python学习-模块
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习-模块相关的知识,希望对你有一定的参考价值。
模块基本知识
模块是实现某个功能的代码集合
模块分为三种:
内置模块:安装 python 时自带的模块
自定义模块:之前我们所写的所有函数也都可以被当做自定义模块
第三方模块:非安装 python 时自带的模块
1、模块的导入
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入
导入模块的方法:
import module #导入模块的所有内容 from module.xx import xx # 导入模块的某一个功能 from module.xx import xx as rename # 导入模块的某一个功能,并将该功能重命名 from module.xx import * # 导入模块的所有内容,不建议使用
导入模块是让解释器在当前的搜索路径中寻找模块文件。
搜索路径是解释器会先进行搜索所有目录的列表,搜索路径是在 python 编译或安装的时候确认的,安装新的库应该也会修改。
搜索路径被存储在 sys 模块中的 path 变量
>>> import sys >>> print(sys.path) [‘‘, ‘/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python35.zip‘, ‘/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python3.5‘, ‘/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin‘, ‘/usr/local/Cellar/python3/3.5.0/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload‘, ‘/usr/local/lib/python3.5/site-packages‘]
sys.path 输出的是一个列表,第一个元素为空字符串,代表当前目录。
因此若在当前目录下创建与要导入的模块同名的文件,就会把要导入的模块屏蔽掉【没验证通过】
既然 sys.path 是一个列表,那么也就可以进行修改,当 sys.path 中没有我们需要导入模块的路径时,可以通过 list.append 添加。
常用模块
1、sys
用于提供对 python 解释器进行相关的操作
sys.argv # 命令行参数List,第一个元素是程序本身路径 sys.exit(n) # 退出程序,正常退出时exit(0) sys.version # 获取Python解释程序的版本信息 sys.maxint # 最大的Int值 【python3 取消了】 sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform # 返回操作系统平台名称 sys.stdin # 输入相关 sys.stdout # 输出相关 sys.stderror # 错误相关
输出进度百分比
def view_bar(num, total): rate = float(num) / float(total) rate_num = int(rate * 100) r = ‘\\r%d%%‘ % (rate_num, ) sys.stdout.write(r) sys.stdout.flush() if __name__ == ‘__main__‘: for i in range(0, 100): time.sleep(1) view_bar(i, 100)
2、random
生成随机验证码
def create_verification_code(): li = [] for i in range(4): r = random.randrange(0,5) if r == 1 or r == 3: num = random.randrange(0,10) li.append(str(num)) else: temp = random.randrange(65,91) li.append(chr(temp)) code = "".join(li) return code
3、序列号
python 中的序列号模块有两个
- json 用于【字符串】和 【python 基本数据类型】间转换
- pickle 用于【python 特有类型】和【python 所有类型】之间的转换
json 和 pickle 都提供了 4 个方法:dumps, dump, loads, load
import json data = {1:1,2:2,3:3} # dumps 方法将 python 的基本数据类型转换为字符串 j_str = json.dumps(data) # loads 方法将字符串转换为 python 的基本数据类型 dic = json.loads(j_str) # load 方法将文件中的字符串转换为 python 的基本数据类型 j_str = json.load(open(‘file‘)) # dump 方法将 python 的基本数据类型已字符串的格式写入文件 json.dump(data,open(‘file‘),‘w‘)
import pickle data = {1:1,2:2,3:3} # dumps 方法将 python 的基本数据类型转换为只有 python 能认识的特有字符串格式 p_str = pickle.dumps(data) # loads 方法将数据通过特有的转换方式转换为 python 的对象 dic = pickle.loads(p_str) # load 方法将文件中的内容通过特殊的方式转为 python 的对象 p_obj = pickle.load(open(‘file‘)) # dump 方法将 python 的对象通过特殊的转换方式存入文件 pickle.dump(data,open(‘file‘),‘w‘)
4、request
Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务


import urllib.request f = urllib.request.urlopen(‘https://www.baidu.com‘) result = f.read().decode(‘utf-8‘) print(result)
import urllib.request req = urllib.request.Request(‘http://www.baidu.com/‘) req.add_header(‘Referer‘, ‘http://www.python.org/‘) r = urllib.request.urlopen(req) result = r.read().decode(‘utf-8‘) print(result)
注:更多见Python官方文档:https://docs.python.org/3.5/library/urllib.request.html#module-urllib.request
Requests 是使用 Apache2 Licensed 许可证的 基于Python开发的HTTP 库,其在Python内置模块的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作。
1、安装模块
pip3 install requests
2、使用模块
# 无参数实例 import requests ret = requests.get(‘https://github.com/timeline.json‘) print(ret.url) print(ret.text) # 有参数实例 import requests payload = {‘key1‘: ‘value1‘, ‘key2‘: ‘value2‘} ret = requests.get("http://httpbin.org/get", params=payload) print(ret.url) print(ret.text)
# 基本POST实例 import requests payload = {‘key1‘: ‘value1‘, ‘key2‘: ‘value2‘} ret = requests.post("http://httpbin.org/post", data=payload) print(ret.text) # 发送请求头和数据实例 import requests import json url = ‘https://api.github.com/some/endpoint‘ payload = {‘some‘: ‘data‘} headers = {‘content-type‘: ‘application/json‘} ret = requests.post(url, data=json.dumps(payload), headers=headers) print(ret.text) print(ret.cookies)
requests.get(url, params=None, **kwargs) requests.post(url, data=None, json=None, **kwargs) requests.put(url, data=None, **kwargs) requests.head(url, **kwargs) requests.delete(url, **kwargs) requests.patch(url, data=None, **kwargs) requests.options(url, **kwargs) # 以上方法均是在此方法的基础上构建 requests.request(method, url, **kwargs)
更多requests模块相关的文档见:http://cn.python-requests.org/zh_CN/latest/
5、logging
用于便捷记录日志且线程安全的模块
import logging logging.basicConfig(filename=‘log.log‘, format=‘%(asctime)s - %(name)s - %(levelname)s - %(module)s[%(lineno)s]: %(message)s‘, datefmt=‘%Y-%m-%d %H:%M:%S %p‘, level=10) logging.debug(‘debug‘) logging.info(‘info‘) logging.warning(‘warning‘) logging.error(‘error‘) logging.critical(‘critical‘) # 通过 logging.log 直接传递日志级别,日志级别必须为 int 型 logging.log(10,‘log‘)
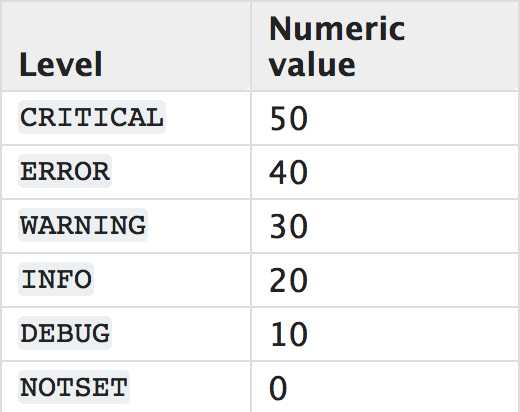
日志的级别以及级别对应的数字
只有记录日志的级别大于日志等级时内容才会被记录
日志的格式
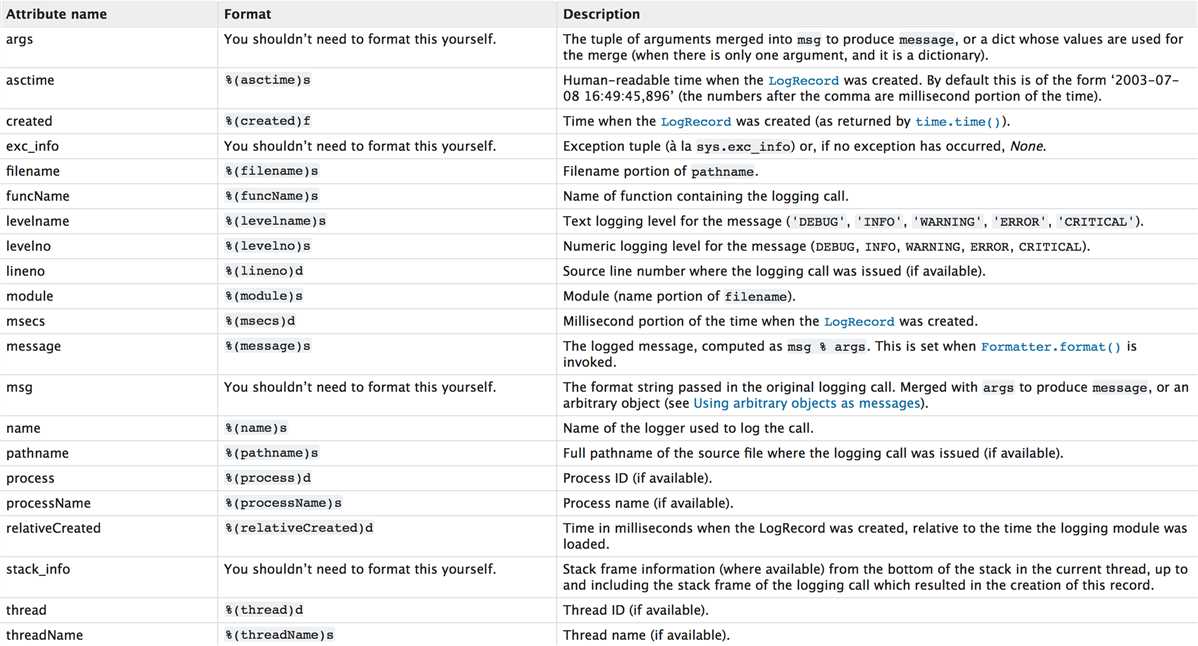
更多信息:https://docs.python.org/3/library/logging.html
对于上述记录日志的功能,只能将日志记录在单文件中,如果想要设置多个日志文件,logging.basicConfig将无法完成,需要自定义文件和日志操作对象。
import logging # 定义两个不同的日志文件句柄 file_handler1 = logging.FileHandler(filename=‘log1.log‘,mode=‘a‘,encoding=‘utf-8‘) fmt = logging.Formatter(fmt=‘%(asctime)s - %(name)s - %(levelname)s - %(module)s[%(lineno)s]: %(message)s‘) file_handler1.setFormatter(fmt) file_handler2 = logging.FileHandler(filename=‘log2.log‘,mode=‘a‘,encoding=‘utf-8‘) fmt = logging.Formatter() file_handler2.setFormatter(fmt) # 定义日志文件的名称以及级别,并将之前定义的文件句柄添加,日志的级别也可以通过 logger.setLevel(logging.DEBUG) 单独设置 logger = logging.Logger("WenChong",level=logging.DEBUG) logger.addHandler(file_handler1) logger.addHandler(file_handler2) # 日志会同时写入到两个文件 logger.error(‘aaaaaaaaa‘) logger.setLevel(logging.DEBUG)
6、time
时间有三种表现形式
时间戳 1970年1月1日之后的秒,即:time.time()
格式化字符串 2016-08-31 23:49:44, 即:time.strftime(‘%Y-%m-%d %H:%M:%S‘)
结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
import time print(time.time()) # 输出当前的时间戳 print(time.mktime(time.localtime())) # 将 struct_time 结构化时间转换为时间戳 print(time.localtime()) # 参数可为时间戳,将时间戳转换为 struct_time 结构化时间 print(time.strptime(‘2016-08-31‘, ‘%Y-%m-%d‘)) # 将格式化的时间转换为 struct_time 结构化时间 print(time.gmtime()) # 将时间戳转换为 struct_time 结构化时间,默认是 UTC print(time.ctime()) # 返回当前系统时间,参数为时间戳,默认为当前,输出为格式化时间 print(time.strftime(‘%Y-%m-%d‘)) # 将时间戳格式的时间转换为格式化时间,默认为当前时间 time.sleep() # 程序在此等待 N 秒
import datetime print(datetime.datetime.now()) # 返回当前时间 2016-09-01 00:11:35.628752 print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-09-01 print(datetime.datetime.now() + datetime.timedelta(3)) # 当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) # 当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 当前时间+30分 c_time = datetime.datetime.now() print(c_time.replace(year=2019,minute=3,hour=2)) # 时间替换
7、os
os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd os.curdir # 返回当前目录: (‘.‘) os.pardir # 获取当前目录的父目录字符串名:(‘..‘) os.makedirs(‘dir1/dir2‘) # 可生成多层递归目录 os.removedirs(‘dirname1‘) # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) # 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() # 删除一个文件 os.rename("oldname","new") # 重命名文件/目录 os.stat(‘path/filename‘) # 获取文件/目录信息 os.sep # 操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/" os.linesep # 当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n" os.pathsep # 用于分割文件路径的字符串 win下为分号,Linux下为冒号 os.name # 字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ os.system("bash command") # 运行shell命令,直接显示 os.environ # 获取系统环境变量 os.path.abspath(path) # 返回path规范化的绝对路径 os.path.split(path) # 将path分割成目录和文件名二元组返回 os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) # 返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) # 如果path是绝对路径,返回True os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
8、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
通过 md5 加密 admin 并返回一个数据
import hashlib # hashlib 的方法还有 sha1,sha256, sha384, sha512 m = hashlib.md5() m.update(bytes(‘admin‘,encoding=‘utf-8‘)) print(m.hexdigest())
md5 等加密是可以通过撞库的方式反解的,所以在加密的时候可以添加上自定义的字符串
import hashlib m = hashlib.md5(bytes(‘WenChong‘,encoding=‘utf-8‘)) m.update(bytes(‘admin‘,encoding=‘utf-8‘)) print(m.hexdigest())
python 内部的加密模块 hmac
import hmac m = hmac.new(bytes("WenChong",encoding=‘utf-8‘)) m.update(bytes(‘admin‘,encoding=‘utf-8‘)) print(m.hexdigest())
以上是关于python学习-模块的主要内容,如果未能解决你的问题,请参考以下文章
Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)(代码片段