python任务25-第一个爬虫和测试
Posted goti-764982
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python任务25-第一个爬虫和测试相关的知识,希望对你有一定的参考价值。
一:
用requests 多次访问百度主页内容,打印返回状态,text内容,计算text属性和cotent属性所返回网页内容的长度
import requests r=requests.get("http://www.baidu.com") r.encoding="UTF-8" for i in range(20): print(r.status_code) print(r.text) print(len(r.content)) print(len(r.text))

二:获取html页面内容
from bs4 import BeautifulSoup import re soup=BeautifulSoup(‘‘‘<!DOCTYPE html><head><meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title></head><body> <h1>我的第一标题</h1><p id=‘first‘>我的第一段落。</p > </body><table border="1"><tr><td>row 1, cell 1</td> <td>row 1, cell 2</td></tr><tr><td>row 2, cell 1</td> <td>row 2, cell 2</td></tr></table></html>","html.parser‘‘‘) print(soup.head,"41") print(soup.body) print(soup.find_all(id="first")) r=soup.text pat = re.findall(u‘[u1100-uFFFDh]+?‘,r) print(pat)

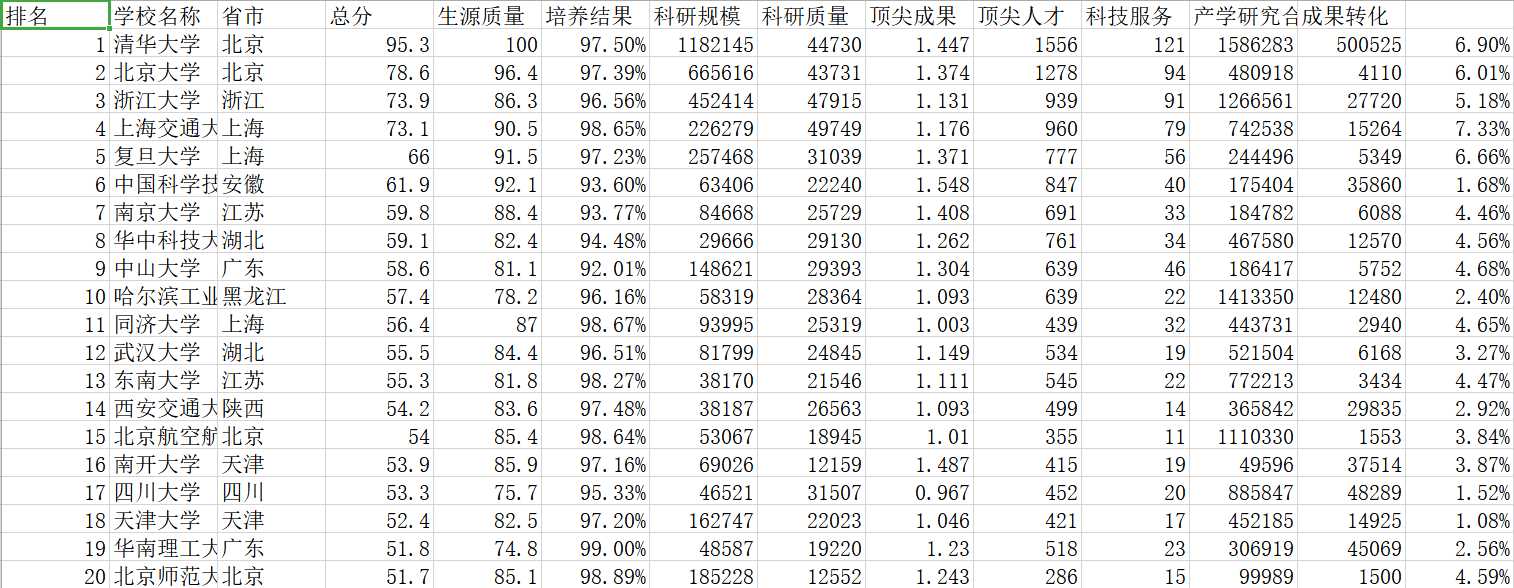
三:爬中国大学排名网站(2018)
import csv import os import requests import pandas from bs4 import BeautifulSoup allUniv = [] def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding =‘utf-8‘ return r.text except: return "" def fillUnivList(soup): data = soup.find_all(‘tr‘) for tr in data: ltd = tr.find_all(‘td‘) if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def writercsv(save_road,num,title): if os.path.isfile(save_road): with open(save_road,‘a‘,newline=‘‘)as f: csv_write=csv.writer(f,dialect=‘excel‘) for i in range(num): u=allUniv[i] csv_write.writerow(u) else: with open(save_road,‘w‘,newline=‘‘)as f: csv_write=csv.writer(f,dialect=‘excel‘) csv_write.writerow(title) for i in range(num): u=allUniv[i] csv_write.writerow(u) title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模", "科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化"] save_road="C:\\Users\\疯丫头\\Desktop\\python\\paimimg.csv" def main(): url = ‘http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html‘ html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") fillUnivList(soup) writercsv(save_road,20,title) main()
以上是关于python任务25-第一个爬虫和测试的主要内容,如果未能解决你的问题,请参考以下文章