要从哪开始会与PageHelper开始有关系,首先PageHelper只能用在selsect上,相关性最大的便是getmapper生成的代理类与sqlsession.selectList方法,而getmapper的最终的实现中也有selectList,从复用的角度,两者应该殊途同归。
-
大致的流程如此:
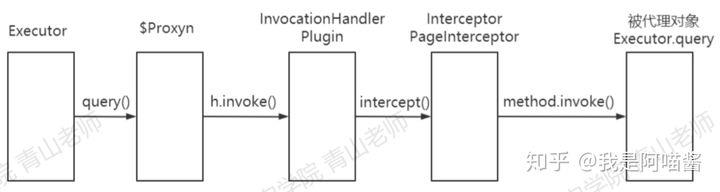
-
而defaultSqlsession中有selectCursor和selectList,两者也都用到了RowBounds
public class DefaultSqlSession implements SqlSession {
public <T> Cursor<T> selectCursor(String statement, Object parameter, RowBounds rowBounds) {
Cursor var6;
try {
MappedStatement ms = this.configuration.getMappedStatement(statement);
Cursor<T> cursor = this.executor.queryCursor(ms, this.wrapCollection(parameter), rowBounds);
this.registerCursor(cursor);
var6 = cursor;
} catch (Exception var10) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + var10, var10);
} finally {
ErrorContext.instance().reset();
}
return var6;
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
List var5;
try {
// 获取需要执行的statement语句
MappedStatement ms = this.configuration.getMappedStatement(statement);
//Page能被引用的原因的开头
//Page能被引用的原因的开头
//梦开始的地方
var5 = this.executor.query(ms, this.wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception var9) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + var9, var9);
} finally {
ErrorContext.instance().reset();
}
return var5;
}
- 正常流程下,接着便是调用SimpleExecutor(extends BaseExecutor)中的query方法 ,queryFromDatabase方法,doquery方法(这三个都是BaseExecutor的)
public class SimpleExecutor extends BaseExecutor {
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
List var9;
try {
Configuration configuration = ms.getConfiguration();
// 实例化一个语句处理类,很关键
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//获取connection
stmt = this.prepareStatement(handler, ms.getStatementLog());
//执行语句
var9 = handler.query(stmt, resultHandler);
} finally {
this.closeStatement(stmt);
}
return var9;
}
}
- Configuration中的newStatementHandler
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//新建一个StatementHandler的实现类
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
//最最关键的一步,将StatementHandler进行动态代理,实现责任链中Interceptor对StatementHandler的增强,生成代理类
StatementHandler statementHandler = (StatementHandler)this.interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
- InterceptorChain便是责任链的实现类了,他存储了我们再.xml文件的plugins中的interceptor,在Configutation起初创建的时候便已经同时创建了,Configuraiton自从sqlsessionFatoryBean容器化调用getObjct后,在buildSqlSessionFactory方法创建后,便一直贯穿了基本所有有sqlsession字样的业务,sqlsession中“最顶”的类了。
public class InterceptorChain {
// 自configuration被创建时也随之创建并赋值好了
private final List<Interceptor> interceptors = new ArrayList();
public Object pluginAll(Object target) {
Interceptor interceptor;
//将interceptors中的interceptor逐个取出,调用plugin方法,用Plugin类生成代理对象
for(Iterator var2 = this.interceptors.iterator(); var2.hasNext(); target = interceptor.plugin(target)) {
interceptor = (Interceptor)var2.next();
}
return target;
}
}
- 我们可能对interceptor会有很多疑问
https://www.jianshu.com/p/9c1c78604e4e
问题一: 我们的 Interceptor 是何时被注册到 ibatis 的, 注册到哪里去了
首先回答注册到哪里去: configuration.InterceptorChain 中 , 结构为 : List interceptors =new ArrayList();
xml 声明 Interceptor 的地方 有两个:
1. ibatis 的 config 配置
中配置 , 这个配置文件 我们一般叫做 mybatis-config.xml 2. spring 配置数据源的地方配置 sqlSessionFactory(class="org.mybatis.spring.SqlSessionFactoryBean") 时 以property 的方式给sqlSessionFactoryBean 的 plugins 赋值
① 方式声明的plugin 添加的 configuration的 InterceptorChain 路径为: SqlSessionFactoryBean.afterPropertiesSet().buildSqlSessionFactory() ---> XmlConfigBuilder.parse().parseConfiguration(XNode root).pluginElement(root.evalNode("plugins")).configuration.addInterceptor(interceptorInstance)
进而调用 InterceptorChain的addInterceptor 方法添加 到 InterceptorChain 的 List interceptors =new ArrayList(); 中
②方式声明的plugin 添加到 configuration的InterceptorChain 路径为:
SqlSessionFactoryBean.afterPropertiesSet().buildSqlSessionFactory().configuration.addInterceptor(interceptorInstance)
①和②的实现逻辑都从 sqlSessionFactoryBean.afterPropertiesSet().buildSqlSessionFactory() 开始看就好
**问题二: 我们的Interceptor 是何时被调用的 , 初次被调用时调用了哪个方法 **
InterceptorChain 除了问题一的 addInterceptor 方法外 还有两个方法:
public Object pluginAll(Object target)
public List getInterceptors()
下面我们看一下 pluginAll 的实现:
public Object pluginAll(Object target) {
for (Interceptor interceptor :interceptors) {
target = interceptor.plugin(target);
}
return target;
}
- 接下去我们需要了解mybatis 拦截器主体结构,通过一个完整的流程来了解什么是责任链,他的作用,他是何时开始便被决定要调用的。
5、mybatis 拦截器主体结构
https://www.cnblogs.com/sanzao/p/11423849.html
在编写 mybatis 插件的时候,首先要实现 Interceptor 接口,然后在 mybatis-conf.xml 中添加插件,
<configuration>
<plugins>
<plugin interceptor="***.interceptor1"/>
<plugin interceptor="***.interceptor2"/>
</plugins>
</configuration>
这里需要注意的是,添加的插件是有顺序的,因为在解析的时候是依次放入 ArrayList 里面,而调用的时候其顺序为:2 > 1 > target > 1 > 2;(插件的顺序可能会影响执行的流程)更加细致的讲解可以参考 QueryInterceptor 规范 ;
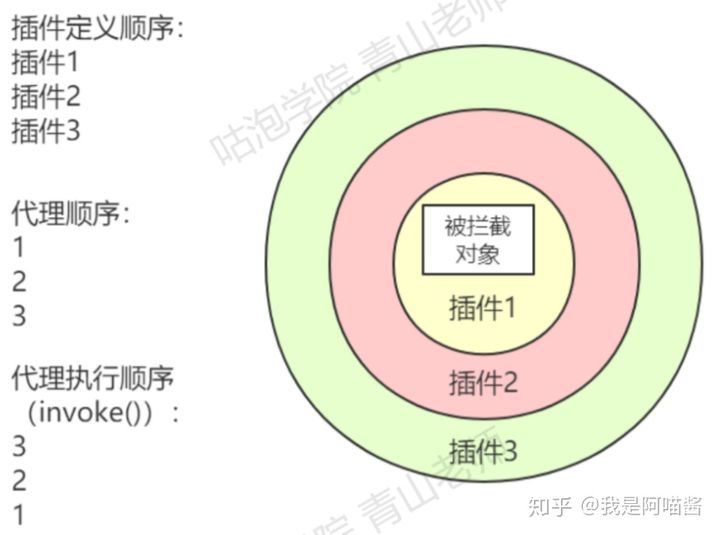
然后当插件初始化完成之后,添加插件的流程如下:
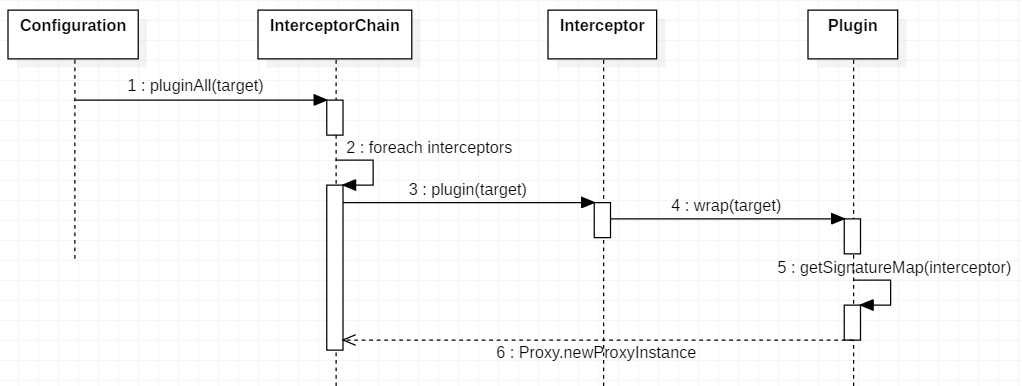
首先要注意的是,mybatis 插件的拦截目标有四个,Executor、StatementHandler、ParameterHandler、ResultSetHandler:
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
这里使用的时候都是用动态代理将多个插件用责任链的方式添加的,最后返回的是一个代理对象; 其责任链的添加过程如下:
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
最终动态代理生成和调用的过程都在 Plugin 类中:
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor); // 获取签名Map
Class<?> type = target.getClass(); // 拦截目标 (ParameterHandler|ResultSetHandler|StatementHandler|Executor)
Class<?>[] interfaces = getAllInterfaces(type, signatureMap); // 获取目标接口
if (interfaces.length > 0) {
return Proxy.newProxyInstance( // 生成代理
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap));
}
return target;
}
这里所说的签名是指在编写插件的时候,指定的目标接口和方法,例如:
@Intercepts({
@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
public class ExamplePlugin implements Interceptor {
public Object intercept(Invocation invocation) throws Throwable {
...
}
}
这里就指定了拦截 Executor 的具有相应方法的 update、query 方法;注解的代码很简单,大家可以自行查看;然后通过 getSignatureMap 方法反射取出对应的 Method 对象,在通过 getAllInterfaces 方法判断,目标对象是否有对应的方法,有就生成代理对象,没有就直接反对目标对象;
在调用的时候:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
Set<Method> methods = signatureMap.get(method.getDeclaringClass()); // 取出拦截的目标方法
if (methods != null && methods.contains(method)) { // 判断这个调用的方法是否在拦截范围内
return interceptor.intercept(new Invocation(target, method, args)); // 在目标范围内就拦截
}
return method.invoke(target, args); // 不在目标范围内就直接调用方法本身
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
6、PageHelper 拦截器分析
mybatis 插件我们平时使用最多的就是分页插件了,这里以 PageHelper 为例,其使用方法可以查看相应的文档 如何使用分页插件,因为官方文档讲解的很详细了,我这里就简单补充分页插件需要做哪几件事情;
使用:
PageHelper.startPage(1, 2);
List<User> list = userMapper1.getAll();
PageHelper 还有很多中使用方式,这是最常用的一种,他其实就是在 ThreadLocal 中设置了 Page 对象,能取到就代表需要分页,在分页完成后在移除,这样就不会导致其他方法分页;(PageHelper 使用的其他方法,也是围绕 Page 对象的设置进行的)
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
//当已经执行过orderBy的时候
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
setLocalPage(page);
return page;
}
主要实现:
@Intercepts({
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
})
public class PageInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if (args.length == 4) {
//4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数
Long count = count(executor, ms, parameter, rowBounds, resultHandler, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
}
- 首先可以看到拦截的是 Executor 的两个 query 方法(这里的两个方法具体拦截到哪一个受插件顺序影响,最终影响到 cacheKey 和 boundSql 的初始化);
- 然后使用 checkDialectExists 判断是否支持对应的数据库;
- 在分页之前需要查询总数,这里会生成相应的 sql 语句以及对应的 MappedStatement 对象,并缓存;
- 然后拼接分页查询语句,并生成相应的 MappedStatement 对象,同时缓存;
- 最后查询,查询完成后使用 dialect.afterPage 移除 Page对象
7. ExecutorUtil和MySqlDialect
- 当代理对象被调用时,便会调用Plugin的wrap方法生成的代理对象的invoke方法,其对调用interceptor.intercept,即上面的主要实现,若是用mysql,则其中的dialect便是MySqlDialect,ExecutorUtil.pageQuery中也会调用的方法。
- 我们先讲下ExecutorUtil.pageQuery,因为是静态方法,存于JVM的方法区中,可直接调用。
public abstract class ExecutorUtil { public static <E> List<E> pageQuery(Dialect dialect, Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql, CacheKey cacheKey) throws SQLException { //判断是否有Page if (!dialect.beforePage(ms, parameter, rowBounds)) { //没有则用RowBounds.DEFAULT执行query return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql); } else { //执行dialect.processParameterObject和getPageSql parameter = dialect.processParameterObject(ms, parameter, boundSql, cacheKey); String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, cacheKey); //保存page的sql相关信息 BoundSql pageBoundSql = new BoundSql(ms.getConfiguration(), pageSql, boundSql.getParameterMappings(), parameter); Map<String, Object> additionalParameters = getAdditionalParameter(boundSql); Iterator var12 = additionalParameters.keySet().iterator(); while(var12.hasNext()) { String key = (String)var12.next(); pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key)); } //用pageBoundSql执行代替旧的sql语句执行 return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, pageBoundSql); } }
- 接着便是MySqlDialect的时间了,可以看出是继承于AbstractHelperDialect(提供了beforePage、beforeCount、afterPage、afterCount等常用的判断,结束处理方法,也实现了processParameterObject(对各个数据库的Dialect的processPageParameter方法调用前的预处理,生成parameter参数放到paramMap,用来生成应用了Page后的BoundSql))
public class MySqlDialect extends AbstractHelperDialect {
public MySqlDialect() {
}
public Object processPageParameter(MappedStatement ms, Map<String, Object> paramMap, Page page, BoundSql boundSql, CacheKey pageKey) {
paramMap.put("First_PageHelper", page.getStartRow());
paramMap.put("Second_PageHelper", page.getPageSize());
pageKey.update(page.getStartRow());
pageKey.update(page.getPageSize());
if (boundSql.getParameterMappings() != null) {
List<ParameterMapping> newParameterMappings = new ArrayList(boundSql.getParameterMappings());
if (page.getStartRow() == 0) {
newParameterMappings.add((new Builder(ms.getConfiguration(), "Second_PageHelper", Integer.class)).build());
} else {
newParameterMappings.add((new Builder(ms.getConfiguration(), "First_PageHelper", Integer.class)).build());
newParameterMappings.add((new Builder(ms.getConfiguration(), "Second_PageHelper", Integer.class)).build());
}
MetaObject metaObject = MetaObjectUtil.forObject(boundSql);
metaObject.setValue("parameterMappings", newParameterMappings);
}
return paramMap;
}
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
return sqlBuilder.toString();
}
}
public Object processParameterObject(MappedStatement ms, Object parameterObject, BoundSql boundSql, CacheKey pageKey) {
Page page = this.getLocalPage();
if (page.isOrderByOnly()) {
return parameterObject;
} else {
Map<String, Object> paramMap = null;
if (parameterObject == null) {
paramMap = new HashMap();
} else if (parameterObject instanceof Map) {
paramMap = new HashMap();
paramMap.putAll((Map)parameterObject);
} else {
paramMap = new HashMap();
boolean hasTypeHandler = ms.getConfiguration().getTypeHandlerRegistry().hasTypeHandler(parameterObject.getClass());
MetaObject metaObject = MetaObjectUtil.forObject(parameterObject);
if (!hasTypeHandler) {
String[] var9 = metaObject.getGetterNames();
int var10 = var9.length;
for(int var11 = 0; var11 < var10; ++var11) {
String name = var9[var11];
paramMap.put(name, metaObject.getValue(name));
}
}
if (boundSql.getParameterMappings() != null && boundSql.getParameterMappings().size() > 0) {
Iterator var13 = boundSql.getParameterMappings().iterator();
ParameterMapping parameterMapping;
String name;
do {
do {
do {
do {
if (!var13.hasNext()) {
return this.processPageParameter(ms, paramMap, page, boundSql, pageKey);
}
parameterMapping = (ParameterMapping)var13.next();
name = parameterMapping.getProperty();
} while(name.equals("First_PageHelper"));
} while(name.equals("Second_PageHelper"));
} while(paramMap.get(name) != null);
} while(!hasTypeHandler && !parameterMapping.getJavaType().equals(parameterObject.getClass()));
paramMap.put(name, parameterObject);
}
}
return this.processPageParameter(ms, paramMap, page, boundSql, pageKey);
}
}
- 依照Interceptor 的拦截顺序依次实现了相应的Intercepte方法后,相关参数改变,条件判断时便会直接跳过就如jdbc的execute。
- 最后便是执行转换后的sql语句的事情了
以上是关于一个“小小”的pagehelper的主要内容,如果未能解决你的问题,请参考以下文章
Spring boot入门:SpringBoot集成结合AdminLTE(Freemarker),利用generate自动生成代码,利用DataTable和PageHelper进行分页显示(示例(代码