Redis(li)
Posted 为爱奔跑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis(li)相关的知识,希望对你有一定的参考价值。
一、Redis基础介绍
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。不同的是redis会周期性把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。关于性能方面,redis也有一个不错的表现:官方的bench-mark数据:测试完成了50个并发执行100000个请求;设置和获取的值是一个256字节字符串;Linux box是运行Linux 2.6结果:写的速度是110000次/s,读的速度是81000次/s 。
// 安装步骤: $ wget http://redis.googlecode.com/files/redis-2.4.7.tar.gz $ tar zxvf redis-2.4.7.tar.gz $ cd redis-2.4.7 $ make
make命令执行完成后,会在当前目录下生成本个可执行文件,分别是redis-server、redis-cli、redis-benchmark、redis-stat,它们的作用如下:
- redis-server:Redis服务器的daemon启动程序
- redis-cli:Redis命令行操作工具。当然,你也可以用telnet根据其纯文本协议来操作
- redis-benchmark:Redis性能测试工具,测试Redis在你的系统及你的配置下的读写性能
- redis-stat:Redis状态检测工具,可以检测Redis当前状态参数及延迟状况。
服务端启动:
src/redis-server
客户端连接:
src/redis-cli
例子:
redis> set name helloword! OK redis> get name "helloword!"

更多命令行使用可以借助help。客户端编码方式:首先引入二方包。
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.2.1</version> </dependency>
API文档示例:http://tool.oschina.net/apidocs/apidoc?api=jedis-2.1.0
Redis存储中的key值不限长度,可以适用一些模糊查询或匹配场景。
二、Redis列表改造
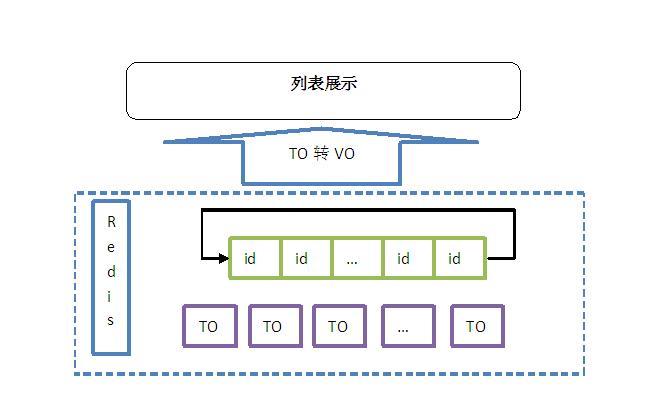
性能确实很高:现在海选列表页是基于对Redis的强依赖,只读redis不读DB,如果redis没有记录或者挂了就直接返回空记录页面。在存储的优化方面,是采取直接的VO存放在redis中,上层把海选商品的id放到redis的List中做分页的索引,因为redis的列表是基于Linked list实现的,所以分页索引时间复杂度为O(S+N),S为偏移量start,N为指定区间内元素的数量,但也很快的,现在海选列表的响应时间为30ms。
http://redis.readthedocs.org/en/latest/index.html这里有各种redis的命令分析及复杂度。
Redis的数据结构及对应的操作很丰富。List的操作很不错(这次主要是用了List),这次的列表分页就是基于List的range接口实现的,可以取从start坐标到stop坐标之间range的值。在做海选列表的分页时会遇到一个小问题,因为List不支持批量的set,所以只能一个一个的push进去,但这样会导致id列表不断的变化,虽然整个过程完成得很快,但如果数量达到1k或以上的时候这种变化还是会体现到前端页面影响用户,但redis提供了一种rename的机制,这样我们在列表变化时可以先一个一个的push到一个tmp中,待push完成后再一次性的rename为正式key,这样的马上切换可以保证列表的变化不影响到前端用户。

总结:redis的操作很丰富,但也有缺陷,不过我们只要将这些丰富的命令组合一下基本上就可以很好地补充这些缺陷点。对代码的入侵。正因为redis有丰富的数据结构及操作,没有像tair那样可以用一个annotation就可以解决,所以,redis的接口会对工程的代码有一定的影响,目前只能做到在VO层的隔离。
对redis的强依赖,通过任务保证数据的实时:这次的改造尝试了另一种使用Cache的方式,就是实时的刷数据到redis(1分钟一次)这样做的好处是:
- 修改商品1分钟生效,解决了运营修改商品后要待缓存失效了才生效,以前的方式,如果是详情页还可以马上清缓存,但如果是按分页进行缓存的话,不知道这个商品在第几页,很难清,这样会造成列表页与详情页不一致的情况
- 无论运营怎样修改,都不会造成对前端用户的影响,先前首页出现过运营修改商品缓存失效后出现繁忙页面的现象,但这次海选的优化可以避免这种现象但也有不好的地方:
- 1分钟要批量读一次DB,对DB也是有点压力的
- 这种方式在凌晨没人访问的时候是一种浪费,不知有没有些更绿色一点的同步机制?大家有什么建议呢?
一些缺点:n 线上的监控要完善,如key的qps,value占的空间大小,最后有后台操作线上的KV,这样以后作为参考对一些请求次数很高的key进行优化(考虑放本地缓存等);。n 关于过期时间的操作比较不方便,ValueCommand中的multiSet接口没有过期时间参数,而单独set一个value时是有的,这点比较奇怪,而且其他的命令,在处理过期时间方面很多都要采用TedisManager来做。
跳表算法:这次在使用redis时学习了一个新的平衡数据结构---跳表,实现快速的插入和查询。

其原理和实现的复杂度比红黑树平衡树之类的都要简单。参考博客如下:
- http://kenby.iteye.com/blog/1187303
- http://www.cxphp.com/?p=241
- http://www.searchtb.com/2011/05/redis-storage.html
三、Redis命令
// Redis安装 tar zxvf redis-2.8.9.tar.gz cd redis-2.8.9 #直接make 编译 make #可使用root用户执行`make install`,将可执行文件拷贝到/usr/local/bin目录下。这样就可以直接敲名字运行程序了。 make install 启动
#加上`&`号使redis以后台程序方式运行 ./redis-server & 检测
#检测后台进程是否存在 ps -ef |grep redis #检测6379端口是否在监听 netstat -lntp | grep 6379 #使用`redis-cli`客户端检测连接是否正常 ./redis-cli 127.0.0.1:6379> keys * (empty list or set) 127.0.0.1:6379> set key "hello world" OK 127.0.0.1:6379> get key "hello world" 停止 #使用客户端 redis-cli shutdown #因为Redis可以妥善处理SIGTERM信号,所以直接kill -9也是可以的 kill -9 PID
四、
五、
以上是关于Redis(li)的主要内容,如果未能解决你的问题,请参考以下文章