实现一个边缘机器学习项目到底有多难?
Posted 金色小蜜蜂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实现一个边缘机器学习项目到底有多难?相关的知识,希望对你有一定的参考价值。
实现一个边缘机器学习项目到底有多难?
我们每天都要跟传感器打交道,如果你不相信的话,拿出手机,Google一下它里面配备了多少种传感器—加速度计,陀螺仪,压力传感器,……,或许还能发现很多你从未听过的名词。
这些传感器输出的信号都是独特的。理解它信号的含义,对信号进行处理,都需要有专业背景和经验。如果你的机器学习模型需要的数据正好来自这些传感器,通常意味着,你需要雇佣熟知传感器并且具有信号处理能力的机器学习工程师。
即便不考虑组建机器学习团队的成本和难度,进入项目开发流程,仍然还有很多难关需要克服,而这些经常成为被“忽略”的事实。
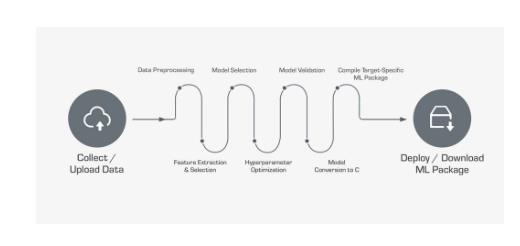
传统机器学习流程
对于机器学习工程师来说,除了传统软件开发工具之外,他们还需要使用多套开发工具来创建ML模型。就算已经有像Jupyter Notebook这样比较强大并且相对成熟的工具,但其目前也还存在着极大的局限性。虽然针对机器学习开发的新平台和工具层出不穷,但是目前还没有一个端到端的解决方案,让工程师们可以实现整套流程,从创建项目开始,一直到在嵌入式芯片上运行机器学习模型。此外,这些工具也需要工程师们花费额外的精力和时间来学习,并且会增加项目的管理成本和硬件及软件成本。
在开发机器学习模型的过程中,通常需要进行大量的实验来找到表现最好的模型,而且每一次不同的实验之间都可能存在很多变数。保证实验数据的可复现性非常重要,所以对于硬件,操作平台,模型配置,训练数据等等都需要做到精确的版本控制,这些都需要花费很多的精力和时间来完成。
就像在传统软件开发过程中,开发人员们从来没有摆脱过Bug的困扰,在机器学习开发中,类似的问题依然存在。不同的是,传统软件开发人员已经建立了一套测试和debug的最佳方式,然而,这些方式并不适合机器学习。当机器学习模型失败时,通常没有信息显示失败的原因和改进的方向。除此之外,造成失败的还有可能是一些“其他”因素,包括糟糕的训练数据等等,这让问题更难被排除。
有一个案例就是对这一问题最好的说明,Anders Arpteg在他与其他三位作者合著的《Software Engineering Challenges of Deep Learning》一文中提到,为了解决某个公司天气预测系统中重组后输出图像分辨率过低的问题,开发人员花费了2周时间,用不同的神经网络模型完成了几百次实验,才发现是由于pooling operation过于激进,导致分辨率在数据被编码之前就已经受损,而这一结果正是由于缺乏针对深度神经网络的debug调试工具。
而且这篇文章也明确指出,在如何简单和高效地构建一个高质量的可用于生产的机器学习系统上仍然需要更多的研究和努力。
从公司的角度来说,要构建一个复杂的机器学习模型,通常需要花费几天甚至几周的时间来训练,而且无法对结果做出预测,也无法预知如果模型出现问题,究竟需要花费多少时间来解决这些问题,那么构建这样一个模型的成本是非常高的。
即便对于一个已经部署的可用于生产的机器学习系统来说,保障它处于最新状态也需要花费大量的时间和努力。因为对一个成熟的机器学习系统来说,它一般会依赖许多不同的pipelines,这些pipelines可能是用不同的程序语言,格式和结构系统实现的,它们的改变,增加或者移除,甚至被弃用都是很常见的情况,因此要确保检测系统和日志系统能获取到这些信息。但这些成本通常也是很多公司在进行项目规划时可能不会考虑到的。
对于传统软件开发而言,一个相同的程序可以运行在不同的设备上,例如,Win10系统可以运行在成千上万台不同型号的电脑上(这里讨论的是理论可行性,不考虑为了让用户体验最优而要做的种种适配性工作),但是对于机器学习而言,通常每一种不同的设备都需要不同对待。
以预测性维护为例,如果汽车厂商要为发动机加入预测性维护功能,那么即便有2种不同型号的汽车使用的是同一种发动机,从理论上来说,这2种车型的发动机数据都需要单独采集和处理,进行特征提取,然后再进行模型训练,调参等步骤。
Qeexo在FingerSense(指关节技术)项目上也遇到过同样的问题,这项技术是在手机上执行机器学习推理,分辨手指、指关节等不同的输入方式,依靠的也是传感器数据。不同的手机型号会使用不同的硬件配置,一台手机上采集到的数据无法满足另一台不同型号手机的需求,所以每一个不同的手机型号都必须经历一次从采集数据开始到配置机器学习库的完整过程,再加上即便是同一个型号的手机,在很多部件也会使用多家供应商提供的不同产品,这又衍生出更多种不同的可能性。
以上种种问题也从一定程度上解释了为什么眼下AI成为了大公司追逐的游戏,因为对于中小型企业来说,尝鲜成本极高,而且一旦做错决定就很有可能给公司带来极大的危险,所以如何规避或者降低风险也就成为了领导者们首先需要考虑的问题。
也正是因为这些原因,自动化机器学习平台进入了很多公司的视野。将传统机器学习过程中的特征提取,模型选择,超参数优化,模型验证等等步骤通过自动化的方式来实现,极大地降低了普通企业在应用机器学习时的难度和所需的资源。Qeexo也基于自己的经验与需要,创建了Qeexo AutoML,利用传感器数据针对高度受限的环境快速创建机器学习解决方案。自动化机器学习到底是什么—这一问题,我们也会在之后的文章中进行详细的介绍。
以上是关于实现一个边缘机器学习项目到底有多难?的主要内容,如果未能解决你的问题,请参考以下文章