Hadoop伪分布式环境搭建验证
Posted junneyang 的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop伪分布式环境搭建验证相关的知识,希望对你有一定的参考价值。
Hadoop伪分布式环境搭建:
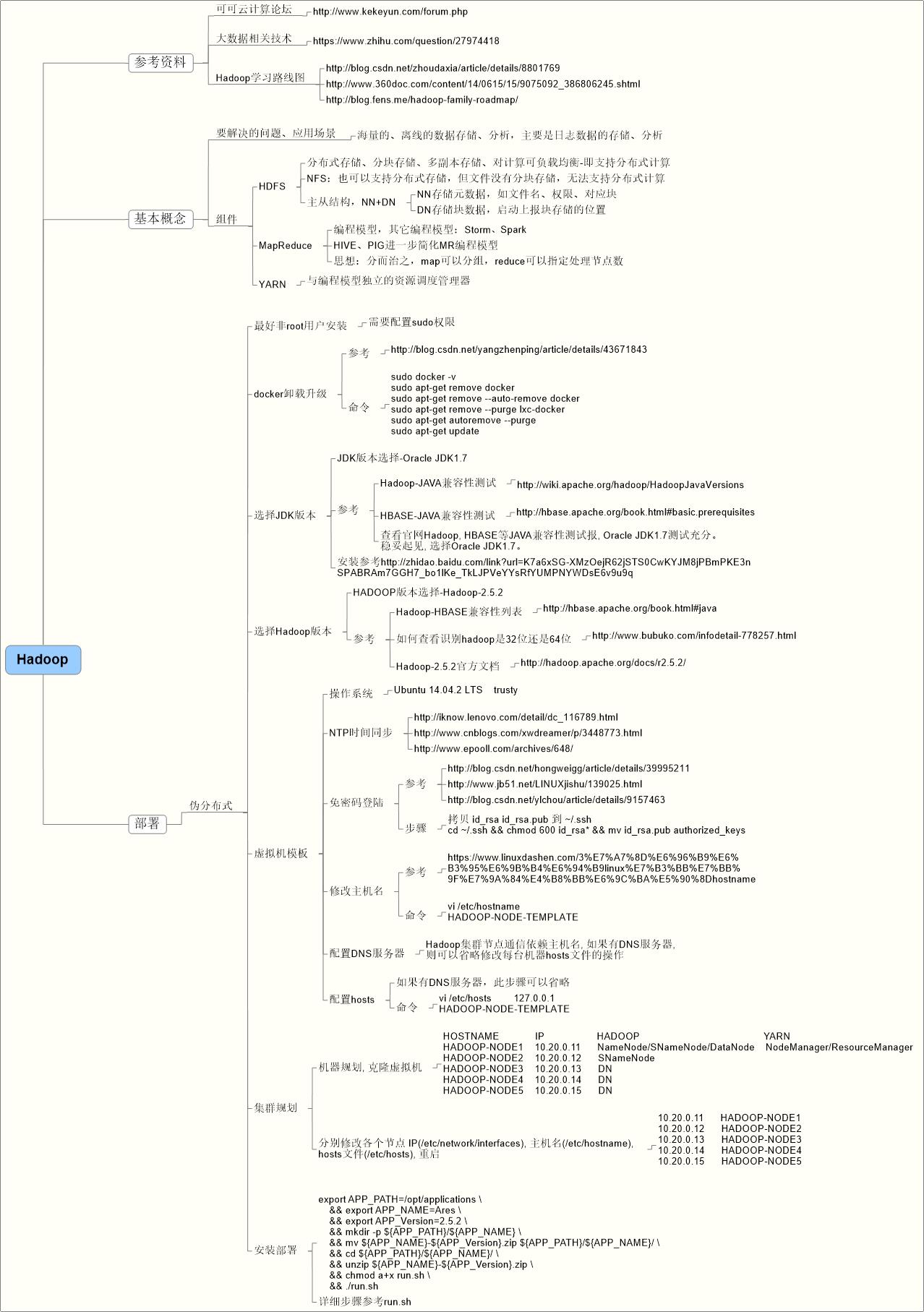
自动部署脚本:
#!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares # 安装apt依赖包 apt-get update -y \\ && apt-get install supervisor -y \\ && apt-get install python-dev python-pip libmysqlclient-dev -y # 安装pip、python依赖 pip install --upgrade pip \\ && pip install -r ./build-depends/pip-requirements/requirements.txt # 安装JDK tar -xzvf ./build-depends/jdk-package/jdk-7u60-linux-x64.tar.gz \\ && ln -s jdk1.7.0_60/ jdk # 配置JAVA环境变量 echo -e \'\\n\' >> /etc/profile echo \'# !!!No Modification, This Section is Auto Generated by \'${APP_NAME} >> /etc/profile echo \'export JAVA_HOME=\'${APP_PATH}/${APP_NAME}/jdk >> /etc/profile echo \'export JRE_HOME=${JAVA_HOME}/jre\' >> /etc/profile echo \'export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar\' >> /etc/profile echo \'export PATH=${PATH}:${JAVA_HOME}/bin:${JRE_HOME}/bin\' >> /etc/profile source /etc/profile && java -version # 安装Hadoop tar -xzvf ./build-depends/hadoop-package/hadoop-2.5.2.tar.gz \\ && ln -s hadoop-2.5.2 hadoop # hadoop-env.sh配置JAVA_HOME mv ./hadoop/etc/hadoop/hadoop-env.sh ./hadoop/etc/hadoop/hadoop-env.sh.bak \\ && cp -rf ./build-depends/hadoop-conf/hadoop-env.sh ./hadoop/etc/hadoop/ \\ && sed -i "25a export JAVA_HOME=${APP_PATH}/${APP_NAME}/jdk" ./hadoop/etc/hadoop/hadoop-env.sh # core-site.xml配置 mv ./hadoop/etc/hadoop/core-site.xml ./hadoop/etc/hadoop/core-site.xml.bak \\ && python ./build-utils/configueUpdate/templateInvoke.py ./build-depends/hadoop-conf/core-site.xml ./hadoop/etc/hadoop/core-site.xml # hdfs-site.xml配置 mv ./hadoop/etc/hadoop/hdfs-site.xml ./hadoop/etc/hadoop/hdfs-site.xml.bak \\ && python ./build-utils/configueUpdate/templateInvoke.py ./build-depends/hadoop-conf/hdfs-site.xml ./hadoop/etc/hadoop/hdfs-site.xml # mapred-site.xml配置 python ./build-utils/configueUpdate/templateInvoke.py ./build-depends/hadoop-conf/mapred-site.xml.template ./hadoop/etc/hadoop/mapred-site.xml # yarn-site.xml配置 mv ./hadoop/etc/hadoop/yarn-site.xml ./hadoop/etc/hadoop/yarn-site.xml.bak \\ && python ./build-utils/configueUpdate/templateInvoke.py ./build-depends/hadoop-conf/yarn-site.xml ./hadoop/etc/hadoop/yarn-site.xml # slaves, 即DataNode配置 mv ./hadoop/etc/hadoop/slaves ./hadoop/etc/hadoop/slaves.bak DataNodeList=(`echo ${DataNodeList} | tr ";" "\\n"`) for DataNode in ${DataNodeList}; do echo ${DataNode} >> ./hadoop/etc/hadoop/slaves done # 配置Hadoop环境变量 echo -e \'\\n\' >> /etc/profile echo \'# !!!No Modification, This Section is Auto Generated by \'${APP_NAME} >> /etc/profile echo \'export HADOOP_HOME=\'${APP_PATH}/${APP_NAME}/hadoop >> /etc/profile echo \'export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin\' >> /etc/profile source /etc/profile && hadoop version # Namenode格式化 # hadoop namenode -format -force hdfs namenode -format -force # 启动hdfs、yarn stop-dfs.sh && start-dfs.sh && jps stop-yarn.sh && start-yarn.sh && jps # hdfs测试 # hadoop fs -put ./build-depends/jdk-package/jdk-7u60-linux-x64.tar.gz hdfs://HADOOP-NODE1:9000/ hdfs dfs -put ./build-depends/jdk-package/jdk-7u60-linux-x64.tar.gz hdfs://HADOOP-NODE1:9000/ # hadoop fs -get hdfs://HADOOP-NODE1:9000/jdk-7u60-linux-x64.tar.gz . hdfs dfs -get hdfs://HADOOP-NODE1:9000/jdk-7u60-linux-x64.tar.gz . rm -rf jdk-7u60-linux-x64.tar.gz # mapred测试 hadoop jar ./hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar pi 5 10 # word-count测试 touch word-count.txt \\ && echo "hello world" >> word-count.txt \\ && echo "hello tom" >> word-count.txt \\ && echo "hello jim" >> word-count.txt \\ && echo "hello kitty" >> word-count.txt \\ && echo "hello baby" >> word-count.txt # hadoop fs -put word-count.txt hdfs://HADOOP-NODE1:9000/ # hadoop fs -rm hdfs://HADOOP-NODE1:9000/word-count.txt hadoop fs -mkdir hdfs://HADOOP-NODE1:9000/word-count hadoop fs -mkdir hdfs://HADOOP-NODE1:9000/word-count/input # hadoop fs -mkdir hdfs://HADOOP-NODE1:9000/word-count/output # hadoop fs -rmdir hdfs://HADOOP-NODE1:9000/word-count/output hadoop fs -put word-count.txt hdfs://HADOOP-NODE1:9000/word-count/input hadoop jar ./hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar wordcount hdfs://HADOOP-NODE1:9000/word-count/input hdfs://HADOOP-NODE1:9000/word-count/output hadoop fs -ls hdfs://HADOOP-NODE1:9000/word-count/output hadoop fs -cat hdfs://HADOOP-NODE1:9000/word-count/output/part-r-00000 # supervisord 配置文件 #cp ${APP_PATH}/supervisor.conf.d/*.conf /etc/supervisor/conf.d/ # start supervisord nodaemon # /usr/bin/supervisord --nodaemon #/usr/bin/supervisord
运行脚本:
# 此处描述应用运行命令使用方法. export APP_PATH=/opt/applications export APP_NAME=Ares export APP_Version=2.5.2 # 单节点-伪分布式 #HOSTNAME IP HDFS YARN #HADOOP-NODE1 10.20.0.11 NameNode/SNameNode/DataNode NodeManager/ResourceManager export NameNode_HOST=HADOOP-NODE1 export NameNode_RPCPort=9000 export NameNode_HTTP_PORT=50070 export SNameNode_HOST=HADOOP-NODE1 export SNameNode_HTTP_PORT=50090 export SNameNode_HTTPS_PORT=50091 export HDFS_Replication=1 export YARN_RSC_MGR_HOST=HADOOP-NODE1 export YARN_RSC_MGR_HTTP_PORT=8088 export YARN_RSC_MGR_HTTPS_PORT=8090 export DataNodeList=\'HADOOP-NODE1\' mkdir -p ${APP_PATH}/${APP_NAME} \\ && mv ${APP_NAME}-${APP_Version}.zip ${APP_PATH}/${APP_NAME}/ \\ && cd ${APP_PATH}/${APP_NAME}/ \\ && unzip ${APP_NAME}-${APP_Version}.zip \\ && chmod a+x run.sh \\ && ./run.sh
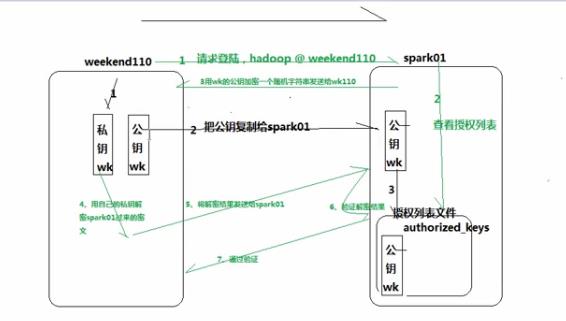
ssh免密码登录过程:
以上是关于Hadoop伪分布式环境搭建验证的主要内容,如果未能解决你的问题,请参考以下文章