重新开始学习javase_IO
Posted 傻瓜不傻108
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重新开始学习javase_IO相关的知识,希望对你有一定的参考价值。
一,认识IO
通过数据流、序列化和文件系统提供系统输入和输出。
流是一个很形象的概念,当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。这时候你就可以想象数据好像在这其中“流”动一样。
二,Java流的分类
- 按流向分:
- 输入流: 程序可以从中读取数据的流。
- 输出流: 程序能向其中写入数据的流。
- 按数据传输单位分:
- 字节流: 以字节为单位传输数据的流
- 字符流: 以字符为单位传输数据的流
- 按功能分:
- 节点流: 用于直接操作目标设备的流
- 过滤流: 是对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能。
三,File(转:http://blog.csdn.net/shichexixi/article/details/5563605)
刚开始我们主要是和文件打交道,故先了解一下File吧:用java对文件的操作
File类并没有指明怎样从文件读取或向文件存储;它只是描述了文件本身的属性。File对象用来获取或处理与磁盘文件相关的信息,例如权限,时间,日期和目录路径。此外,File还浏览子目录层次结构。很多程序中文件是数据的根源和目标。尽管它们在小应用程序中因为安全原因而受到严格限制,文件仍是存储固定和共享信息的主要资源。Java中的目录当成File 对待,它具有附加的属性——一个可以被 list( )方法检测的文件名列表。
参照api文档File有4个构造函数中常用的3个:
@Test public void test03() throws IOException { //File(String pathname) 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。 File f=new File("D:\\\\a.txt"); // f.createNewFile();//在指定路径下创建名为a.txt的txt文件 f.mkdir();//在指定路径下创建名为a.txt文件夹 File f2=new File("D:\\\\a\\\\b\\\\c"); f2.mkdirs();//在指定路径下创建a文件夹,a中有b文件夹,b中又有c文件夹 }
@Test public void test04() throws IOException { //File(String parent, String child) 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。/ File f=new File("D:\\\\a","a.txt");//指定的D:\\\\a下面创建a.txt文件,D:\\\\a必须存在 f.createNewFile(); }
@Test public void test05() throws IOException { //File(File parent, String child) 根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。 File f=new File("D:\\\\b"); if(!f.exists()){ f.mkdir(); } File f2=new File(f,"a.txt"); // f2.mkdir();//在b文件珓下创建a.txt的文件夹。这点File(String parent, String child)做实验好像没效果 f2.createNewFile();//在b文件珓下创建a.txt的文件 }
注意:不同的系统中文件的路径分隔符是不一样的。在window中为“\\”,在unix中为”/“,为了具有跨平台性可以File.separator:(不过在window中使用“/”也可以使用)
@Test public void test07 () throws IOException{ File f=new File("D:"+File.separator+"a.txt"); f.createNewFile(); }
再来看看File类中常见的方法:
import java.io.File; class FileDemo { static void p(String s) { System.out.println(s); } public static void main(String args[]) { File f1 = new File("/java/COPYRIGHT"); p("File Name: " + f1.getName()); p("Path: " + f1.getPath()); p("Abs Path: " + f1.getAbsolutePath()); p("Parent: " + f1.getParent()); p(f1.exists() ? "exists" : "does not exist"); p(f1.canWrite() ? "is writeable" : "is not writeable"); p(f1.canRead() ? "is readable" : "is not readable"); p("is " + (f1.isDirectory() ? "" : "not" + " a directory")); p(f1.isFile() ? "is normal file" : "might be a named pipe"); p(f1.isAbsolute() ? "is absolute" : "is not absolute"); p("File last modified: " + f1.lastModified()); p("File size: " + f1.length() + " Bytes"); } }


File Name: COPYRIGHT Path: /java/COPYRIGHT Abs Path: /java/COPYRIGHT Parent: /java exists is writeable is readable is not a directory is normal file is absolute File last modified: 812465204000 File size: 695 Bytes
@Test public void test09() throws IOException { /*创建并写入数据*/ File f = new File("D:\\\\a.txt"); RandomAccessFile file=new RandomAccessFile(f, "rw");//用读写方式创建并打开文件;如果以只读r模式打开,则要求文件已存在 String name="zhangsan"; int age=30; file.writeBytes(name); file.writeInt(age); name="lisi "; age=40; file.writeBytes(name); file.writeInt(age); name="wangwu "; age=50; file.writeBytes(name); file.writeInt(age); file.close(); }
读:
@Test public void test10() throws IOException { /*创建并写入数据*/ File f = new File("D:\\\\a.txt"); RandomAccessFile file=new RandomAccessFile(f, "r");//如果以只读r模式打开 String name=null; int age=0; file.skipBytes(12);//跳过12个字节,即"zhangsan30" byte[] b=new byte[8];//读8个字节,即:"lisi "; file.read(b); name=new String(b); System.out.println(name); age=file.readInt(); System.out.println(age); file.seek(0);//指针放在文件开始 file.read(b);//读8个字段"zhangsan" System.out.println(new String(b)); }
五,IO
- 字节流(操作byte)
- InputStream
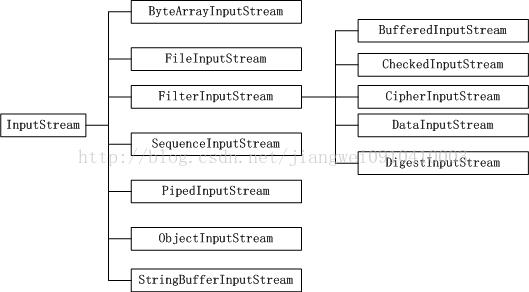
方法:
available():返回stream中的可读字节数,inputstream类中的这个方法始终返回的是0,这个方法需要子类去实现。
close():关闭stream方法,这个是每次在用完流之后必须调用的方法。
read():方法是读取一个byte字节,但是返回的是int。
read(byte[]):一次性读取内容到缓冲字节数组
read(byte[],int,int):从数据流中的哪个位置offset开始读长度为len的内容到缓冲字节数组
skip(long):从stream中跳过long类型参数个位置
//做实验请单独做。流只能用一次 @Test public void test11() throws IOException { //a.txt中的内容abcdefghijklabcdefghijklabcdefghijkl 36个英文 InputStream in=new FileInputStream("D:\\\\a.txt"); System.out.println(in.available());//36 byte[] b=new byte[36]; // for(int i=0;i<b.length;i++){ // b[i]=(byte) in.read(); // } // String str=new String(b); // System.out.println(str+"-----length:"+str.length());//abcdefghijklabcdefghijklabcdefghijkl b=new byte[36]; in.read(b); System.out.println(new String(b));//abcdefghijklabcdefghijklabcdefghijkl // b=new byte[8]; // in.read(b, 0, 8);//读入前8个 // System.out.println(new String(b));//abcdefgh // in.skip(24);//一个36个,跳过24个 // in.read(b);//读入剩下的12个 // System.out.println(new String(b));//abcdefghijkl }
下面还有三个方法:
mark(int):用于标记stream的作用
markSupported():返回的是boolean类型,因为不是所有的stream都可以调用mark方法的,这个方法就是用来判断stream是否可以调用mark方法和reset方法
reset():这个方法和mark方法一起使用的,让stream回到mark的位置。
mark接口的官方文档解释:
“在此输入流中标记当前的位置。对 reset 方法的后续调用会在最后标记的位置重新定位此流,以便后续读取重新读取相同的字节。
readlimit 参数告知此输入流在标记位置失效之前允许读取许多字节。
mark 的常规协定是:如果方法 markSupported 返回 true,则输入流总会在调用 mark 之后记住所有读取的字节,并且无论何时调用方法 reset ,都会准备再次提供那些相同的字节。但是,如果在调用 reset 之前可以从流中读取多于 readlimit 的字节,则根本不需要该流记住任何数据。”
reset接口的官方文档解释:
将此流重新定位到对此输入流最后调用 mark 方法时的位置。
reset 的常规协定是:
如果方法 markSupported 返回 true,则:
如果创建流以来未调用方法 mark,或最后调用 mark 以来从该流读取的字节数大于最后调用 mark 时的参数,则可能抛出 IOException。
如果未抛出这样的 IOException,则将该流重新设置为这种状态:最近调用 mark 以来(或如果未调用 mark,则从文件开始以来)读取的所有字节将重新提供给 read 方法的后续调用方,后接可能是调用 reset 时的下一输入数据的所有字节。
如果方法 markSupported 返回 false,则:
对 reset 的调用可能抛出 IOException。
如果未抛出 IOException,则将该流重新设置为一种固定状态,该状态取决于输入流的特定类型和其创建方式的固定状态。提供给 read 方法的后续调用方的字节取决于特定类型的输入流。
简而言之就是:
调用mark方法会记下当前调用mark方法的时刻,InputStream被读到的位置。
调用reset方法就会回到该位置。@Test public void test12() throws IOException { // a.txt中的内容abcdefghijklabcdefghijklabcdefghijkl 36个英文 InputStream in = new FileInputStream("D:\\\\a.txt"); System.out.println(in.markSupported());//FileInputStream不支持marked,false in=new BufferedInputStream(in); System.out.println(in.markSupported());//包装后支持,true byte[] b=new byte[36]; in.mark(13);//在起点调用mark方法,并在以后读取的13个字节长度内是有效的.问题是我改成2也是这样的效果,感觉是不是理解错了,请看下面的备注* for(int i=0;i<12;i++){ b[i]=(byte) in.read(); if(i==8){//当读到第9个,也就是i的时候,reset到起点的地方,继续读abc in.reset(); } } System.out.println(new String(b));//abcdefghiabc }
备注:
事实上,mark在JAVA中的实现是和缓冲区相关的。只要缓冲区够大,mark后读取的数据没有超出缓冲区的大小,mark标记就不会失效。如果不够大,mark后又读取了大量的数据,导致缓冲区更新,原来标记的位置自然找不到了。
因此,mark后读取多少字节才失效,并不完全由readlimit参数确定,也和BufferedInputStream类的缓冲区大小有关。 如果BufferedInputStream类的缓冲区大小大于readlimit,在mark以后只有读取超过缓冲区大小的数据,mark标记才会失效。简言之,BufferedInputStream类调用mark(int readlimit)方法后读取多少字节标记才失效,是取readlimit和BufferedInputStream类的缓冲区大小两者中的最大值,而并非完全由readlimit确定。这个在JAVA文档中是没有提到的。
-
ByteArrayInputStream 把内存中的一个缓冲区作为InputStream使用
要使用ByteArrayInoutStream, 必须将一个byte数组传入,然后就是以操作流的方式操作这个数组,感觉用处不大@Test public void test13() { String str="my name is wangyang, I\'m come from anhui province"; ByteArrayInputStream is=new ByteArrayInputStream(str.getBytes());//就这样就把str以字节流的形式,写入了内存,ByteArrayInputStream(byte[], int begin, int end)一个道理 }
ByteArrayOutputStream类是在创建它的实例时,程序内部创建一个byte型别数组的缓冲区,然后利用ByteArrayOutputStream实例向数组中写入或读出byte型数据。在网络传输中我们往往要传输很多变量,我们可以利用ByteArrayOutputStream把所有的变量收集到一起,然后一次性把数据发送出去(感觉有点像StringBuffer)。具体用法如下:@Test public void test13() throws IOException { String str="I"; ByteArrayOutputStream out=new ByteArrayOutputStream(); out.write(str.getBytes());//向内存中堆加数据 out.write(new String(" Love ").getBytes());//向内存中堆加数据 out.write(new String("you").getBytes());//向内存中堆加数据 System.out.println(out.toString());//一次性取出 }
- FileInputStream是操作文件,从文件中读取:之前做InputStream的例子都是以此类为例,这里便不再说明
- PipedInputStream 用于线程之前数据的交互:可以想像有一根管子,管子中一边往里面输入水,另一端就可以接水
PipedOutputStream这边是灌入水的一端:
class OutPutInWater implements Runnable{ PipedOutputStream os=null; public OutPutInWater() { this.os=new PipedOutputStream(); } public PipedOutputStream getPipedOutputStream(){ return this.os; } @Override public void run() { String str="the water pour into the piped from PipedOutputStream"; try { this.os.write(str.getBytes());//向管道中写入 } catch (IOException e) { e.printStackTrace(); }finally { try { os.close(); } catch (IOException e) { e.printStackTrace(); } } } }
PipedInputStream:得到水的一端:
class InputGetWater implements Runnable{ PipedInputStream in=null; public InputGetWater() { this.in=new PipedInputStream(); } public PipedInputStream getPipedInputStream(){ return this.in; } @Override public void run() { int i=0; byte[] b=new byte[1024]; try { i=in.read(b); } catch (IOException e) { e.printStackTrace(); }finally { try { in.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } System.out.println(new String(b,0,i)+": this is PipedInputStream"); } }
测试:
@Test public void test19() throws IOException { OutPutInWater send=new OutPutInWater(); InputGetWater get=new InputGetWater(); // get.getPipedInputStream().connect(send.getPipedOutputStream()); send.getPipedOutputStream().connect(get.getPipedInputStream());//操作时使用PipedOutputStream中的connect方法就可以连接两线程中的管道 new Thread(send).start(); new Thread(get).start(); }
结果:
the water pour into the piped from PipedOutputStream: this is PipedInputStream - StringBufferInputStream(String str)将字符串作为流来操作,已经不推荐使用
- SequenceInputStream(InputStream in1,InputStream in2)将两个输入流合并成一个输入流;注意:这里对其的读取要一个字节一个字节的读,否则只会输出第一个流中的内容
@Test public void test17() throws IOException { ByteArrayInputStream in1=new ByteArrayInputStream(new String("I").getBytes()); ByteArrayInputStream in2=new ByteArrayInputStream(new String(" love you").getBytes()); SequenceInputStream in=new SequenceInputStream(in1, in2); byte[] b=new byte[30]; in.read(b); System.out.println(new String(b));//只打印了一个“I” }
下面才是正确的操作
@Test public void test16() throws IOException { ByteArrayInputStream in1=new ByteArrayInputStream(new String("I").getBytes()); ByteArrayInputStream in2=new ByteArrayInputStream(new String(" love you").getBytes()); SequenceInputStream in=new SequenceInputStream(in1, in2); ByteArrayOutputStream out=new ByteArrayOutputStream(); int a=0; while((a=in.read())!=-1){ out.write(a); } System.out.println(out.toString()); }
- ObjectInputStream
这里就要谈到对象的序列化了,所谓的对象序列化,就是将对象变成二进制数据,java中一个对象要实现序列化需要实现Serializable接口,这里先提出,后面作补充:
为了把对象序列化的说明的更彻底,下面的例子内容有点多:
//声明第一个可序列化的类 class TestSerializable2 implements Serializable{ private static final long serialVersionUID = 1751286614906177469L;//注意这一步是必须的。序列化过程中这个Id是作为标识的 private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "TestSerializable2 [name=" + name + ", age=" + age + "]"; } } //声明第二个可序列化的类,并合并第一个类 class TestSerializable implements Serializable{ private static final long serialVersionUID = 5771508478484056470L;//注意这一步是必须的。序列化过程中这个Id是作为标识的 private String name; private int age; private TestSerializable2 t; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public TestSerializable2 getT() { return t; } public void setT(TestSerializable2 t) { this.t = t; } @Override public String toString() { return "TestSerializable [name=" + name + ", age=" + age + ", t=" + t + "]"; } }
测试:
@Test public void test21() throws IOException, ClassNotFoundException { //设置属性 TestSerializable2 t=new TestSerializable2(); t.setName("wangyang2"); t.setAge(24); TestSerializable t2=new TestSerializable(); t2.setAge(23); t2.setName("wangyang"); t2.setT(t); //向内存中写入对象 ByteArrayOutputStream buff=new ByteArrayOutputStream(); ObjectOutputStream out=new ObjectOutputStream(buff); out.writeObject(t2); out.close(); //将t2置空 t2=null; //读取内存中的对象,并让t2指向读出的对象 ObjectInputStream in=new ObjectInputStream(new ByteArrayInputStream(buff.toByteArray())); t2=(TestSerializable) in.readObject(); System.out.println(t2);//TestSerializable [name=wangyang, age=23, t=TestSerializable2 [name=wangyang2, age=24]] in.close(); }
- BufferedInputStream(就是一个包装类)
BufferedInputStream 的作用是为另一个输入流添加一些功能,例如,提供“缓冲功能”以及支持“mark()标记”和“reset()重置方法”。
BufferedInputStream 本质上是通过一个内部缓冲区数组实现的。例如,在新建某输入流对应的BufferedInputStream后,当我们通过read()读取输入流的数据时,BufferedInputStream会将该输入流的数据分批的填入到缓冲区中。每当缓冲区中的数据被读完之后,输入流会再次填充数据缓冲区;如此反复,直到我们读完输入流数据位置。
@Test public void test01() throws FileNotFoundException { BufferedOutputStream out=new BufferedOutputStream(new FileOutputStream("D:\\\\a.txt",true)); BufferedInputStream in=new BufferedInputStream(new FileInputStream("D:\\\\a.txt")); }
- DataInputStream数据处理的流
DataInputStream能以一种与机器无关(当前操作系统等)的方式,直接从地从字节输入流读取JAVA基本类型和String类型的数据,常用于网络传输等
@Test public void test02() throws Exception { DataOutputStream out=new DataOutputStream(new FileOutputStream("D:/a.txt",true)); out.writeInt(1000); out.writeShort((short)12); out.writeByte((byte)12); out.writeDouble(1212121212); out.writeChar(\'a\'); out.writeLong(1212122L); out.writeBoolean(true); out.writeFloat(12.2222f); out.writeUTF("wangyang"); DataInputStream in=new DataInputStream(new FileInputStream("D:/a.txt")); System.out.println(in.readInt()); System.out.println(in.readShort()); System.out.println(in.readByte()); System.out.println(in.readDouble()); System.out.println(in.readChar()); System.out.println(in.readLong()); System.out.println(in.readBoolean()); System.out.println(in.readFloat()); System.out.println(in.readUTF()); // 1000 // 12 // 12 // 1.212121212E9 // a // 1212122 // true // 12.2222 // wangyang }
- 打印流
在整个IO系统对,对于输出来说,打印流是最为方便的流的。分为字节打印流和字符打印流,当然也可以打印任何类型的数据了,其构造方法也很丰富!
@Test public void test03() throws FileNotFoundException { PrintWriter w=new PrintWriter("D:\\\\a.txt"); w.println("wangyang"); w.println("wangyang01"); w.println("wangyang02"); w.println("wangyang03"); w.close();//close时会刷新出wk中的内容 }
打印流的格式化
@Test public void test04() throws IOException { PrintWriter w=new PrintWriter(System.out); String name="wangshushu"; int age=12; char a=\'a\'; float f=12.3f; w.printf("my name is %s, I\'m %d years old,this is an %c and that is %f",name,age,a,f); //my name is wangshushu, I\'m 12 years old,this is an a and that is 12.300000 // w.flush(); w.close(); }
- 压缩流:Zip***,Jar***,GZip***
- ZipFile ZipInputStream ZipOutputStream ZipEntity
对文件操作(压缩)
@Test public void test05() throws Exception { //D:\\\\a.avi大小为62018kb,用快压压缩后是61309kb File f=new File("D:\\\\a.avi"); File zipf=new File("D:\\\\b.zip"); System.out.println(f.getName()); ZipOutputStream zout=new ZipOutputStream(new FileOutputStream(zipf)); //为zip里面的文件赋一个名字 zout.putNextEntry(new ZipEntry(f.getName())); byte[] b=new byte[1024]; FileInputStream in=new FileInputStream(f); int i=0; while((i=in.read(b))!=-1){ zout.write(b); } in.close(); zout.close(); //得到的b.zip为61281kb,看到压缩效率还不错^_^ }
对文件夹操作:注意要给每个内部文件设置名称(压缩)
@Test public void test06() throws Exception{ //D:\\\\a是一个文件夹,下面有a.avi,a,txt两个文件 File f=new File("D:\\\\a"); File fzip=new File("D:\\\\a.zip"); ZipEntry z=null; FileInputStream in=null; byte[] b=new byte[1024]; ZipOutputStream zout=new ZipOutputStream(new FileOutputStream(fzip)); if(f.isDirectory()){ File[] fs=f.listFiles(); for(File a: fs){ z=new ZipEntry(a.getName()); zout.putNextEntry(z);//把里面的文件放入流中 int i=0; in=new FileInputStream(a); while((i=in.read(b))!=-1){ zout.write(b); } in.close(); } } zout.close(); }
对文件操作(解压)
@Test public void test07() throws Exception { File f=new File("D:\\\\s.zip"); ZipFile zf=new ZipFile(f); ZipEntry a=zf.getEntry("settings.xml"); InputStream inputStream = zf.getInputStream(a); FileOutputStream out=new FileOutputStream(new File("D:\\\\a.xml")); int te=0; while((te=inputStream.read())!=-1){ out.write(te); } inputStream.close(); out.close(); }
对文件夹操作(解压)
@Test public void test08() throws Exception { File f=new File("D:\\\\a.zip"); ZipFile zf=new ZipFile(f); ZipInputStream in=new ZipInputStream(new FileInputStream(f)); ZipEntry entity=null; File out=null; InputStream is=null; OutputStream os=null; byte[] b=new byte[1024]; while((entity=in.getNextEntry())!=null){ out=new File("D:\\\\"+entity.getName()); is=zf.getInputStream(entity); os=new FileOutputStream(out); int i=0; while((i=in.read(b))!=-1){ os.write(b); } is.close(); os.close(); } in.close(); }
- ZipFile ZipInputStream ZipOutputStream ZipEntity
- InputStream
以上是关于重新开始学习javase_IO的主要内容,如果未能解决你的问题,请参考以下文章