kafka在Maven项目中的使用
Posted 青木年华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka在Maven项目中的使用相关的知识,希望对你有一定的参考价值。
由于只是简单地了解和使用了kafka,所以对底层的东西并不做深入的分析,网上有很多资料介绍 kafka的安装以及它的配置,包括zookeeper集群的搭建。本文是在环境搭建好的情况下,介绍kafka在Maven项目中该如何使用。
1、kafka的配置文件
如果生产者和消费者都在一个模块里,那就只需要一个配置文件就行啦,如果在不同模块里的话就是两个(当然看你用什么环境,一个环境下一个配置文件,自己根据不同的环境进行配置,开发、测试、生产环境除了连接地址不一样外,其它可以配置成一样的)。本文的生产者和消费者处于两个模块中,所以配置文件是分开的。图1是生产者的kafka配置,图2是消费者的kafka配置。

图1
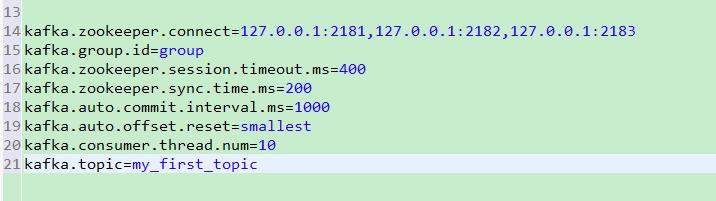
图2
图1:kafka.metadata.broker.list 应该配所有broker的地址和端口号,本文的IP和端口号纯属虚拟,应根据实际情况配置;
kafka.request.required.acks 是消息的确认模式,1则表示发送消息后悔等待leader确认,若为0则表示不保证消息的到达确认,只管发送,-1则是等待leader收到确认,并进行复制操作后,才返回;
kafka.serializer.class 消息的编码类型;
kafka.topic 创建的topic,如果服务器设置了不允许自动创建topic,则需要在服务器提前创建好。
图2:kafka.zookeeper.connect 连接zookeeper集群,消费者消费消息的时候依靠zookeeper来保存状态信息;
kafka.group.id 消费者所在的group,注意,kafka中消息只能被一个group中的一个消费者消费,所以如果需要消费同一组数据,需要配置多个group来消费;
kafka.zookeeper.session.timeout.ms 连接zookeeper等待连接时间;
kafka.zookeeper.sync.time.ms zookeeper的follower同leader的同步时间;
kafka.auto.commit.interval.ms 消费者自动提交offset到zookeeper的时间;
kafka.auto.offset.reset smallest表示从未被消费的消息最小偏移处开始消费;
kafka.consumer.thread.num 消费者需要配置的线程池大小,与预先配置的topic分区数相等;
kafka.topic 要消费消息的topic。
2、生产者
本文将生产者类放在Spring中管理,在Spring配置文件中配置相应的bean,然后在要发送消息的类中使用@Resource注解注入这个生产类即可调用它定义的send方法。图3和图4是生产者在Spring中的配置。
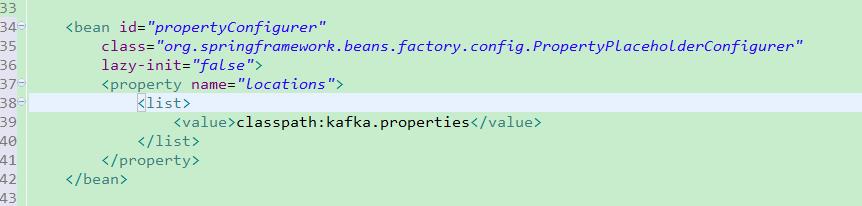
图3
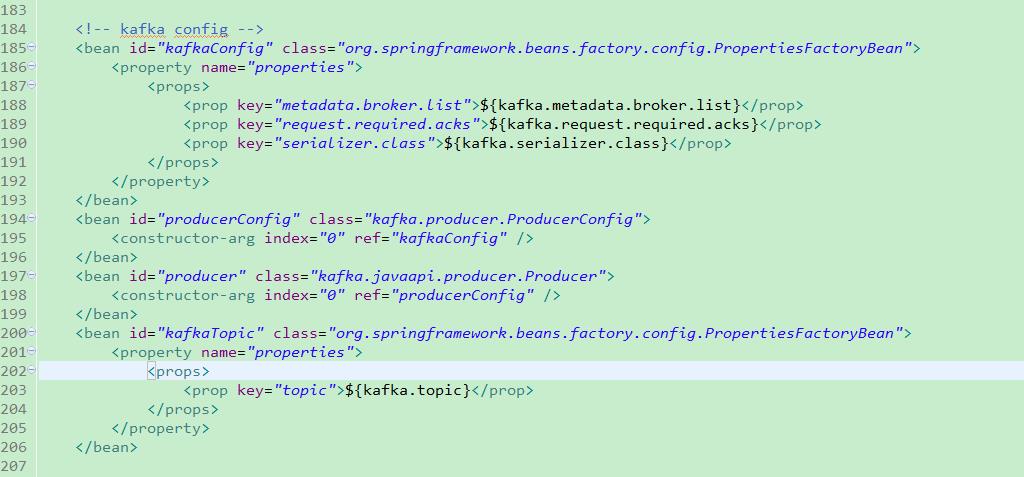
图4
图3:引入步骤1中的kafka配置文件,可以读取相关的配置。
图4:根据kafka配置实例化一个生产者,并读取配置的topic。
Spring中配置好后,需要实现对应的Producer类,在类里面定义一个发送消息的方法,在要发送消息时,注入id为producer的bean即可调用。
3、消费者
消费者消费消息的时候需要连接的是zookeeper集群,同生产者一样,消费者也放在Spring中进行管理。本文使用的是原生API的High Level Consumer,它不需要关心offset的值,只需消费消息即可。图5是消费者在Spring中的配置。
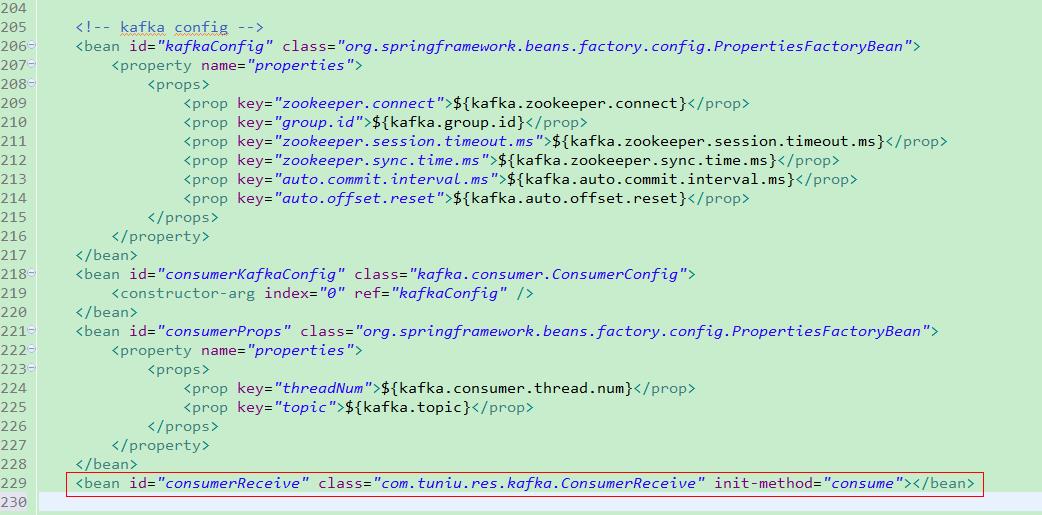
注意红色框线部分,这是设置启动应用时,Spring会自动去执行ConsumerReceive类里的consume方法,即应用启动就会自动去消费消息。
以上是关于kafka在Maven项目中的使用的主要内容,如果未能解决你的问题,请参考以下文章