从软件工程的角度写机器学习5——SVM(支持向量机)实现
Posted 夕阳叹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从软件工程的角度写机器学习5——SVM(支持向量机)实现相关的知识,希望对你有一定的参考价值。
SVM实现
SVM在浅层学习时代是主流监督学习算法,在深度学习时代也往往作为最后一个预测层使用(说深度学习击败了SVM的纯属扯淡)。
SVM算法总体流程
本系列文章旨在讲解机器学习算法的工程实现方法,不在于推导数学原理。因此想深入了解原理的请移步去看《支持向量机通俗导论(理解SVM的三层境界)》:
http://www.cnblogs.com/v-July-v/archive/2012/06/01/2539022.html
对于急于求成的小伙伴,建议就看下面描述的基本过程,知其然,不必知其所以然。
按照上篇文章所规定的工程框架,所有操作尽量以矩阵为单元执行:
http://blog.csdn.net/jxt1234and2010/article/details/51926758
预测
SVM是一个监督学习算法,其训练时输入自变量矩阵X(N个m维向量)和因变量矩阵Y(这里要求Y中元素取值为两类之一:{A、B}),输出模型M。
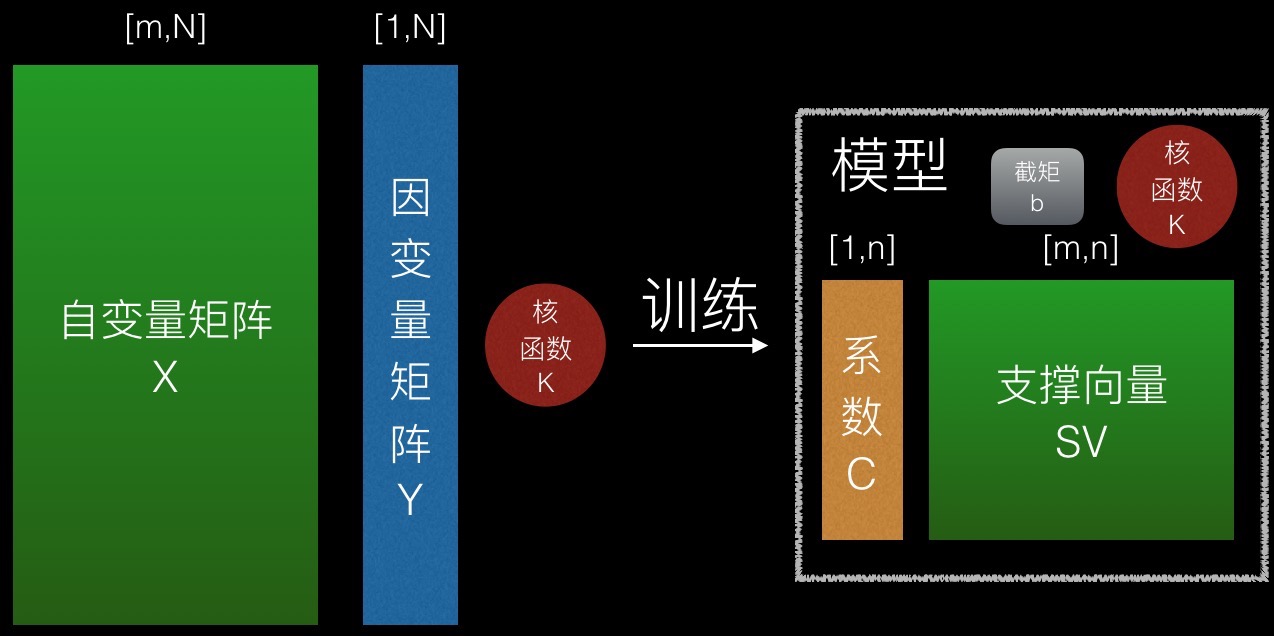
如图所示,一个SVM模型包含如下要素:
1、支撑向量集SV
一个n行m列的矩阵,表示n个m维向量。
支撑向量集是在训练过程中,挑选出自变量矩阵的有效行形成的。
2、系数C与截距b
系数矩阵为n行1列的矩阵,它与支撑向量集一一对应。
截距为一个常数。
3、核函数K
核函数为实现了如下接口的一个类
class IKernel
{
public:
virtual Matrix* vCompute(const Matrix* X1, const Matrix* X2) const = 0;
};其中X1为 [m, n1]的矩阵,X2为[m, n2]的矩阵,输出结果为 [n2, n1] 的矩阵。
具体的核函数运算参考:
http://blog.csdn.net/xiaowei_cqu/article/details/35993729
预测时输入自变量矩阵X(待预测向量集)和模型M,输出预测值矩阵YP。
X为[m,p]的矩阵,表示p个待预测的m维向量。
YP为[1,p]的矩阵,表示p个预测值。
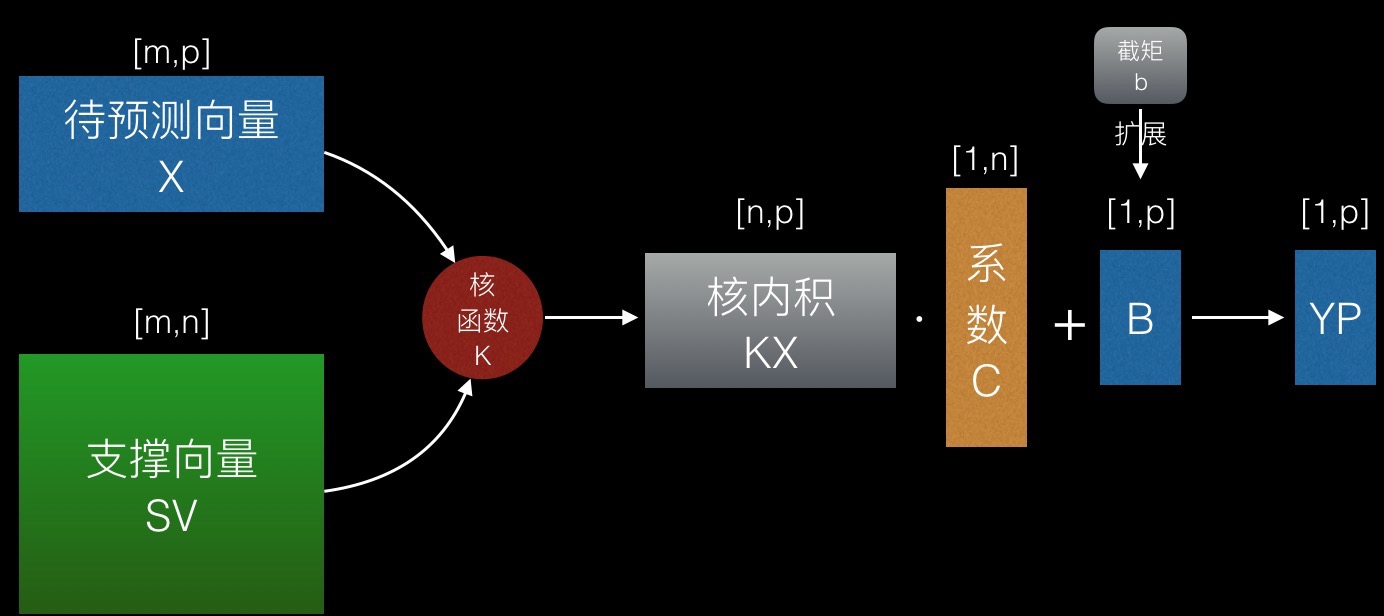
第一步,由核函数算出SV和X的核内积矩阵KX。KX(i, j)即第i个支撑向量和第j个待预测向量的核内积。
第二步,用KX和对应的系数矩阵相乘,加上截距,得到YP。
预值出来的YP只是一个实数,不表示具体类别,使用时需要对每个值作类别转化,大于0转为类别A,小于0转为类别B。
预测过程可以用一个公式简单表示:
YP=K((M.SV), X)∙(M.C)+B训练过程
在SVM模型中,核函数是事先指定的,支撑向量是从自变量向量集中抽取的,因此训练过程主要就是计算系数矩阵和截矩。
因变量矩阵Y假定其元素只有A、B两个取值
训练之前先要预处理,将因变量矩阵Y中A转为1,B转为-1。
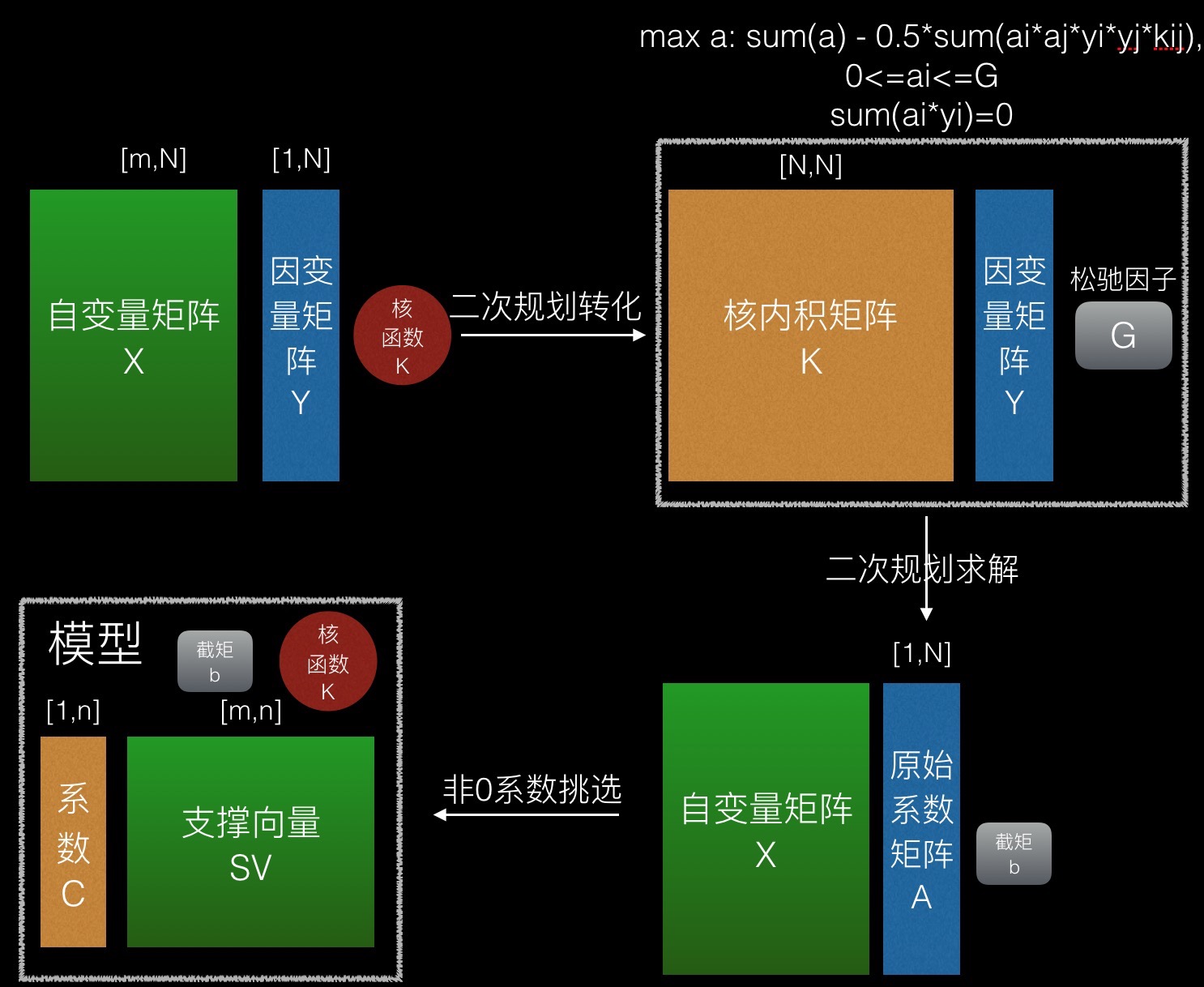
如图所示,SVM模型的创建分三步:
1、创建二次规划(主要是计算核内积矩阵)
2、解二次规划,得到截矩b和原始系数矩阵A,原始系数矩阵为[1,N]的矩阵,其系数值与自变量矩阵中的向量一一对应。
3、把原始系数矩阵中非零系数及对应的自变量矩阵中的向量挑选出来,形成系数矩阵C及其对应的支撑向量集SV。
第3步只是一个简单的挑选过程,因此经常被一带而过,往往只有自己去实现,才能记得。
熟悉SVM的朋友可以看出,按上面这个流程这个方式写出来的SVM,并没有交叉验证、核函数选择及参数调优及多分类的功能。主要是考虑到这些特性并非SVM专属,应当在算法抽象层实现,以便给其他监督学习算法共享。
基础算法实现及相应的类
训练类
SVM是一种监督学习算法,对应的训练类定义为SVMLearner
class SVMLearner
{
public:
virtual IPredictor* vLearn(Matrix* X, Matrix* Y) const;
private:
double mG;//对应松驰因子G
IKernel* mK;//核函数
ISVMProgramSolver* mSolver;//二次规划求解器
};二次规划生成
规划描述
以上是关于从软件工程的角度写机器学习5——SVM(支持向量机)实现的主要内容,如果未能解决你的问题,请参考以下文章