第一个爬虫和测试
Posted Noraa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一个爬虫和测试相关的知识,希望对你有一定的参考价值。
一、完赛球赛程序,测试球赛程序,所有函数的测试结果。
from random import random def printIntro(): print(\'这个程序模拟两个队伍A和B的排球竞技比赛\') print(\'程序运行需要A和B的能力值(以0到1之间的小数表示)\') def getInputs(): a = eval(input(\'请输入队伍A的能力值(0-1):\')) b = eval(input(\'请输入队伍B的能力值(0-1):\')) n = eval(input(\'模拟比赛场次:\')) return a, b, n def simNGames(n, probA, probB): winsA, winsB = 0, 0 for i in range(n): scoreA, scoreB=simOneGame(probA, probB) if scoreA==1: winsB+=1 continue elif scoreA==3: winsA+=1 continue scoreA, scoreB = simOneGame5(probA, probB) if scoreA > scoreB: winsA += 1 else: winsB += 1 return winsA, winsB def simOneGame5(probA, probB): scoreA, scoreB =0, 0 serving = \'A\' while not gameOver5(scoreA, scoreB): if serving == \'A\': if random() > probA: scoreB += 1 serving = \'B\' else: scoreA += 1 else: if random() > probB: scoreA += 1 serving = \'A\' else: scoreB += 1 return scoreA, scoreB def simOneGame(probA, probB): scoreA, scoreB = 0, 0 for i in range(4): s1, s2=0, 0 while not gameOver(s1, s2): if random()<probA: s1+=1 elif random()<probB: s2+=1 if s1>s2: scoreA+=1 else: scoreB+=1 return scoreA, scoreB def gameOver5(c, d): return (c>=15 and c-d>=2) or (d>=15 and d-c>=2) def gameOver(scoreA, scoreB): return (scoreA>=25 and scoreA-scoreB>=2) or (scoreB>=25 and scoreB-scoreA>=2) def printSummary(n,winsA, winsB): print("竞技分析开始,共模拟{}场比赛".format(n)) print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA, winsA/n)) print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB, winsB/n)) def main(): printIntro() probA, probB,n= getInputs() winsA, winsB = simNGames(n, probA, probB) printSummary(n,winsA, winsB) try: main() except: print("error")
测试结果正常:
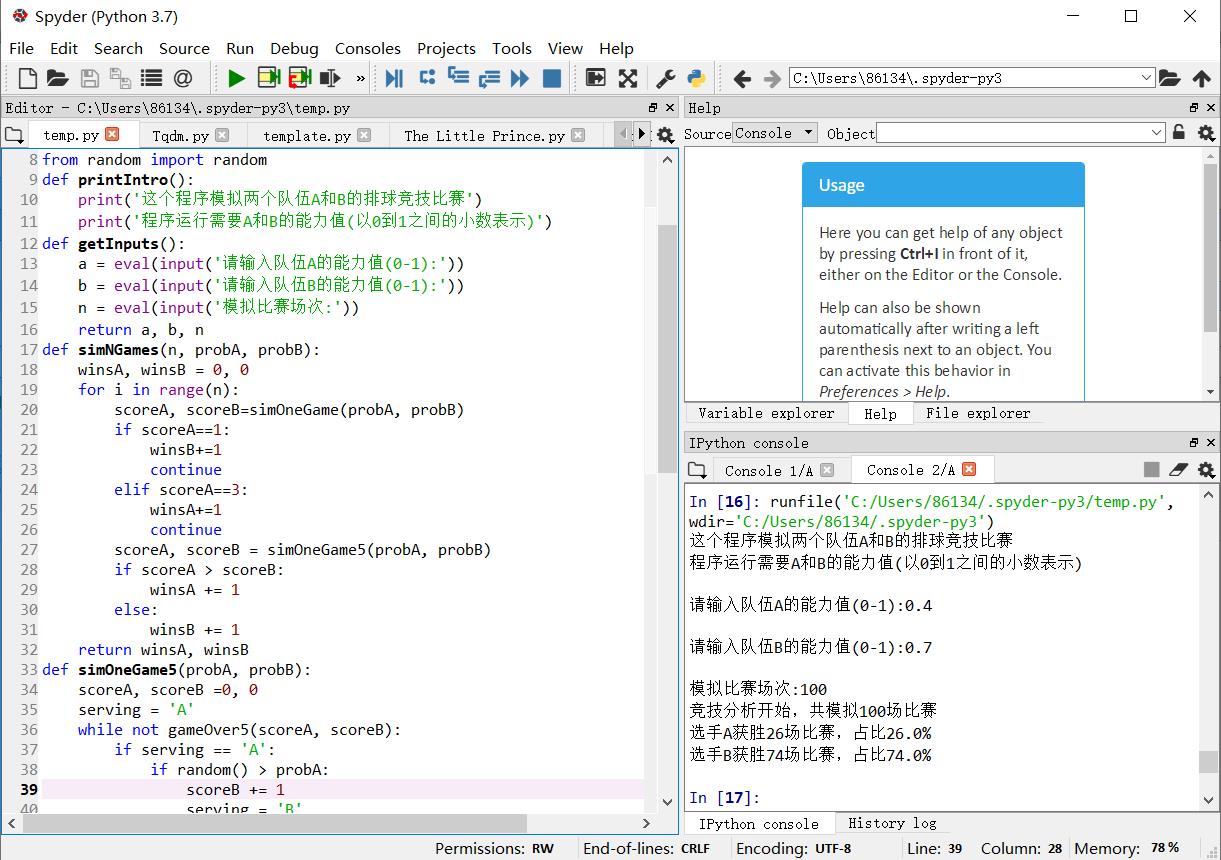
二、用requests库的get()函数访问Google主页20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容长度。
import requests wangye="http://www.google.cn/ig/" def pac(wangye): print("第",i+1,"次访问") r=requests.get(wangye,timeout=30) r.raise_for_status() print("text编码方式为",r.encoding) print("网络状态码为:",r.status_code) print("text属性长度:",len(r.text)) print("content属性长度:",len(r.content)) return r.text for i in range(20): print(pac(wangye))
运行结果(截取第15-20次访问的数据):
第 15 次访问text编码方式为 ISO-8859-1网络状态码为: 200text属性长度: 1969content属性长度: 1969<!DOCTYPE html><html lang="zh"> <head> <meta charset="utf-8"> <title> Google </title> <style>html { background: #fff; margin: 0 1em; } body { font: .8125em/1.5 arial, sans-serif; text-align: center; } h1, #term { font-weight: normal; } h1 { font-size: 1.5em; margin: 1em 0 0; } p#footer { color: #767676; font-size: .77em; } p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; } ul { margin: 2em; padding: 0; } li { display: inline; padding: 0 2em; } div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; } div#alt { height: 230px; padding: 70px 0 0; } div:hover, div:hover * { cursor: pointer; } div:hover { border-color: #999; } div p { margin: .5em 0 1.5em; } img { border: 0; } #term { color: #900; } </style> </head> <body> <div id="main"> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"> <img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257"> </a> <h1> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"><strong id= "target">google.com.hk/ig</strong></a> </h1> <p> 请æ¶èæ们çç½å </p> </div> <ul> <li> <a href="http://www.google.cn/shihui?sourceid=cnhp">æ¶æ </a> </li> <li> <a href="http://www.google.cn/music?sourceid=cnhp">é³ä¹</a> </li> <li> <a href="http://translate.google.cn/?sourceid=cnhp">ç¿»è¯</a> </li> </ul> <p id="footer"> © 2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯ååB2-20070004å·</a> <script src= "/intl/zh-CN_cn/landing/cnexp/view-china.js" nonce="Kh1v-DPSvd8ROq5xFn8Ctw"></script> </p> </body></html>
第 16 次访问text编码方式为 ISO-8859-1网络状态码为: 200text属性长度: 1969content属性长度: 1969<!DOCTYPE html><html lang="zh"> <head> <meta charset="utf-8"> <title> Google </title> <style>html { background: #fff; margin: 0 1em; } body { font: .8125em/1.5 arial, sans-serif; text-align: center; } h1, #term { font-weight: normal; } h1 { font-size: 1.5em; margin: 1em 0 0; } p#footer { color: #767676; font-size: .77em; } p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; } ul { margin: 2em; padding: 0; } li { display: inline; padding: 0 2em; } div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; } div#alt { height: 230px; padding: 70px 0 0; } div:hover, div:hover * { cursor: pointer; } div:hover { border-color: #999; } div p { margin: .5em 0 1.5em; } img { border: 0; } #term { color: #900; } </style> </head> <body> <div id="main"> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"> <img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257"> </a> <h1> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"><strong id= "target">google.com.hk/ig</strong></a> </h1> <p> 请æ¶èæ们çç½å </p> </div> <ul> <li> <a href="http://www.google.cn/shihui?sourceid=cnhp">æ¶æ </a> </li> <li> <a href="http://www.google.cn/music?sourceid=cnhp">é³ä¹</a> </li> <li> <a href="http://translate.google.cn/?sourceid=cnhp">ç¿»è¯</a> </li> </ul> <p id="footer"> © 2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯ååB2-20070004å·</a> <script src= "/intl/zh-CN_cn/landing/cnexp/view-china.js" nonce="DapmUUce6LqwL7F8pBgYPQ"></script> </p> </body></html>
第 17 次访问text编码方式为 ISO-8859-1网络状态码为: 200text属性长度: 1969content属性长度: 1969<!DOCTYPE html><html lang="zh"> <head> <meta charset="utf-8"> <title> Google </title> <style>html { background: #fff; margin: 0 1em; } body { font: .8125em/1.5 arial, sans-serif; text-align: center; } h1, #term { font-weight: normal; } h1 { font-size: 1.5em; margin: 1em 0 0; } p#footer { color: #767676; font-size: .77em; } p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; } ul { margin: 2em; padding: 0; } li { display: inline; padding: 0 2em; } div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; } div#alt { height: 230px; padding: 70px 0 0; } div:hover, div:hover * { cursor: pointer; } div:hover { border-color: #999; } div p { margin: .5em 0 1.5em; } img { border: 0; } #term { color: #900; } </style> </head> <body> <div id="main"> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"> <img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257"> </a> <h1> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"><strong id= "target">google.com.hk/ig</strong></a> </h1> <p> 请æ¶èæ们çç½å </p> </div> <ul> <li> <a href="http://www.google.cn/shihui?sourceid=cnhp">æ¶æ </a> </li> <li> <a href="http://www.google.cn/music?sourceid=cnhp">é³ä¹</a> </li> <li> <a href="http://translate.google.cn/?sourceid=cnhp">ç¿»è¯</a> </li> </ul> <p id="footer"> © 2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯ååB2-20070004å·</a> <script src= "/intl/zh-CN_cn/landing/cnexp/view-china.js" nonce="8eslxqeJlij3FeX1lImGSg"></script> </p> </body></html>
第 18 次访问text编码方式为 ISO-8859-1网络状态码为: 200text属性长度: 1969content属性长度: 1969<!DOCTYPE html><html lang="zh"> <head> <meta charset="utf-8"> <title> Google </title> <style>html { background: #fff; margin: 0 1em; } body { font: .8125em/1.5 arial, sans-serif; text-align: center; } h1, #term { font-weight: normal; } h1 { font-size: 1.5em; margin: 1em 0 0; } p#footer { color: #767676; font-size: .77em; } p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; } ul { margin: 2em; padding: 0; } li { display: inline; padding: 0 2em; } div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; } div#alt { height: 230px; padding: 70px 0 0; } div:hover, div:hover * { cursor: pointer; } div:hover { border-color: #999; } div p { margin: .5em 0 1.5em; } img { border: 0; } #term { color: #900; } </style> </head> <body> <div id="main"> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"> <img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257"> </a> <h1> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"><strong id= "target">google.com.hk/ig</strong></a> </h1> <p> 请æ¶èæ们çç½å </p> </div> <ul> <li> <a href="http://www.google.cn/shihui?sourceid=cnhp">æ¶æ </a> </li> <li> <a href="http://www.google.cn/music?sourceid=cnhp">é³ä¹</a> </li> <li> <a href="http://translate.google.cn/?sourceid=cnhp">ç¿»è¯</a> </li> </ul> <p id="footer"> © 2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯ååB2-20070004å·</a> <script src= "/intl/zh-CN_cn/landing/cnexp/view-china.js" nonce="NGrucCzaq_oOvjFMG0cGsg"></script> </p> </body></html>
第 19 次访问text编码方式为 ISO-8859-1网络状态码为: 200text属性长度: 1969content属性长度: 1969<!DOCTYPE html><html lang="zh"> <head> <meta charset="utf-8"> <title> Google </title> <style>html { background: #fff; margin: 0 1em; } body { font: .8125em/1.5 arial, sans-serif; text-align: center; } h1, #term { font-weight: normal; } h1 { font-size: 1.5em; margin: 1em 0 0; } p#footer { color: #767676; font-size: .77em; } p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; } ul { margin: 2em; padding: 0; } li { display: inline; padding: 0 2em; } div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; } div#alt { height: 230px; padding: 70px 0 0; } div:hover, div:hover * { cursor: pointer; } div:hover { border-color: #999; } div p { margin: .5em 0 1.5em; } img { border: 0; } #term { color: #900; } </style> </head> <body> <div id="main"> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"> <img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257"> </a> <h1> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"><strong id= "target">google.com.hk/ig</strong></a> </h1> <p> 请æ¶èæ们çç½å </p> </div> <ul> <li> <a href="http://www.google.cn/shihui?sourceid=cnhp">æ¶æ </a> </li> <li> <a href="http://www.google.cn/music?sourceid=cnhp">é³ä¹</a> </li> <li> <a href="http://translate.google.cn/?sourceid=cnhp">ç¿»è¯</a> </li> </ul> <p id="footer"> © 2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯ååB2-20070004å·</a> <script src= "/intl/zh-CN_cn/landing/cnexp/view-china.js" nonce="Msgjfwhw_UbV6x-vCUqjwg"></script> </p> </body></html>
第 20 次访问text编码方式为 ISO-8859-1网络状态码为: 200text属性长度: 1969content属性长度: 1969<!DOCTYPE html><html lang="zh"> <head> <meta charset="utf-8"> <title> Google </title> <style>html { background: #fff; margin: 0 1em; } body { font: .8125em/1.5 arial, sans-serif; text-align: center; } h1, #term { font-weight: normal; } h1 { font-size: 1.5em; margin: 1em 0 0; } p#footer { color: #767676; font-size: .77em; } p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; } ul { margin: 2em; padding: 0; } li { display: inline; padding: 0 2em; } div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; } div#alt { height: 230px; padding: 70px 0 0; } div:hover, div:hover * { cursor: pointer; } div:hover { border-color: #999; } div p { margin: .5em 0 1.5em; } img { border: 0; } #term { color: #900; } </style> </head> <body> <div id="main"> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"> <img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257"> </a> <h1> <a href="http://www.google.com.hk/ig?hl=zh-CN&sourceid=cnhp"><strong id= "target">google.com.hk/ig</strong></a> </h1> <p> 请æ¶èæ们çç½å </p> </div> <ul> <li> <a href="http://www.google.cn/shihui?sourceid=cnhp">æ¶æ </a> </li> <li> <a href="http://www.google.cn/music?sourceid=cnhp">é³ä¹</a> </li> <li> <a href="http://translate.google.cn/?sourceid=cnhp">ç¿»è¯</a> </li> </ul> <p id="footer"> © 2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯ååB2-20070004å·</a> <script src= "/intl/zh-CN_cn/landing/cnexp/view-china.js" nonce="y5rl9l2SmCo-NXB9zXfmdA"></script> </p> </body></html>
三、这是一个简单的html页面,请保持为字符串,完成后面的计算要求。
a.打印head标签内容和你的学号后两位
b 获取body标签内容
c 获取id为first的标签对象
d 获取并打印html页面中的中文字符
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <hl>我的第一个标题学号25</hl> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> <tr> </table> </html> html
完成计算要求:
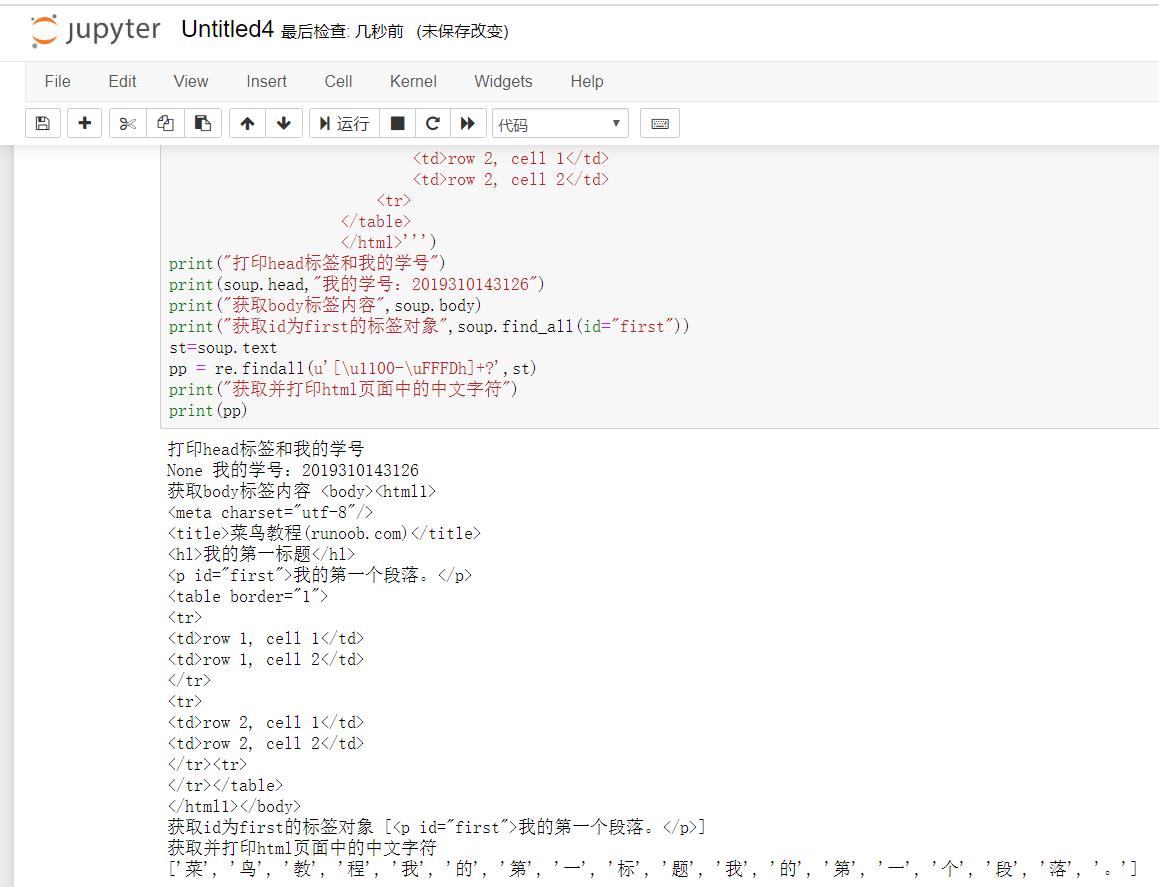
from bs4 import BeautifulSoup import re soup=BeautifulSoup(\'\'\'<!DOCTYPE html> <html1> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <hl>我的第一标题</hl> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> <tr> </table> </html>\'\'\') print("打印head标签和我的学号") print(soup.head,"我的学号:2019310143126") print("获取body标签内容",soup.body) print("获取id为first的标签对象",soup.find_all(id="first")) st=soup.text pp = re.findall(u\'[\\u1100-\\uFFFDh]+?\',st) print("获取并打印html页面中的中文字符") print(pp)
运行结果:
四、爬中国大学排名网站内容
爬取2017年大学排名
(一)提取:
import requests from bs4 import BeautifulSoup allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=\'utf-8\' return r.text except: return "" def fillUnivList(soup): data = soup.find_all(\'tr\') for tr in data: ltd=tr.find_all(\'td\') if len(ltd)==0: continue singleUniv=[] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{:^4}{:^10}{:^5}{:^8}{:^10}".format("排名","学校名称","省市","总分","培养规模")) for i in range(num): u=allUniv[i] print("{:^4}{:^10}{:^5}{:^8}{:^10}".format(u[0],u[1],u[2],u[3],u[6])) def main(num): url=\'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html\' html=getHTMLText(url) soup=BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(10)
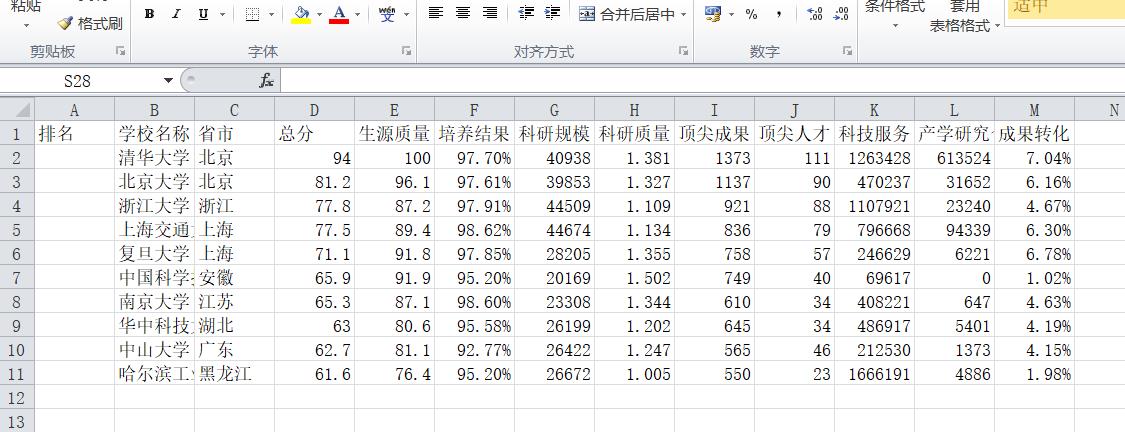
(二)提取所有数据并将结果存为csv文件:
import csv import os import requests from bs4 import BeautifulSoup allUniv = [] def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = \'utf-8\' return r.text except: return "" def fillUnivList(soup): data = soup.find_all(\'tr\') for tr in data: ltd = tr.find_all(\'td\') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def writercsv(save_road,num,title): if os.path.isfile(save_road): with open(save_road,\'a\',newline=\'\')as f: csv_write=csv.writer(f,dialect=\'excel\') for i in range(num): u=allUniv[i] csv_write.writerow(u) else: with open(save_road,\'w\',newline=\'\')as f: csv_write=csv.writer(f,dialect=\'excel\') csv_write.writerow(title) for i in range(num): u=allUniv[i] csv_write.writerow(u) title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化"] save_road="e:/test1.csv" def main(): url = \'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html\' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") fillUnivList(soup) writercsv(save_road,10,title) main()
运行结果:
以上是关于第一个爬虫和测试的主要内容,如果未能解决你的问题,请参考以下文章