《AWK 基础入门讲解实战视频课程》笔记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《AWK 基础入门讲解实战视频课程》笔记相关的知识,希望对你有一定的参考价值。
【awk作用】
默认逐行处理文本或者命令输出(如果保存到文件,本质上也是文本),用来处理命令输出时很有用。
更准确地讲是适合处理表格式的文本的。
{cmd}花括号每执行一次就把结果打印一行在终端上。
行:record
列:field
? ?
【awk课程简介】
理论不说了,直接实验上截图吧。
AWK来源不说了,百度百科吧。
AWK版本不说了。
awk命令的位置:
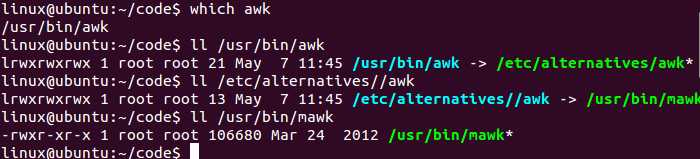
老师写了个播放音乐的脚本,先下载mplayer
ping www.baidu.com
sudo apt-get update
sudo apt-get install mplayer

【awk工作模式】
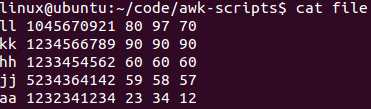
测试文件:
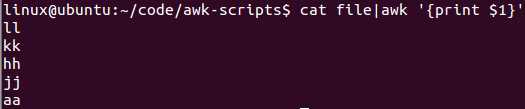
awk过滤第一列:
字段
字段分隔符:空白(一种视觉效果)
逐行读取处理命令工作模式
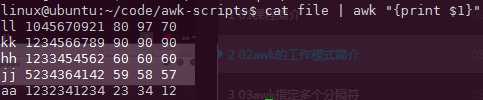
不要用双引号,会出错:
【awk指定多个分隔符】
不是空白分隔符的情形:
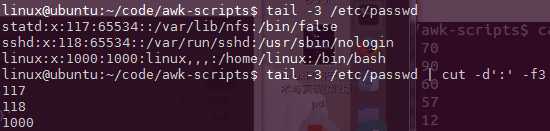
指定分隔符:

正则:
[中括号表示任意一个]
+连续的多个当做一个来处理
[: ]+ 连续的多个: 连续的多个空格 连续的多个组合:空格
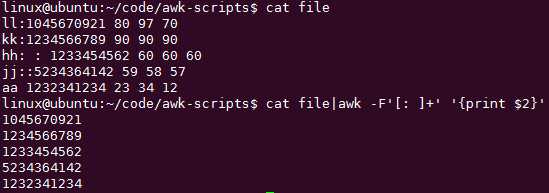
指定多种分隔符:
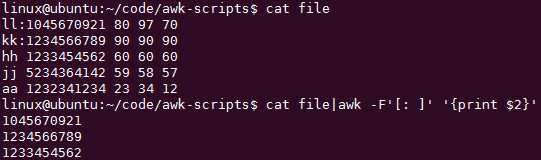
tr替换:cat file | tr ‘:‘ ‘\\t‘
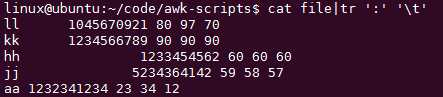
多个空格、制表符合并为空白:
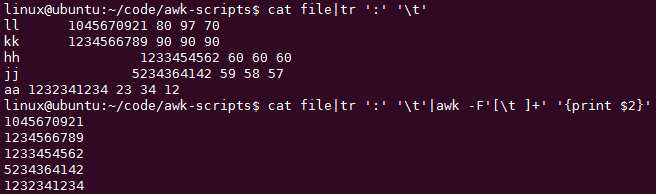
awk提取ip地址:ifconfig eth0|grep ‘t a‘|awk -F‘[: ]+‘ ‘{print $4}‘
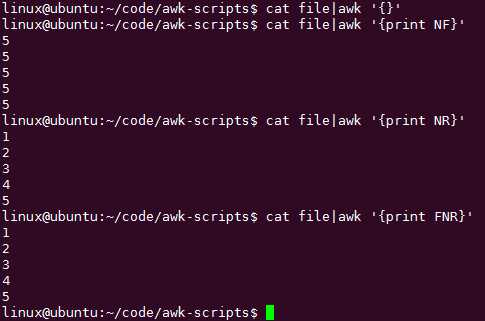
【awk内置变量NF讲解】
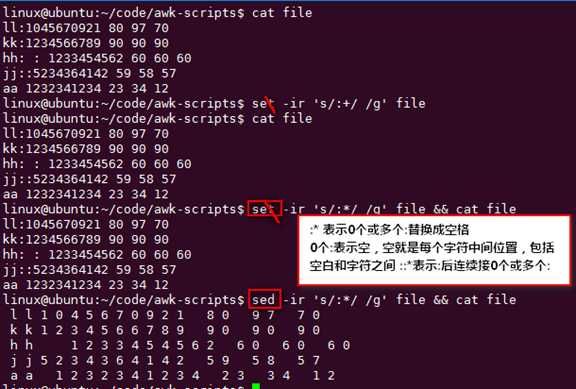
用sed把冒号:替换成空格,tr不能真正替换
sed -ir ‘s/:+/ /g‘ file
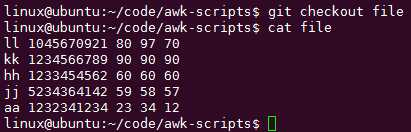
全乱了,放弃工作区的修改:
awk同时取多列,用逗号连接,用分号连接则被当成命令,或者把逗号换成双引号放打印的:
" "打印一个空格和加逗号分隔的效果一样,因为逗号默认一个空格分隔字段打印
" "打印两个空格
" "打印三个空格
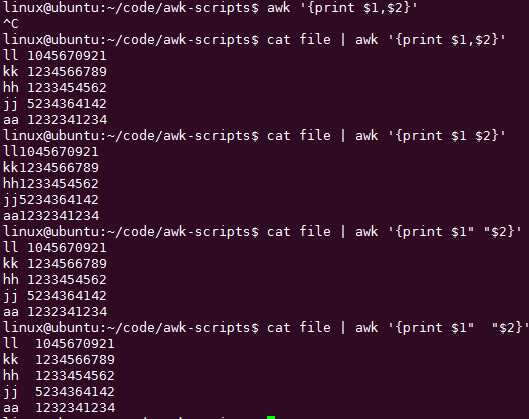
awk取每行最后1个构成列打印,NF内置变量:保存每行的字段数目,逐行处理的时候,会检查每行的NF
$列数(从1索引)
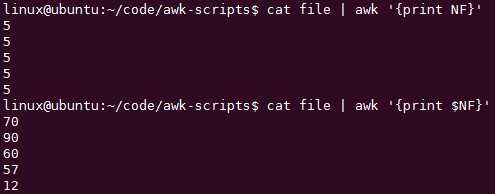
如果每行字段数目不一样呢:如果用具体魔数就能打印,所以要用特殊意义的变量:
awk ‘{command}‘
取倒数第二列呢?
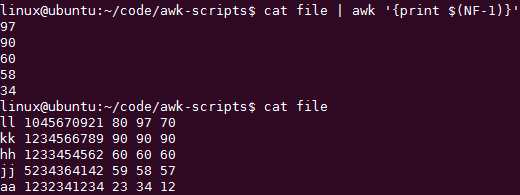
如果你不加括号的话会变成加减法:
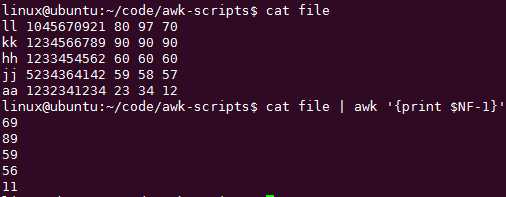
NF number of field 字段数目
【awk内置变量NR和FNR介绍】
number of recording 就是处理过的行数
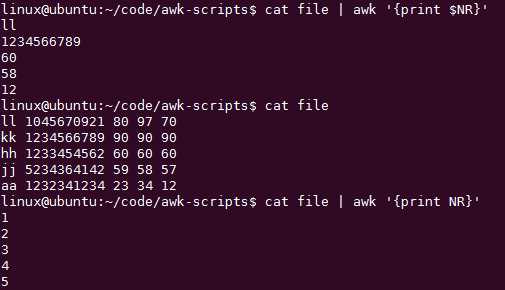
继续继续,搞起来:
FNR又是什么?
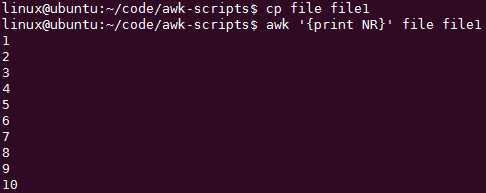
NR表示awk一次处理的总行数,FNR呢?
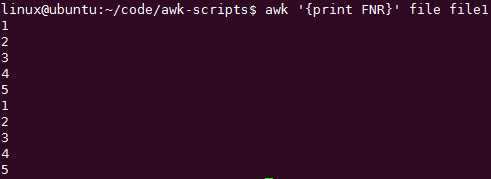
FNR会每次只处理一个文件,原来是这个区别啊!
$0 会打印所有列,空即是有,有即是空
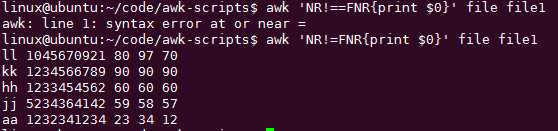
awk ‘NR==FNR{print $0}‘ file file1 条件执行
NR==FNR会比较这两者的单独输出,单独输出上面已经截图了:

那么不等呢,FNR只有处理多个文件时才用到:
取第二行到第三行怎么取:cat file | awk ‘NR>1&&NR<4{print $0}‘

因为awk是逐行处理的,所以命令都是作用于一行的,
如果想单独处理某几行则用条件表达式处理NR即可。
【awk中pattern介绍】
命令模式,先看命令(函数/行为/动作/action)执行条件/判断/option/pattern
awk ‘<cond>{command}‘ 只有{command}默认执行花括号内的命令
awk ‘NR!=1{command}‘
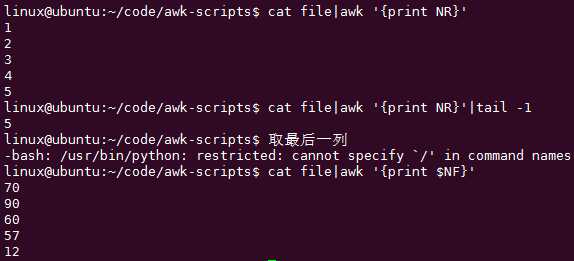
awk ‘1{command}‘
awk ‘2{command}‘ 不可以是负数
awk ‘0{command}‘
awk ‘"0"{command}‘ 任何字符串都是真
awk ‘a{command}‘ 没有赋值的变量为假
awk ‘{a=1}a{command}‘ {a=1}变量赋值方法
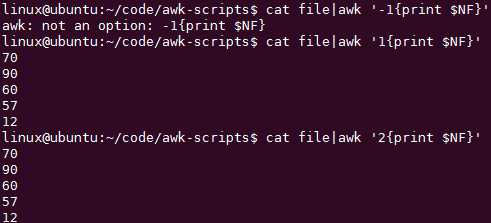
每次把‘‘内的命令作用于每一行,而每个{}分别对每一行执行一次:
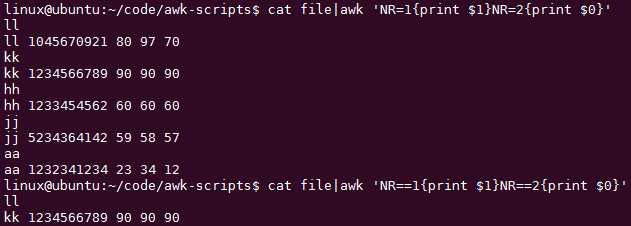
注意:这里是NR==n,注意是两个等号。
? ?
【awk中BEGIN和END简介】
cat file|awk ‘BEGIN{print "===Grade==="}{print $0}‘

cat file | awk ‘BEGIN{print "===Grade==="}{print $0}END{print "===Tail==="}‘
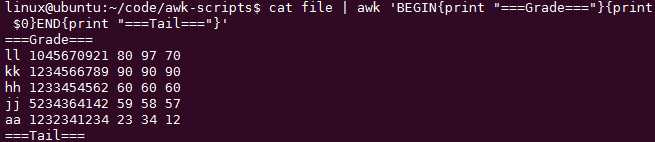
BEGIN最常用的是给变量赋值在文件还没有读取之前,BEGIN就是一个特殊模式
END最常用的是完事后打印数组
pattern{action}pattern1{action1}pattern2{action2}
【awk有关计算的方法】比较常用的
给文件多增加一列,也就是增加一个字段啦:
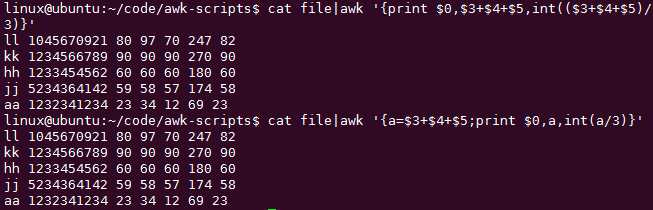
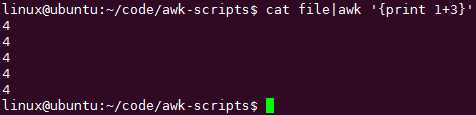
cat file|awk ‘{print $0,$3+$4+$5}‘
cat file|awk ‘{print $0,$3+$4+$5,($3+$4+$5)/3}‘ 支持输出除法4位小数
cat file|awk ‘{print $0,$3+$4+$5,int(($3+$4+$5)/3)}‘

如何使用变量提取重复使用的东西,减少输入和不友好:
cat file|awk ‘{a=$3+$4+$5;print $0,a,int(a/3)}‘
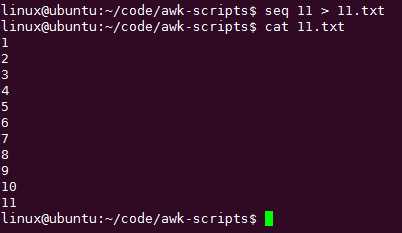
创建一个包含1~10的文本文件:seq 10 > 10.txt,seq用于一堆数字的简化写法:
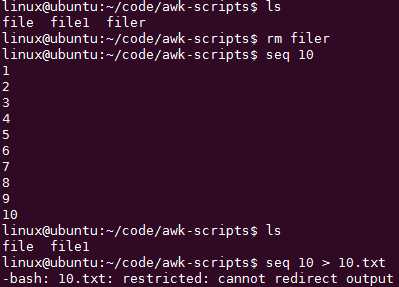
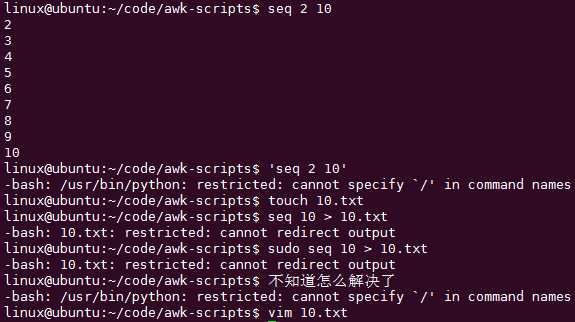
出错了:
如何计算某列的全部值相加:
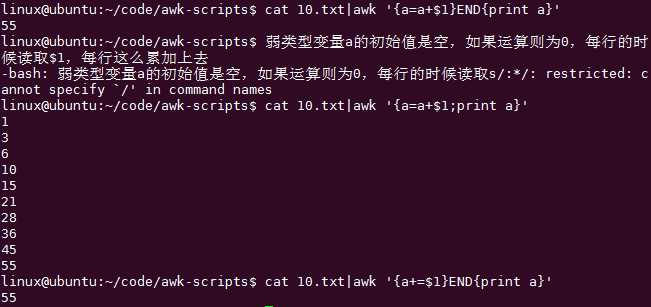
这里就体现了END的作用了,就是只处理最终的结果的意思。
如果想求最后1列的所有值得和:

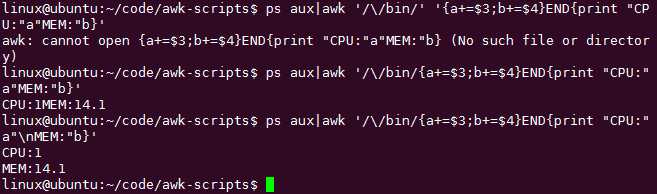
求1列的和有什么作用呢?一般用在终端里面算CPU的占用率很方便
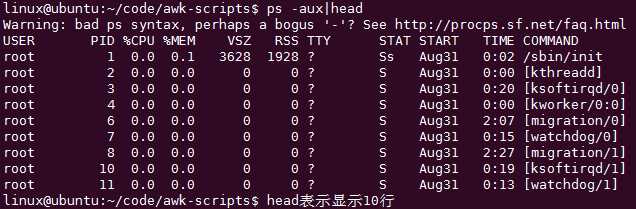
CPU在第三列,所以先过滤出某几行(NR==法或者grep法)
内存是第四列,
从而统计出某个进程的占用的资源

简单加法:
【awk中if简单讲解】
Q-Dir资源管理器不错
if能有什么实际用处呢?
awk ‘{if($3>=80)print $0}‘逻辑更清楚,虽然打字多了
awk ‘$3>=80{print $0}‘ 之前‘pattern{action}‘的格式,这属于先过滤行,而if是属于处理行,所以过滤行在{}之外,而if在{}命令之内
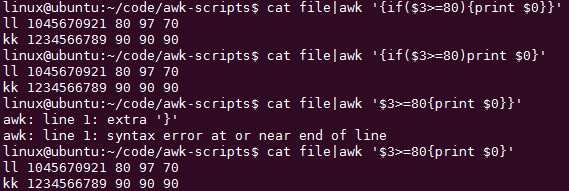
我们用if语句过滤出某列满足特定条件的行出来:
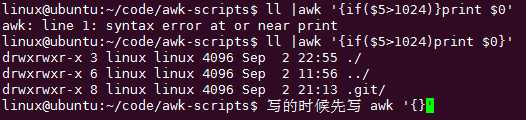
再从里面过滤出文件:
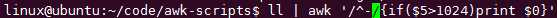
/^-/这个模式时匹配两杠之间的东西,-表示普通文件,所以此时用if就更加清楚了,把正则用来匹配pattern,把if用来判断条件
if判断输出第一行:

取出行数NR大于1的行:
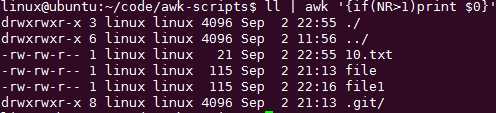
取出某列符合条件的行:cat file|awk ‘{if($3>58)print $0}‘

? ?
【awk中变量介绍】用分号;
自己起变量建议全部小写,因为好多内置变量都是全部大写的,所以自己起都用小写。
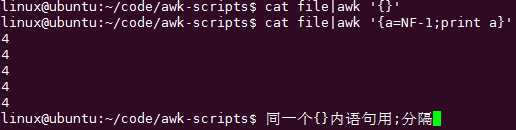
一般在BEGING里面赋值变量,因为BEGIN是在文件处理之前赋值变量的:
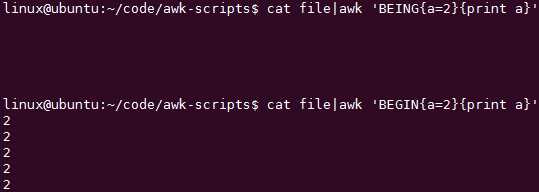
a在bash里面赋值了,如果要在awk里面引用则必须用‘$a的模式‘
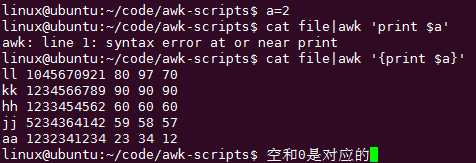
改成‘$a‘模式
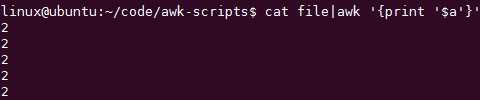
改成$‘$a‘模式
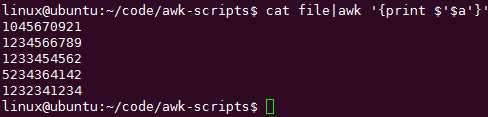
或者重新在awk里面定义变量,但是不在{}里面就可以不加引号:cat file|awk -va=$a ‘{print $a}‘
用来引用外部变量

标准变量赋值方法:-v v是variable的意思,v后面可以有空格也可以没有空格

? ?
? ?
【awk中for循环简介】注意:起始值从1开始

for循环一般用来循环数组的。
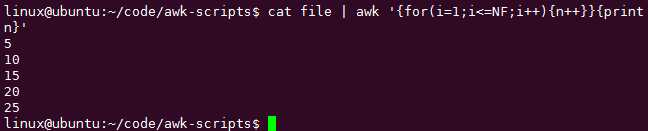
如何让一行中的每个字段占一行打印:cat file|awk ‘{for(i=1;i<=NF;i++)print $i}‘
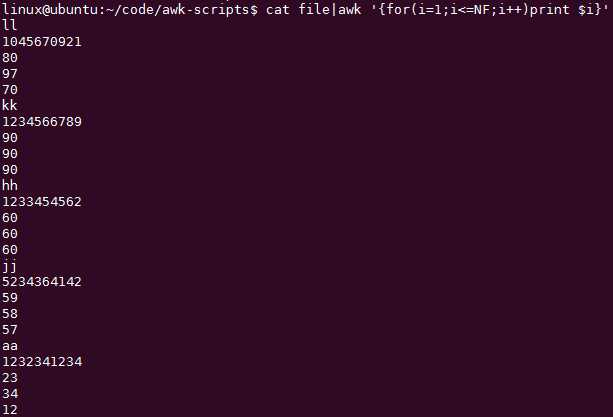
for循环可以让你取多个连续的列:
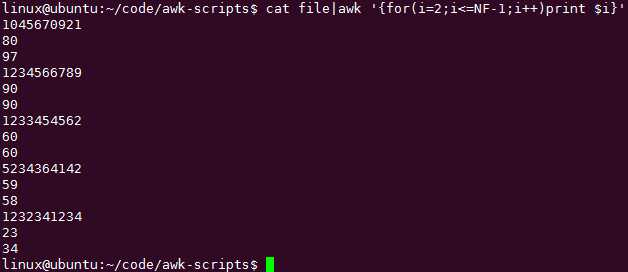
print自动换行
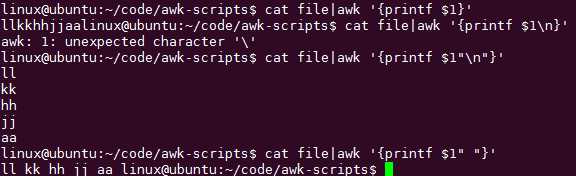
printf不自动换行,要加\\n
? ?
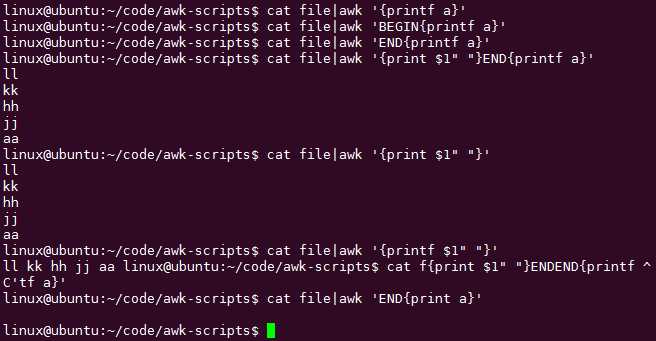
for循环能做哪些实际的有用的东西呢?
打印空的话自动占一行print
如何取出奇数列,记住是从1索引的
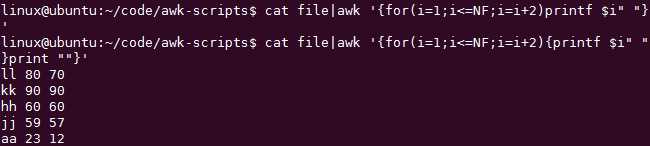
最外层的{}是针对一行的,然后内部的{}则是分别对这一行按顺序操作一遍
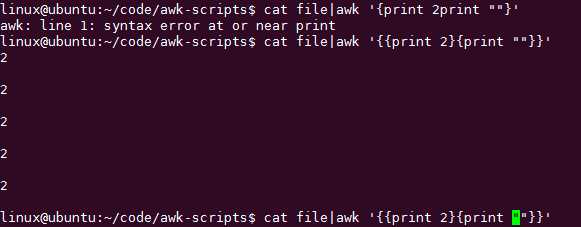
printf "\\n"
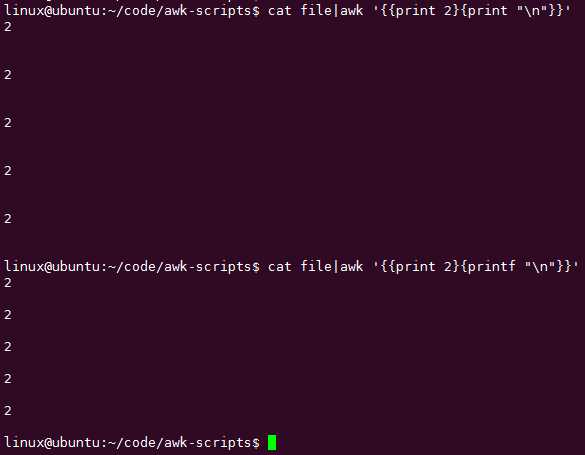
字符串要用""引起来:$0表示打印出当前处理的行
最外层{}里面的语句用;分隔和用{}分隔的意思是一样的,都是表示把该行当做输入参数执行多条语句:
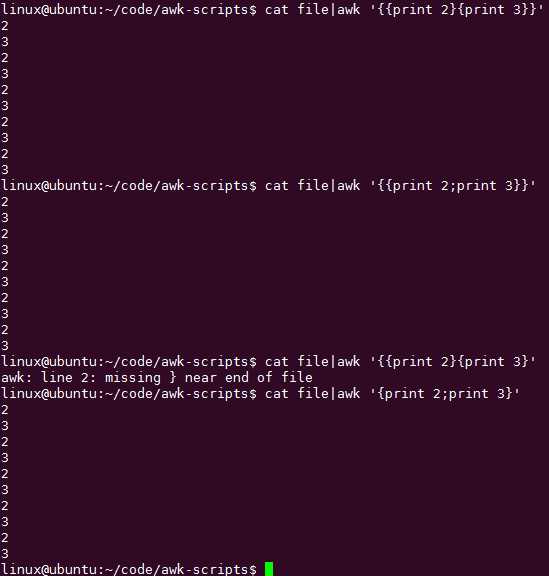
替换某列的某个变量
cat file | awk ‘{if($1==‘lx‘){print $0}else{$1="lx";print $0}}‘
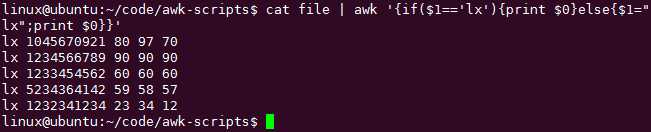
{}就相当于块语句一样
? ?
? ?
【awk正则简介】
awk调用外部命令,用双引号引起来的是命令
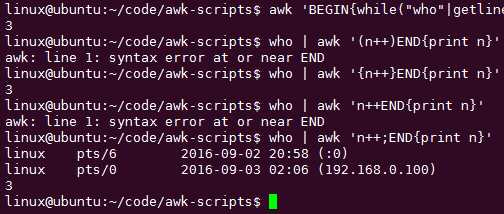
awk ‘BEGIN{while("who"|getline)n++;print n}‘ 用分号;的话可以不加{}
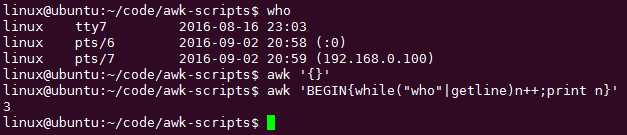
一般不再awk语句中使用双引号引用外部命令,而是把外部命令的结果通过管道传递个awk处理:

END表示要最后一个结果,中间过程不要显示了。
? ?
重定向结果显示:

在外面重定向是一样的,关键是显示什么:

一般重定向也是在外面做:
在SSH中无法完成重定向,不知道怎么解决,不用就好了:

发现如果SSH登陆时选择接受并保存权限可以提高,可以解决这个问题:
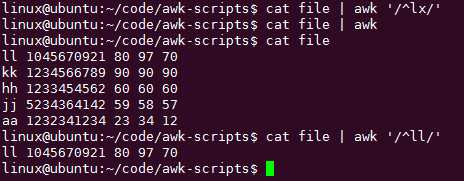
如果要过滤出以ll开头的行 ‘/^ll/‘
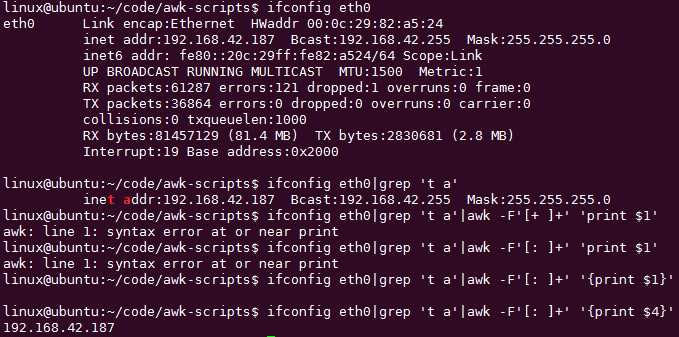
如何用sed取出ip地址:ifconfig eth0|grep ‘t a‘|sed ‘s/^.*r:\\(.*\\) Bc.*$/\\1/g‘
p是present,g是替换
sed -n ‘s/pattern/\\1/p‘
^开头
$结尾
\\1是后向引用,但是awk不支持后向引用-_-

【awk正则深入】awk两个斜线之间表示正则表达式

两个斜线之间的正则表达式匹配是作用于每一行的每次,会匹配任意模式:
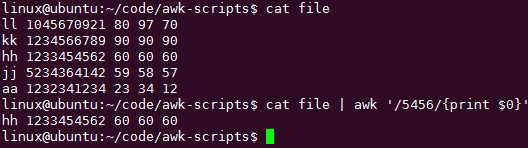
如何把正则表达式模式匹配到一个字段中:
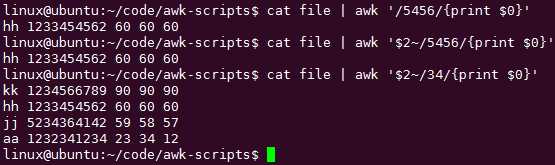
正则表达式,其实隐含了if语句,凡是匹配处,默认都隐含了判断啊:注意,if必须放到{}内,而pattern则是放在{}外的:
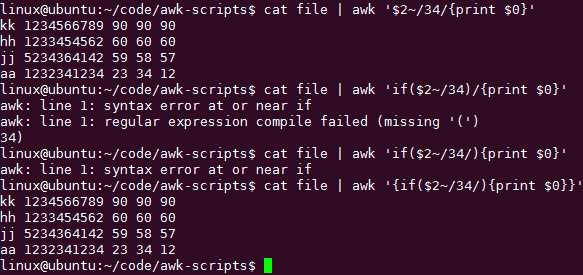
正则表达一般是作用于每行的某个具体字段的!
在if上叠加多层过滤:
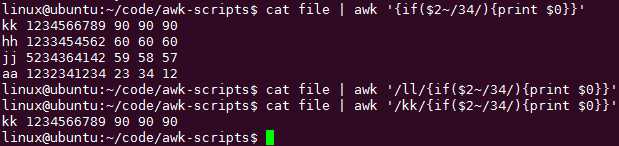
可以通过pattern和if的组合,避免用&& ||

? ?
? ?
【awk简单总结】
who 查看有几个用户登录了
awk普通模式必须要有输入文件,而BEGIN模式不需要输入文件
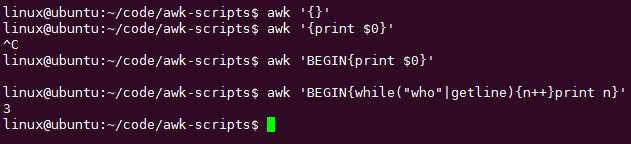
在awk里面可以shell命令,其实最好是在外面用命令,然后用awk处理
默认输出
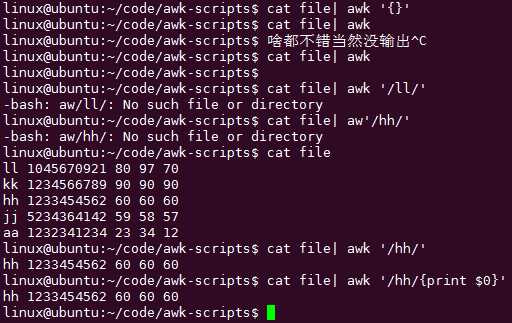
不加$0相当于输出行:

文件名需要引起来如果在内部的话,外部的话不需要双引号把文件名引起来
参数:
-f 表示从文件读命令
awk -f xxx.txt
awk -f xxx.txt file
? ?
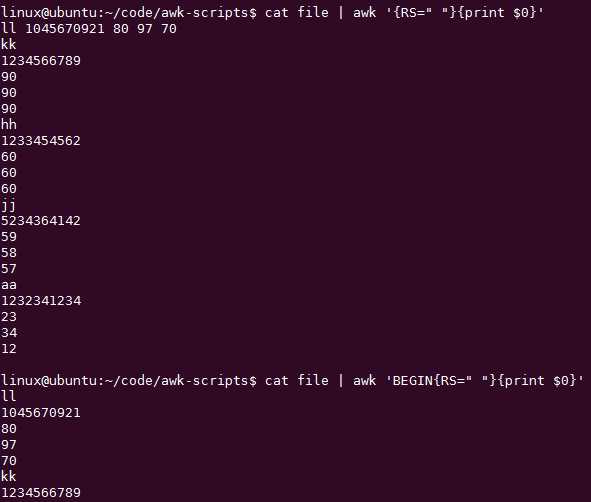
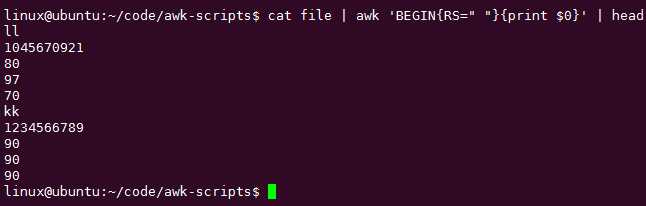
RS记录分隔符,默认是\\n,可见相当可配置化啊。
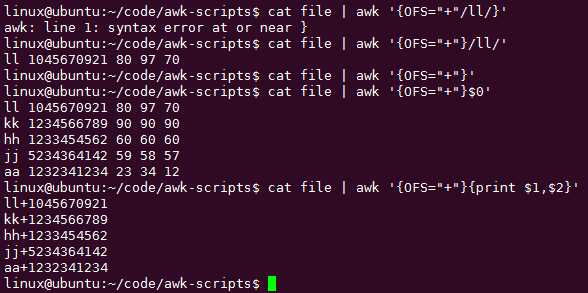
输出分隔符{OFS="+"},适用于分隔每行的多个输出而不是每行之间:
RS使用,一般在BEGIN里面赋值变量(内部或者外部)
嫌弃显示太多,显示前十行吧:
? ?
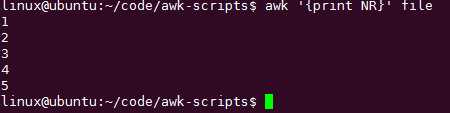
【awk取文件列】awk处理多个文件时默认是向下拼接的
如何组合多个文件中的多个列形成一个新文件:用数组承接新文件
用数组做,还记得pattern{action}吗!
awk ‘NR==FNR{a[NR]=$1}NR!=FNR{print a[FNR],$2}‘ file file1
awk会处理file和file1的10行内容,每次处理1行
处理file的行时,只有{a[NR=$1]}也就是a[1]=ll a[2]=kk
处理file1的行时,只有{print a[FNR], $2}执行,a[1] 列2
你没学的东西可以用笨方法实现哦:
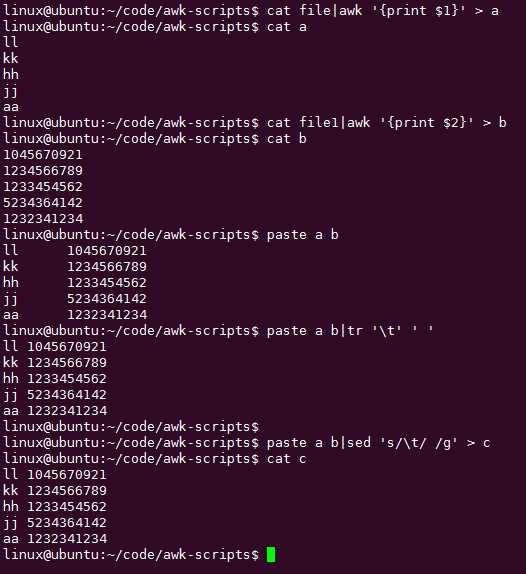
不用数组虽然麻烦,多做了些修订,也行!
? ?
【awk中for循环与技术】记住awk每次用‘{}‘处理一行,然后逐行重复。用END打印最后的结果。
想统计文件里面有多少个单词怎么办?
用wc厕所来算:

用awk来算:
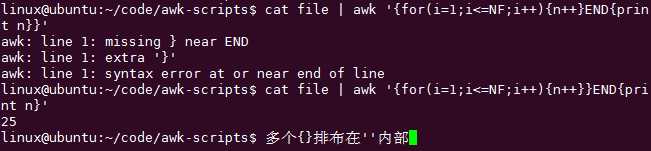
没有END的时候:
统计行数呢?
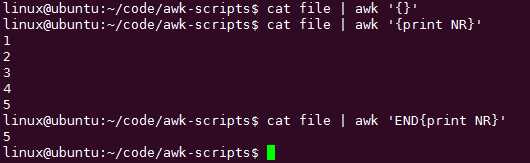
END表示文件全部处理完成后,awk就要退出前执行的意思。
? ?
如何统计某个单词在文件中出现的次数呢?因为单词两边是空白分隔的嘛,所以就逐行然后逐字段匹配嘛?
cat /root/pwb/tmp/md5/check.sh | awk ‘{for(i=1;i<=NF;i++){if($i=="echo"){n++}}}END{print n}‘

上面这个n为空嘛,所以打印了空行。
? ?
【awk中对列累加】
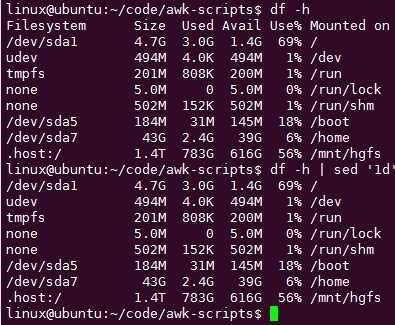
命令 df -h 可以查看硬盘使用率情况:
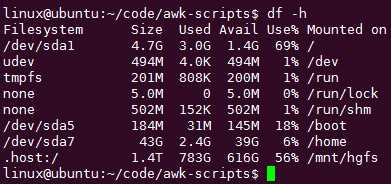
awk ‘‘无输出,因为无处理嘛
awk ‘/\\/dev\\/sda/‘ 正则默认过滤出每一行pattern

注意转义字符
-F 指定每行字段的分隔符
现在我们要把上面的数字字段给分隔出来:
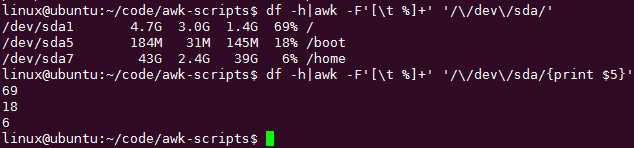
上面这是比较常用的用法,可以用来检测某个值啊!
df -hi 查看inode
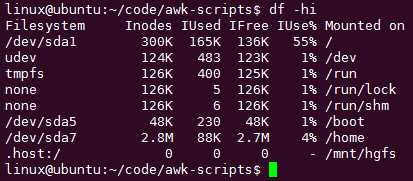
inode存目录,满了就要清理小文件了,所以你要检测使用资源的情况。
iblock存内容
所以上面取磁盘利用率的脚步同样可以用来检测inode资源使用率
用sed丢弃第一行 sed ‘1d‘
统计某个列的和:
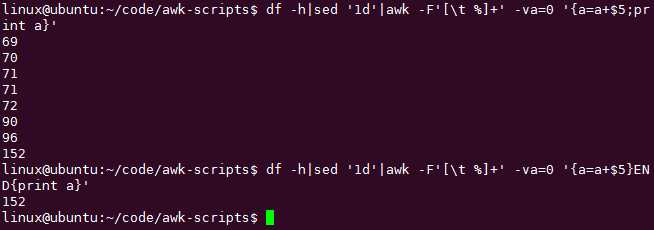
不定义变量直接用即可,如果初始值也是0的话:

? ?
【awk中删除文件后四行】
seq 10 > 10.txt
如何删除文件尾部四行?
sed ‘$d‘ 删最后一行
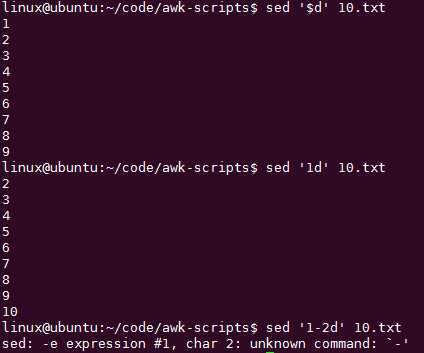
用awk怎么做?
这里利用了awk读取多个相同文件的技巧:
NR==FNR{表示处理第一个文件}NR!=FNR{表示处理第二文件也就是第一个文件}
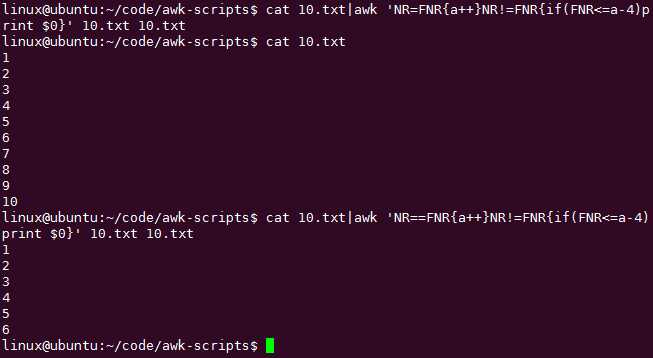
思路比较傻瓜化,先知道行数嘛。
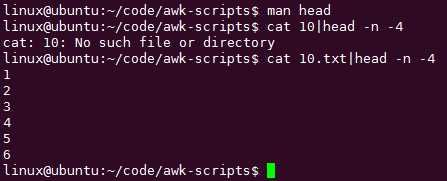
这儿还有个利用head的方法,这类命令的功能是很强大的,它几乎考虑了所有情况,如果认真看man手册的话:cat 10.txt|head -n -4 显然效率高多了,sed也可以,但是不会:
? ?
? ?
【awk最后总结】
- 记得把命令放到{}内,if也放{}里面
- pattern不需要放{}内,放{}前面就可以了
- 正则也是pattern
- awk本身就相当于一个行循环,$i就相当于内部元素循环
- 字符后者外部变量要放到双引号""里面
- 变量是字符串默认是空如果未定义的话
- 对于任意一个文件,不是标准的表格形式,所以用内置变NF NR
- {}内部嵌套就好比块语句嵌套了
- awk也是一种编程语言,是弱类型的,所以不要声明,直接用变量即可
- 可以处理相同的文件多次
- NF和NR容易混淆,老师当时学也是背了好久,所以技术在于坚持积累
? ?
打印整个文件:
1就是一个模式,默认打印出来整个文件:
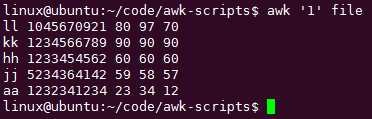
改成0没反应:

替换并打印:
cat file|awk ‘{$1="lx"}‘
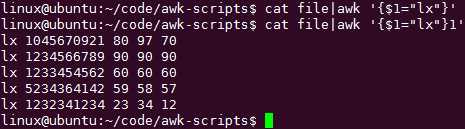
相当于:
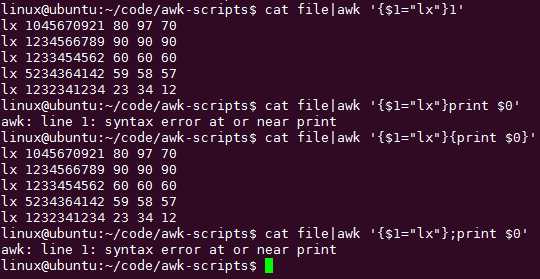
缩写而已,不要看懵逼了!
? ?
用awk代替grep,不就是正则过滤每行么:区别是grep有彩色

提取IP:

? ?
NF\\NR\\FNR
? ?
算CPU占用率之和:
? ?
看视频时候短时间学习一个知识点,不过如果学习的话还是看书好一点,毕竟视频都是浓缩过的。
? ?
以上是关于《AWK 基础入门讲解实战视频课程》笔记的主要内容,如果未能解决你的问题,请参考以下文章
CSDN学霸课表——从应用解析到基础实战,大数据入门晋级课程推荐