千万日活级产品人必备:产品数据分析中的两个模型
Posted jason-zhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了千万日活级产品人必备:产品数据分析中的两个模型相关的知识,希望对你有一定的参考价值。
本篇文章分为两个部分,第一部分介绍产品数据分析中最基础的两个分析模型;第二部分结合案例来谈谈这些模型在实战中要注意的关键点。
模型一:漏斗模型
第一个我们要介绍的模型是漏斗模型,所为漏斗模型其最早起源是从传统行业的营销商业活动中演变而来的,它是一套流程式数据分析方法。
漏斗模型框架是什么?
它的主要模型框架:通过检测目标流程中起点(用户进入),到最后完成目标动作。这其中经历过的每个节点的用户量与留存量,来考核每个节点的好坏,来找到最需要优化的节点。可以说漏斗模型是用户行为状态以及从起点到终点各阶段用户转化率情况的重要分析模型。
实战案例
在这之前我们要先说一个前提:所有漏斗模型的建立一定要是在产品的主流程之上,只有这样数据量才会有足够大样本性。
让我们拿一个电商中从进入网站到购买的过程漏斗数据集来看,如下:
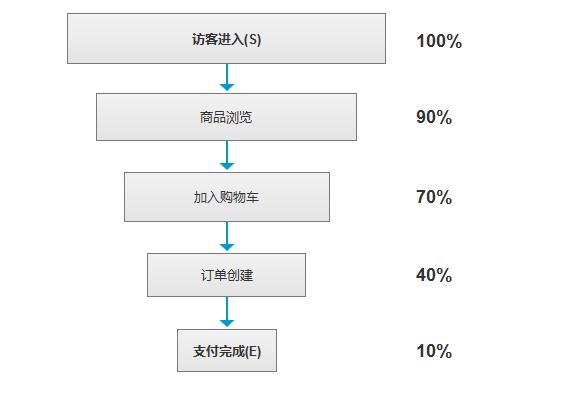
图1. 购买过程数据漏斗
在第一步我们要先明确我们的目标:分析用户从进入网站到最终转化购买这个过程中,用户从进入以及到最终实现目标的各个环节的转化率,并最终找到这个路径中用户流失最多的环节。
根据这个目标我们在上面的例子中,可以直观的看到这样的一个事实:用户从网站首页到商品详情页的这一环节转化率相对于其他环节是最低的。
好,那到这我们就算分析完毕了吗?找到产品的症结所在了吗?显然,答案是否定。
谈到漏斗模型的转化率这里就有两个实战中关注点是需要注意的:
1. 最重要一点数据怎么看?
我们不能说某个环节的转化率最低,就一定是某一个环节出现了问题,比如上面的例子,在访客进入到商品浏览这个流程中,其转化率有90%是所有环节中最高的。
但是这能说明什么呢?假设上个月这个环节是100%,那这里反而成为产品此时最大的问题所在。此外如果和同行业比的话,发现行业同类产品的这个环节平均转化率是95%,那还是说明这个阶段不是足够好的。
这就是说在我们拿到数据后,要按照一定的对比维度去进行分析,得到的结果才是有意义的。
总结来说,在漏斗模型建立完成后,我们对数据要从如下三个维度去进行分析:
- 纵向对比:也就是让产品与自己历史同期进行对比,这种对比适用于对某一流程或其中某个步骤进行改进或优化的效果监控;
- 横向对比:通过将本产品的同一流程转化率在竞品中进行横向对比,定位自身产品出现的问题;
- 来源分类:细分来源或不同的客户类型在转化率上的表现,从而完成客户群体划分。在日常分析中我们通常用于网站广告或推广的效果的评价。
大家可以根据自己的需要去挑选维度来分析。
2. 漏斗模型的漏斗颗粒度定义
在实际的场景中同一款产品会有各种各样的用户类型,比如用户来自于不同的区域、不同的生命周期、不同的性别,不同的年龄,他们在漏斗中的表现都是不一样的,也就造成了在用户漏斗中的转化率往往是有很大的差异的,因此我们需要将不同的人群拆分成一个个小的漏斗去逐一分析,一点点去分析结果。
让我们再总结一下所谓漏斗模型将任意产品流程抽象成一个个的关键步骤,如案例中的购物流程。然后用转化率来衡量每一个步骤的表现,最后通过异常的数据指标找出有问题的环节。从而解决问题优化该步骤,最终达到提升转化率的目的。
用一句话来说漏斗模型的核心思想就是分解和归类量化。
在定位了产品出现问题的环节后,接下来让我们来看看,如何具体定位指标。
模型二:杜邦分析模型
让我们先来看下百科中的定义
“杜邦分析法(DuPont Analysis)是利用几种主要的财务比率之间的关系来综合地分析企业的财务状况。具体来说,它是一种用来评价公司赢利能力和股东权益回报水平,从财务角度评价企业绩效的一种经典方法。其基本思想是将企业净资产收益率逐级分解为多项财务比率乘积,这样有助于深入分析比较企业经营业绩。”
其实说白了就是将指标进行肢解,将大指标拆分成若干个底层应用中直接触达的动作。
如果用一张图来表示,就是如下:

图2. 杜邦分析核心模式
一般的我们将指标分为如下三个角色:
- 核心指标
- 子指标(若干层级)
- 孙代指标(让抽象的指标与APP中动作进行关联上的指标)
- 那为什么要这么做呢?直接看指标不行吗?
其实是这样的产品本身涉及到的各种指标类型非常的多,但产品经理无法对这些指标面面俱到。往往此时产品经理只能去关注本业务核心指标,而这些指标已经远远脱离了现实APP中可以直观感受到的部分。
举例来说,当我们讨论销售额的时候讨论的是什么?这不是一句俏皮话,这是一个现实的问题。如果直接谈销售额我们很难有直观感受,但往往通过指标拆分后,我们拿到的结果告诉我们销售额其就是一个产品中支付界面的流程或者投放中产品触达的最优组合。
正是因为存在如此大的抽象层级差距,也就导致了在我们看到产品核心指标(注意一定要监控产品业务核心指标,而不是笼统的DAU等数据,如果对这个概念不太理解可以去我的主页看我本系列的第一篇文章)发生变化的时候,很难清楚到底是什么原因导致本指标的上升或下降呢?
拿一个电商的产品案例来说,对于电商类的产品来说核心指标就是成交金额。
而当我们发现在我们某次日常运营活动投放后,产品的成交金额不增反而出现了下跌,这个时候问题就出现了到底是什么让我们的产品出现这样的问题了呢?
那么这个时候就需要通过杜邦分析模型来寻找答案了。
首先我们将电商成交额做如下拆分:
- 核心指标拆分:销售额 = 付费人数 * 客单价
- 子指标拆分:付费人数 = UV * 付费转化率
- 孙代指标拆分:
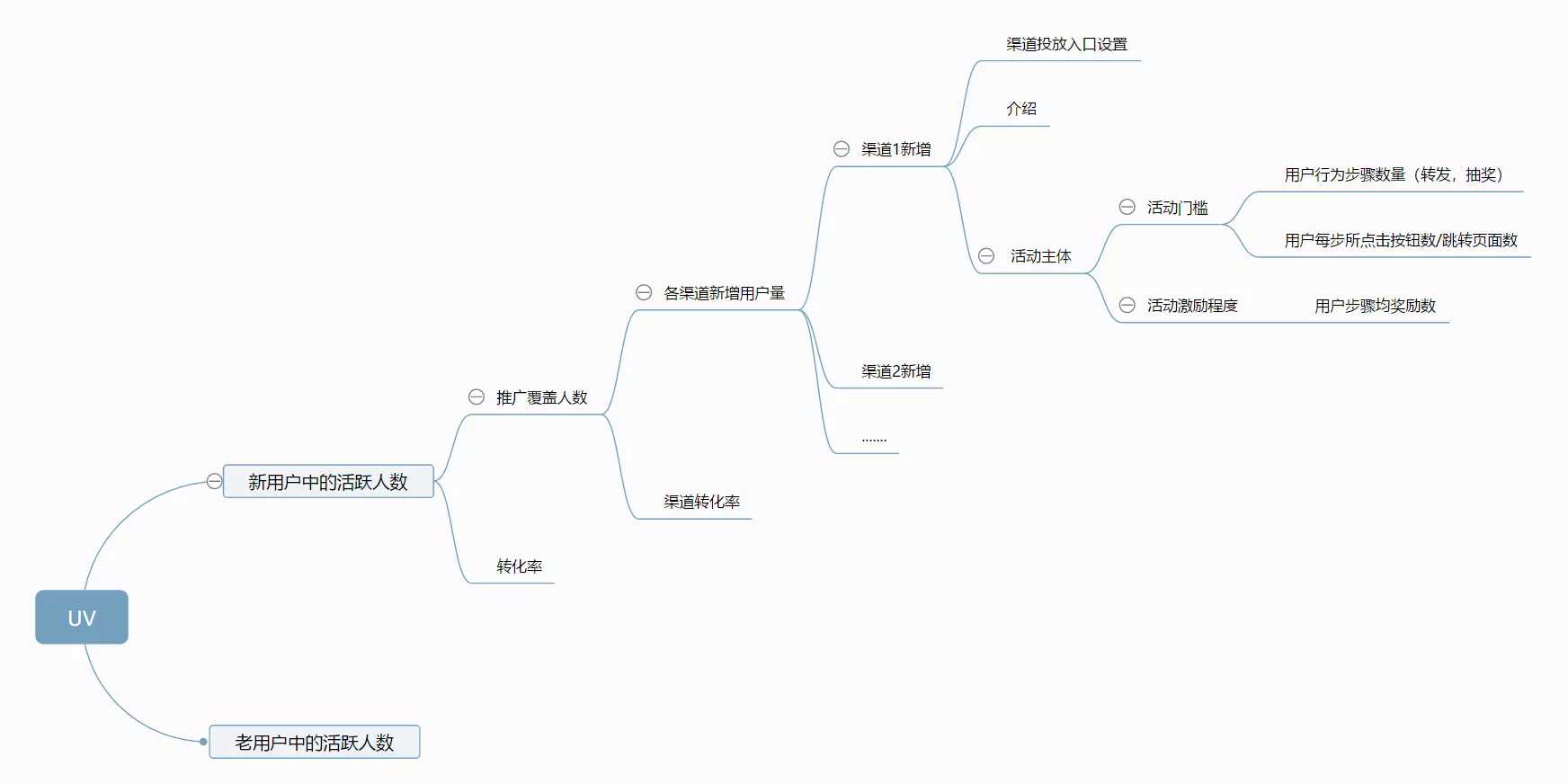
图3. UV拆分结果(在新标签页中打开即可查看大图)
我们拿此处UV的例子来看,经过层层拆分,我们看到了最后和产品相关的是我们本次活动用户步骤与步骤奖励数这两个指标。
因此我们就可以根据如上的图中的指标去看数据来一步步寻找产品的问题;
我们拿到的数据如下:
Part 1. 核心指标:
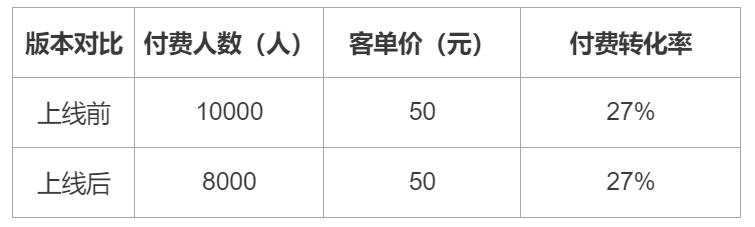
从这我们就能看到核心指标中付费人数出现了问题,那么我们就找到了入手调查的地方,让我们继续拆分付费人数这个指标。
Part 2. 子指标拆分:
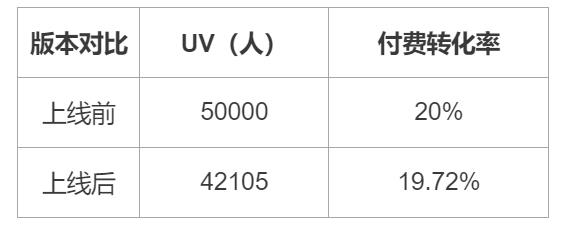
在付费转化率几乎没有变化的情况下,UV就成了这最大的问题。
Part 3. 孙代指标拆分:
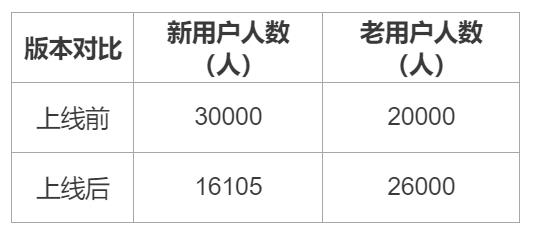
Part N. 中间省去若干个孙代指标的最终对比
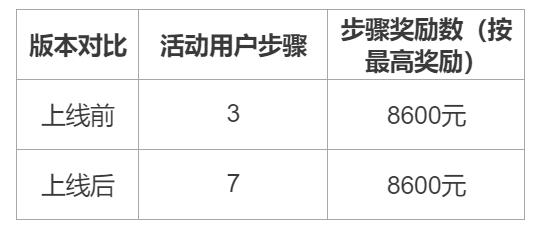
那么在这我们就能清楚的看到了,由于我们本次的活动要求用户过多,长达7步导致了用户很多程度下不愿意参与本活动,导致了流失与交易金额的下降。
到这我们产品的解决方案也就出来了需要对活动进行修改,减少活动用户步骤或者增大奖励。
转载自:千万日活级产品人必备(二):产品数据分析中的两个模型
以上是关于千万日活级产品人必备:产品数据分析中的两个模型的主要内容,如果未能解决你的问题,请参考以下文章