第一个爬虫
Posted hyocheong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一个爬虫相关的知识,希望对你有一定的参考价值。
(2)用get()函数访问一个网站20次,打印返回状态,text()内容,计算text()属性和content()属性所返回的网页内容长度。
import requests r=requests.get("https://www.so.com/") r.encoding="UTF-8" for i in range(20): print(r.status_code) print(r.text) print(len(r.content)) print(len(r.text))
 结果过长 这是开头部分
结果过长 这是开头部分
(3)
import re import requests from bs4 import BeautifulSoup a=‘<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="r"> <tr> <td>row1,cell 1</td> <td>row2,cell 2</td> </tr> </table> </html>‘ m=re.findall(‘[u4e00-u9fa5]+‘,a) s=BeautifulSoup(a) print(‘autor:Yong No:10‘) print(s.head) print(s.body) print(s.p) print(m)
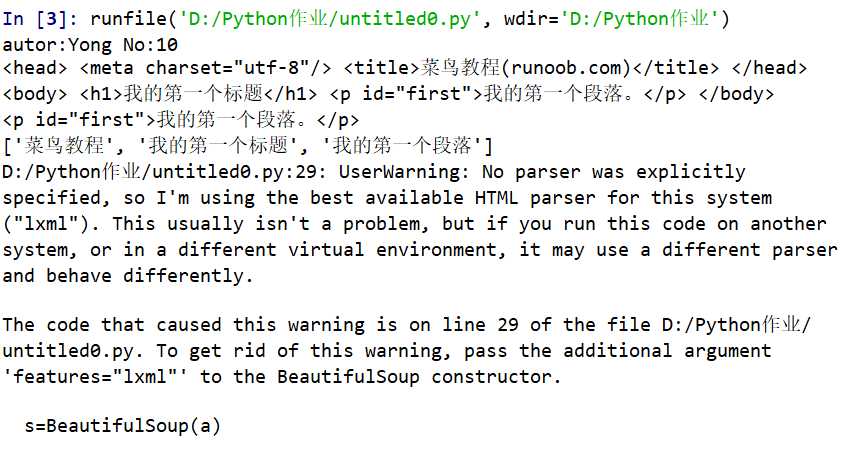
(4)爬取中国大学排名内容
import requests from bs4 import BeautifulSoup import bs4 from pandas import DataFrame def getHTML(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print("获取错误") def moveToList(ulist, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find(‘tbody‘).children: if isinstance(tr, bs4.element.Tag): tds = tr(‘td‘) ulist.append([tds[0].string, tds[1].string, tds[2].string]) def printHTML(ulist,num): tplt="{0:^6} {1:{3}^10} {2:<10}" print(tplt.format("排名", "学校名称", "省份",chr(12288))) for i in range(num): u=ulist[i] print(tplt.format(u[0], u[1], u[2],chr(12288))) pass def main(): url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html" html = getHTML(url) uinfo = [] moveToList(uinfo, html) frame=DataFrame(uinfo) printHTML(uinfo,20) main()

以上是关于第一个爬虫的主要内容,如果未能解决你的问题,请参考以下文章