DICOM:DICOM开源库多线程分析之“ThreadPoolQueue in fo-dicom”
Posted zssure
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DICOM:DICOM开源库多线程分析之“ThreadPoolQueue in fo-dicom”相关的知识,希望对你有一定的参考价值。
背景:
上篇博文介绍了dcm4chee中使用的Leader/Follower线程池模型,主要目的是节省上下文切换,提高运行效率。本博文同属【DICOM开源库多线程分析】系列,着重介绍fo-dicom中使用的ThreadPoolQueue线程池。
ThreadPoolQueue in fo-dicom:
先看一下ThreadPoolQueue代码中自定义的数据结构,
public class ThreadPoolQueue<T> {
private class WorkItem {
public T Group;
public Action Action;
public WaitCallback Callback;
public object State;
}
private class WorkGroup {
public T Key;
public object Lock = new object();
public volatile bool Executing = false;
public Queue<WorkItem> Items = new Queue<WorkItem>();
public WorkGroup(T key) {
Key = key;
}
}
private object _lock = new object();
private volatile bool _stopped = false;
private Dictionary<T, WorkGroup> _groups;
public ThreadPoolQueue() {
_groups = new Dictionary<T, WorkGroup>();
Linger = 200;
DefaultGroup = default(T);
}
……
}由上述结构基本可以看出ThreadPoolQueue自定义线程池队列是将不同的线程根据类型T进行分组,并将对应的处理操作代理(Action与WaitCallback)一同传入。
相较于传统的ThreadPool系统线程池,ThreadPoolQueue通过创建字典对象Dictionary
private void Execute(T groupKey) {
if (_stopped)
return;
WorkGroup group = null;
lock (_lock) {
if (!_groups.TryGetValue(groupKey, out group))
return;
}
lock (group.Lock) {
if (group.Executing)
return;
if (group.Items.Count == 0 && !group.Key.Equals(DefaultGroup)) {
_groups.Remove(groupKey);
System.Console.WriteLine("Remove WorkGroup Key is {0}", group.Key);
return;
}
group.Executing = true;
ThreadPool.QueueUserWorkItem(ExecuteProc, group);
}
}联系之前专栏中其他博文,例如DICOM:DICOM3.0网络通信协议之“开源库实现剖析”、DICOM:DICOM开源库多线程分析之“LF_ThreadPool in DCM4CHEE”,可以总结fo-dicom开源库对于DICOM请求的整体响应逻辑如下:
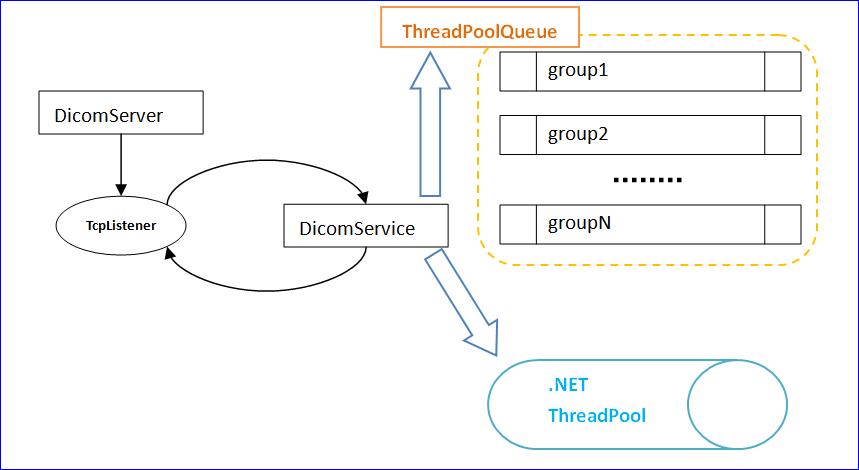
用到ThreadPoolQueue的地方分别用来处理PDataTF数据包,即DICOM Upper layer协议中的P-DATA消息,详情可参见之前关于DICOM网络传输的博文DICOM:DICOM3.0网络通信协议(三)、DICOM:DICOM3.0网络通信协议(续)、DICOM医学图像处理:DICOM网络传输,以及DICOM医学图像处理:全面分析DICOM3.0标准中的通讯服务模块,按照消息的MessageID分别将指定的处理任务放到响应的分组中,控制整体消息流的FIFO顺序执行。另外也会待任务执行完毕后会只保留默认分组的线程池,减少系统资源浪费。
ThreadPoolQueue本地测试示例:
为了演示ThreadPoolQueue在.NET系统ThreadPool线程池基础上添加了任务FIFO顺序执行控制流,本地编写了一个简单的测试程序,演示代码如下:
private static ThreadPoolQueue<string> threadpool = new ThreadPoolQueue<string>();
private static string[] groups = new string[] { "group-0", "group-1", "group-2", "group-3", "group-4"};
private static Dictionary<string, List<int>> results = new Dictionary<string, List<int>>();
private static object mutex = new object();
static void Main(string[] args)
{
threadpool.DefaultGroup = "group-0";
for (int i = 0; i < 100; ++i)
{
threadpool.Queue(groups[i % 5], ThreadProcessing, i);
Thread.Sleep(500);
}
System.Console.ReadLine();
foreach (var result in results.Keys.ToList())
{
System.Console.WriteLine("Group {0}", result);
foreach (var record in results[result])
{
System.Console.Write("Item={0}\\t", record);
}
System.Console.WriteLine();
}
System.Console.ReadKey();
}
private static void ThreadProcessing(object state)
{
int record = (int)state;
Thread.Sleep(2 * 1000);
lock(mutex)
{
List<int> recordList = new List<int>();
if (!results.TryGetValue(groups[record % 5], out recordList))
{
results.Add(groups[record % 5], new List<int>());
}
results[groups[record % 5]].Add(record);
}
}本地调试结果如下:

知识点补充:
无论是之前介绍的dcm4chee中使用的Leader/Follower线程池模型,还是今天介绍的fo-dicom中的ThreadPoolQueue自定义线程池队列,都是提高效率的一种实现方式。现如今多核、多处理器,乃至分布式集群的出现,使得任务的调度变得尤为重要。因此搞清楚其中的各种概念,理清思路是前提。宏观和微观是相对而言的,
- 就线程和进程来说,线程概念范畴<进程概念范畴,线程就属于微观,进程是宏观。各进程内部需要实现具体的线程调度算法。
- 就进程与操作系统来说,进程概念范畴<操作系统概念范畴,操作系统内部需要实现各进程之间的调度算法。
- 就单核心与多核心来说,单核心概念范畴<多核心概念范畴,多核心内部在单核心调度进程基础上需要添加多个核心之间的调度算法。
- 就单机与集群来说,单机的概念范畴<集群的概念范畴,集群内部需要调度协调各主机的状态。
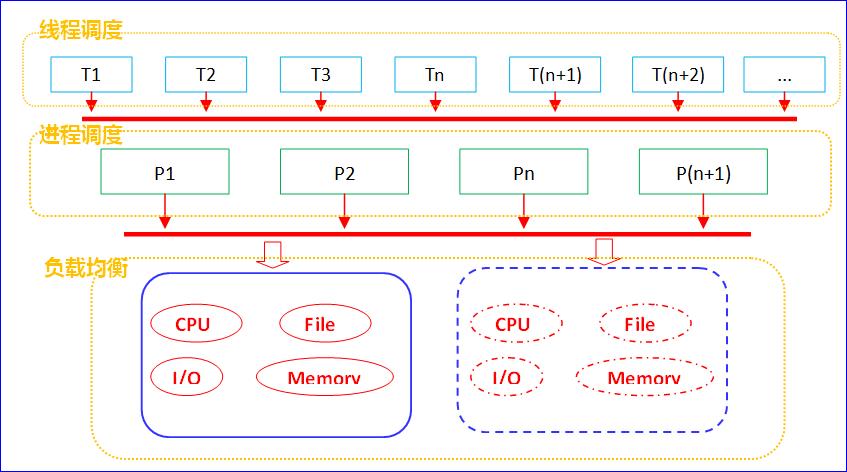
上述各个环节、各个层级都提到了调度算法,其本质解决的是资源竞争和数据同步,如果两个操作没有任何的资源竞争,甚至可以说没有任何的关系,那就不存在调度了,就比如不同公司的两个人同时领了工资;但是如果他俩同时去一个银行一个柜台找同一位漂亮MM存钱,那么就得排队等候了。
1. Thread:
- POSIX中Thread:
A single flow of control within a process. Each thread has its own thread ID, scheduling priority and policy, errno value, floating point environment, thread-specific key/value bindings, and the required system resources to support a flow of control. Anything whose address may be determined by a thread, including but not limited to static variables, storage obtained via malloc(), directly addressable storage obtained through implementation-defined functions, and automatic variables, are accessible to all threads in the same process.
- MSDN中Thread:
Operating systems use processes to separate the different applications that they are executing. Threads are the basic unit to which an operating system allocates processor time, and more than one thread can be executing code inside that process. Each thread maintains exception handlers, a scheduling priority, and a set of structures the system uses to save the thread context until it is scheduled. The thread context includes all the information the thread needs to seamlessly resume execution, including the thread’s set of CPU registers and stack, in the address space of the thread’s host process.
从上述两个标准中可以看出线程(Thread)是操作系统调度、分配CPU时间片最小单位,表示的是具体的控制流(即指令执行过程)。
2. Process:
- POSIX Process:
The POSIX model treats a “process” as an aggregation of system resources, including one or more threads that may be scheduled by the operating system on the processor(s) it controls. Although a process has its own set of scheduling attributes, these have an indirect effect (if any) on the scheduling behavior of individual threads as described below.
- MSDN Process:
An application consists of one or more processes. A process, in the simplest terms, is an executing program. One or more threads run in the context of the process.
从上述两个标准中可以看出进程(Process)是我们平时编写程序的具体执行(即executing program),是操作系统分配系统资源的最单位。
3. Concurrency VS Parallelism
上图中Parallelism的示意图肯定是没有问题的,而Concurrency的执行并非是上述图中的单一模式,待介绍完“Multi-core”和“Multi-processor”概念后再比较一下这两个概念。Concurrency and parallelism are related concepts, but there are small differences. Concurrency means that two or more tasks are making progress even though they might not be executing simultaneously. This can for example be realized with time slicing where parts of tasks are executed sequentially and mixed with parts of other tasks. Parallelism on the other hand arise when the execution can be truly simultaneous.
【摘自】:Akka.NET:Terminology and Concepts
- Concurrency:

- Parallelism:

4. Multi-core VS Multi-processor
Multi-core processor:
A multi-core processor is a single computing component with two or more independent actual processing units (called “cores”), which are the units that read and execute program instructions. The instructions are ordinary CPU instructions such as add, move data, and branch, but the multiple cores can run multiple instructions at the same time, increasing overall speed for programs amenable to parallel computing.
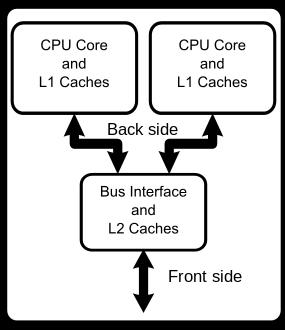
A multi-core processor implements multiprocessing in a single physical package. Designers may couple cores in a multi-core device tightly or loosely. For example, cores may or may not share caches, and they may implement message passing or shared-memory inter-core communication methods. Common network topologies to interconnect cores include bus, ring, two-dimensional mesh, and crossbar.
【摘自】:Wiki百科 Multi-core processorMulti-processor
Multiprocessing is the use of two or more central processing units (CPUs) within a single computer system. The term also refers to the ability of a system to support more than one processor and/or the ability to allocate tasks between them. There are many variations on this basic theme, and the definition of multiprocessing can vary with context, mostly as a function of how CPUs are defined (multiple cores on one die, multiple dies in one package, multiple packages in one system unit, etc.).
In a multiprocessing system, all CPUs may be equal, or some may be reserved for special purposes. A combination of hardware and operating system software design considerations determine the symmetry (or lack thereof) in a given system.
【摘自】:Wiki百科:Multi-processor
在Oracle的博文Concurrency vs Parallelism, Concurrent Programming vs Parallel Programming中也提到了Concurrency(并发)与Parallelism(并行)概念,与此同时也涉及了Multi-core(多核)和Multi-processor(多处理器)。文中提到:
If two concurrent threads are scheduled by the OS to run on one single-core non-SMT non-CMP processor, you may get concurrency but not parallelism. Parallelism is possible on multi-core, multi-processor or distributed systems.
Concurrency is often referred to as a property of a program, and is a concept more general than parallelism.
Interestingly, we cannot say the same thing for concurrent programming and parallel programming. They are overlapped, but neither is the superset of the other. The difference comes from the sets of topics the two areas cover. For example, concurrent programming includes topic like signal handling, while parallel programming includes topic like memory consistency model. The difference reflects the different orignal hardware and software background of the two programming practices.
上文表明Concurrency与Parallelism概念有重合但又互不包含,因此在理解两者概念上会经常有混淆。
5. Load Balancing:
随着多核心(Multi-core)、多处理器(Multi-processor),以及分布式集群(distributed systems)的出现,各部分之间的协调(这里主要指的是任务的整体分配,与具体的线程、进程、时间片的调度算法有别)同样显得尤为重要。
On SMP systems, it is important to keep the workload balanced among all processors to fully utilize the benefits of having more than one processor.
【摘自】:《Operating System Concepts, 9th Edition 》第6.5.3小节
6. Time Slice:
The period of time for which a process is allowed to run in a preemptive multitasking system is generally called the time slice, or quantum. The scheduler is run once every time slice to choose the next process to run. The length of each time slice can be critical to balancing system performance vs process responsiveness - if the time slice is too short then the scheduler will consume too much processing time, but if the time slice is too long, processes will take longer to respond to input.
An interrupt is scheduled to allow the operating system kernel to switch between processes when their time slices expire, effectively allowing the processor’s time to be shared between a number of tasks, giving the illusion that it is dealing with these tasks simultaneously, or concurrently. The operating system which controls such a design is called a multi-tasking system.
【摘自】:Wiki百科:Preemption (computing)抢占式
由本节最上图可以看出,所有的多线程调度、多进程调度,乃至分布式系统的协调最终依赖的都是时间中断(即时间片),硬件时间中断是所有调度最底层驱动的动力。
示例源代码:
- CSDN资源下载
- Github资源下载
注:下载Github的示例代码最好下载fo-dicom的整个仓库。
作者:zssure@163.com
时间:2016-02-05
以上是关于DICOM:DICOM开源库多线程分析之“ThreadPoolQueue in fo-dicom”的主要内容,如果未能解决你的问题,请参考以下文章