python学习之路web框架
Posted MoHan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习之路web框架相关的知识,希望对你有一定的参考价值。
WEB框架的本质
python的WEB框架分为两大类:
1、自己写socket,自己处理请求
2、基于wsgi(Web Server Gateway Interface WEB服务网关接口),自己处理请求
众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。
看下面的代码是WEB最本质的WEB框架(自己写的socket,自己处理的请求)
#!/usr/bin/env python
#coding:utf-8
import socket
def handle_request(client):
#接收请求
buf = client.recv(1024)
#返回信息
client.send("HTTP/1.1 200 OK\\r\\n\\r\\n")
client.send("Hello, lili")
def main():
#创建sock对象
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#监听80端口
sock.bind((\'localhost\',8010))
#最大允许排队的客户端
sock.listen(5)
#循环
while True:
#等待用户的连接,默认accept阻塞当有请求的时候往下执行
connection, address = sock.accept()
#把连接交给handle_request函数
handle_request(connection)
#关闭连接
connection.close()
if __name__ == \'__main__\':
main()
上述通过socket来实现了其本质,而对于真实开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理。应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。这样,服务器程序就需要为不同的框架提供不同的支持。这样混乱的局面无论对于服务器还是框架,都是不好的。对服务器来说,需要支持各种不同框架,对框架来说,只有支持它的服务器才能被开发出的应用使用。这时候,标准化就变得尤为重要。我们可以设立一个标准,只要服务器程序支持这个标准,框架也支持这个标准,那么他们就可以配合使用。一旦标准确定,双方各自实现。这样,服务器可以支持更多支持标准的框架,框架也可以使用更多支持标准的服务器。
WSGI(Web Server Gateway Interface)是一种规范,它定义了使用python编写的web app与web server之间接口格式,实现web app与web server间的解耦。python标准库提供的独立WSGI服务器称为wsgiref
#!/usr/bin/env python
#coding:utf-8
from wsgiref.simple_server import make_server
def RunServer(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html\')])
return \'<h1>Hello, web!</h1>\'
if __name__ == \'__main__\':
httpd = make_server(\'\', 8000, RunServer)
print "Serving HTTP on port 8000..."
httpd.serve_forever()
#接收请求
#预处理请求(封装了很多http请求的东西)
当请求过来后就执行RunServer这个函数。
OK 下面看WEB框架图(Socket & 处理请求的函数)
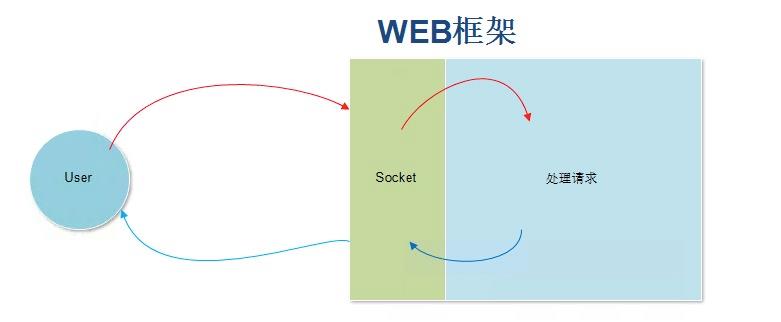
这两类WEB框架的区别是一个是自己写socket,一个是基于wsgi。
- 自己写socket,自己处理请求的代表框架是Tornado(还有就是Tronado有两种模式,可以通过修改配置让它使用自己写的socket也可以基于wsgi)
- 基于WSGI的WEB框架代表就是django
自定义框架
1、通过python标准库提供的wsgiref模块开发一个自己的Web框架
#!/usr/bin/env python
#coding:utf-8
from wsgiref.simple_server import make_server
def RunServer(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html\')])
return \'<h1>Hello,django!</h1>\'
if __name__ == \'__main__\':
httpd = make_server(\'\', 8000, RunServer)
print "Serving HTTP on port 8000..."
httpd.serve_forever()
当我们访问的时候,访问任何的url都会显示,Hello,django,其他网站则是根据用户输入URL的不同返回给用户不同的html.
既然是根据用户输入的URL的不同来返回不同的内容,我们就需要获取用户的内容。
#!/usr/bin/env python
#coding:utf-8
from wsgiref.simple_server import make_server
def RunServer(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html\')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ[\'PATH_INFO\']
print request_url
#2 根据URL做不同的相应
#print environ #这里可以通过断点来查看它都封装了什么数据
if request_url == \'/home/index\':
return "Hello Home"
elif request_url == \'/login\':
return "welcome to login our site. "
else:
return \'<h1>404!</h1>\'
if __name__ == \'__main__\':
httpd = make_server(\'\', 8000, RunServer)
print "Serving HTTP on port 8000..."
httpd.serve_forever()
用户的请求少还好,如果比较多使用if这种方式就不可行了,我们可以采用如下方法来实现:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
from wsgiref.simple_server import make_server
\'\'\'可以进行拆分---这一部分可以给框架使用者,按照定义的格式来操作\'\'\'
def index():
return \'index\'
def login():
return \'login\'
#1 定义一个列表,上面定义函数
url_list = [
#这里吧URL和函数做一个对应
(\'/index/\',index),
(\'/login/\',login),
]
########################################################################
\'\'\'这一部分可以单独拿出来,作为框架开发者,框架使用\'\'\'
def RunServer(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html\')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ[\'PATH_INFO\']
#2 根据URL做不同的相应
#print environ #这里可以通过断点来查看它都封装了什么数据
#循环这个列表
for url in url_list:
#如果用户请求的url和咱们定义的rul匹配
if request_url == url[0]:
print url
return url[1]()
#执行里面的方法
else:
#url_list列表里都没有返回404
return \'404\'
if __name__ == \'__main__\':
httpd = make_server(\'\', 8000, RunServer)
print "Serving HTTP on port 8000..."
httpd.serve_forever()
2、模板引擎
上一步骤中,对于所有的login、index均返回给用户浏览器一个简单的字符串,而实际的Web请求中一般会返回一个复杂的符合HTML规则的字符串,所以我们将要返回给用户的HTML写在指定文件中,然后再返回。
#index.html
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<h1>Index</h1>
</body>
</html>
#login
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<form>
<input type="text" />
<input type="text" />
<input type="submit" />
</form>
</body>
</html>
#!/usr/bin/env python
#-*- coding:utf-8 -*-
from wsgiref.simple_server import make_server
def index():
#读取html并返回
data = open(\'html/index.html\').read()
return data
def login():
#读取html并返回
data = open(\'html/login.html\').read()
return data
#1 定义一个列表,上面定义函数
url_list = [
#这里吧URL和函数做一个对应
(\'/index/\',index),
(\'/login/\',login),
]
def RunServer(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html\')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ[\'PATH_INFO\']
#2 根据URL做不同的相应
#print environ #这里可以通过断点来查看它都封装了什么数据
#循环这个列表
for url in url_list:
#如果用户请求的url和咱们定义的rul匹配
if request_url == url[0]:
print url
return url[1]()
#执行里面的方法
else:
#url_list列表里都没有返回404
return \'404\'
if __name__ == \'__main__\':
httpd = make_server(\'\', 8000, RunServer)
print "Serving HTTP on port 8000..."
httpd.serve_forever()
对于上述代码,虽然可以返回给用户HTML的内容以现实复杂的页面,但是还是存在问题:如何给用户返回动态内容?
- 自定义一套特殊的语法,进行替换
- 使用开源工具jinja2,遵循其指定语法
index.html 遵循jinja语法进行替换、循环、判断
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!--general replace-->
<h1>{{ name }}</h1>
<h1>{{ age }}</h1>
<h1>{{ time }}</h1>
<!--for circular replace-->
<ul>
{% for iterm in user_list %}
<li>{{ iterm }}</li>
{% endfor %}
</ul>
<!--if else judge-->
{% if num == 1%}
<h1>1111</h1>
{% else %}
<h1>2222</h1>
{% endif %}
</body>
</html>
#web.py
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import time
from wsgiref.simple_server import make_server
from jinja2 import Template
def index():
data = open(\'html/index.html\').read()
template = Template(data)
result = template.render(
name = \'luotianshuai\',
age = \'18\',
time = str(time.time()),
user_list = [\'tianshuai\',\'tim\',\'shuaige\'],
num = 1
)
#同样是替换为什么用jinja,因为他不仅仅是文本的他还支持if判断 & for循环 操作
#这里需要注意因为默认是的unicode的编码所以设置为utf-8
return result.encode(\'utf-8\')
def login():
#读取html并返回
data = open(\'html/login.html\').read()
return data
#1 定义一个列表,上面定义函数
url_list = [
#这里吧URL和函数做一个对应
(\'/index/\',index),
(\'/login/\',login),
]
def RunServer(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html\')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ[\'PATH_INFO\']
#2 根据URL做不同的相应
#print environ #这里可以通过断点来查看它都封装了什么数据
#循环这个列表
for url in url_list:
#如果用户请求的url和咱们定义的rul匹配
if request_url == url[0]:
print url
return url[1]()
#执行里面的方法
else:
#url_list列表里都没有返回404
return \'404\'
if __name__ == \'__main__\':
httpd = make_server(\'\', 8000, RunServer)
print "Serving HTTP on port 8000..."
httpd.serve_forever()
遵循jinja2的语法规则,其内部会对指定的语法进行相应的替换,从而达到动态的返回内容,对于模板引擎的本质,参考武Sir老师一篇博客:白话tornado源码之褪去模板外衣的前戏
参考文章:
http://www.cnblogs.com/luotianshuai/p/5258572.html
http://www.cnblogs.com/wupeiqi/articles/5237672.html
以上是关于python学习之路web框架的主要内容,如果未能解决你的问题,请参考以下文章