基于配置文件检测结果生成表格结果
Posted Boucher
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于配置文件检测结果生成表格结果相关的知识,希望对你有一定的参考价值。
#!/bin/bash # by hzwuboxiao rm -rf ./mail/messageContent/"$2".html #总述文件 comment=./mail/messageContent/messageContent."$2".txt #环境个数,目的是为了统计各个环境下面的工程的个数,以便确定表格的行数 envnums=`grep "环境" $comment | wc -l` echo "envnums="$envnums #先创建一个结果文件吧 touch ./mail/messageContent/"$2".html resulthtml=./mail/messageContent/"$2".html #先把表头写进去 echo "<html><head></head><body><table border=\'1\' cellspacing=\'0\' width=\'1000\'><tr align=\'center\'><td>环境名</td><td>工程名</td><td>缺少的配置文件个数</td><td>缺失的配置项个数</td><td>错误的配置项个数</td></tr>" >> $resulthtml #开始创建表格了,应该要用一个循环 env_count_pos=1 while [[ $env_count_pos -le $envnums ]];do echo "当前大小:"$env_count_pos"=-=-=-=-=-=-=当前环境个数"$envnums #如果要处理的是最后一个环境 if [[ $env_count_pos -eq $envnums ]];then #先找到当前环境下有多少个工程,以便确定表格占用的行数 #env_item_pre:最后一个"环境"所在的行数 env_item_pre=`grep -n "环境" $comment | head -"$env_count_pos" | tail -1 | awk -F \':\' \'{print $1}\'` #env_name:环境名称 env_name=`cat $comment | sed -n "$env_item_pre"p | awk -F \'环境\' \'{print $1}\'` echo "环境名:"$env_name #env_item_last:总述文件的行数 env_item_last=`cat $comment | wc -l` echo "env_item_pre"$env_item_pre"-----------env_item_last"$env_item_last echo "<tr align=\'center\'><td rowspan=\'"$((env_item_last-env_item_pre-1))"\'>$env_name</td>" >> $resulthtml #先处理当前环境下的第一个工程 proj_name=`cat $comment | sed -n "$((env_item_pre+1))"p | awk -F \'工程\' \'{print $1}\'` nums=`cat $comment | sed -n "$((env_item_pre+1))"p | grep -o \'[0-9]\\+\'` lost_files=`echo $nums | awk -F \' \' \'{print $1}\'` lost_items=`echo $nums | awk -F \' \' \'{print $2}\'` wrong_items=`echo $nums | awk -F \' \' \'{print $3}\'` echo "<td>"$proj_name"</td><td>"$lost_files"</td><td>"$lost_items"</td><td>"$wrong_items"</td></tr>" >> $resulthtml awk \'NR>\'"$((env_item_pre+1))"\' && NR<\'"$env_item_last" $comment | while read eachitem do #处理每一行,也就是每一个工程的总述,即类似于下面这行: #credits工程:缺少1个配置文件,1个配置项,对比标准配置文件,有0个错误配置项 #先获取工程名 proj_name=`echo $eachitem | awk -F \'工程\' \'{print $1}\'` #再获取上面的1 1 和 0三个数字 nums=`echo $eachitem | grep -o \'[0-9]\\+\'` lost_files=`echo $nums | awk -F \' \' \'{print $1}\'` lost_items=`echo $nums | awk -F \' \' \'{print $2}\'` wrong_items=`echo $nums | awk -F \' \' \'{print $3}\'` echo "<tr align=\'center\'><td>"$proj_name"</td><td>"$lost_files"</td><td>"$lost_items"</td><td>"$wrong_items"</td></tr>" >> $resulthtml done ((env_count_pos++)) #这个break一定要加 break fi echo "当前指标大小:"$env_count_pos #要处理的不是最后一个环境 env_item_pre=`grep -n "环境" $comment | head -"$env_count_pos" | tail -1 | awk -F \':\' \'{print $1}\'` #env_name:环境名称 env_name=`cat $comment | sed -n "$env_item_pre"p | awk -F \'环境\' \'{print $1}\'` #env_item_next:下一个“环境”所在的行数 echo "环境名"$env_name env_item_next=`grep -n "环境" $comment | head -"$((++env_count_pos))" | tail -1 | awk -F \':\' \'{print $1}\'` echo "env_item_pre"$env_item_pre"-----------env_item_next"$env_item_next echo "<tr align=\'center\'><td rowspan=\'"$((env_item_next-env_item_pre-2))"\'>$env_name</td>" >> $resulthtml #先处理当前环境下的第一个工程 proj_name=`cat $comment | sed -n "$((env_item_pre+1))"p | awk -F \'工程\' \'{print $1}\'` nums=`cat $comment | sed -n "$((env_item_pre+1))"p | grep -o \'[0-9]\\+\'` lost_files=`echo $nums | awk -F \' \' \'{print $1}\'` lost_items=`echo $nums | awk -F \' \' \'{print $2}\'` wrong_items=`echo $nums | awk -F \' \' \'{print $3}\'` echo "<td>"$proj_name"</td><td>"$lost_files"</td><td>"$lost_items"</td><td>"$wrong_items"</td></tr>" >> $resulthtml awk \'NR>\'"$((env_item_pre+1))"\' && NR<\'"$((env_item_next-1))" $comment | while read eachitem do #处理每一行,也就是每一个工程的总述,即类似于下面这行: #credits工程:缺少1个配置文件,1个配置项,对比标准配置文件,有0个错误配置项 #先获取工程名 proj_name=`echo $eachitem | awk -F \'工程\' \'{print $1}\'` #再获取上面的1 1 和 0三个数字 nums=`echo $eachitem | grep -o \'[0-9]\\+\'` lost_files=`echo $nums | awk -F \' \' \'{print $1}\'` lost_items=`echo $nums | awk -F \' \' \'{print $2}\'` wrong_items=`echo $nums | awk -F \' \' \'{print $3}\'` echo "<tr align=\'center\'><td>"$proj_name"</td><td>"$lost_files"</td><td>"$lost_items"</td><td>"$wrong_items"</td></tr>" >> $resulthtml done echo "<tr><td colspan=\'5\'></td></tr>" >> $resulthtml ((env_count_pos++)) done echo "</table></body></html>" >> $resulthtml
配置文件格式如下:
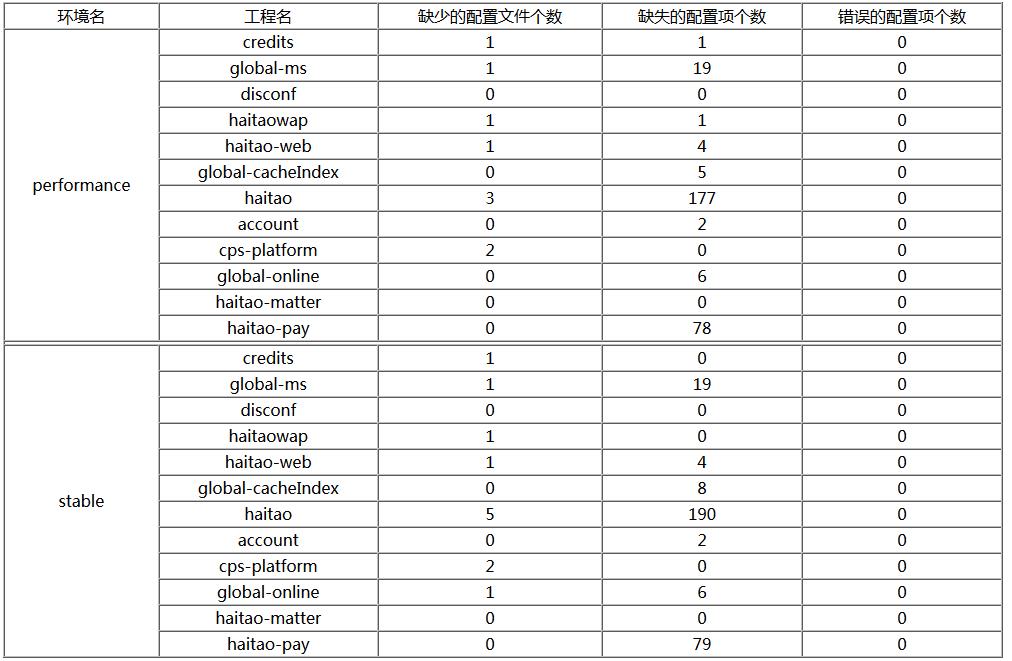
performance环境
credits工程:缺少1个配置文件,1个配置项,对比标准配置文件,有0个错误配置项
global-ms工程:缺少1个配置文件,19个配置项,对比标准配置文件,有0个错误配置项
disconf工程:缺少0个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
haitaowap工程:缺少1个配置文件,1个配置项,对比标准配置文件,有0个错误配置项
haitao-web工程:缺少1个配置文件,4个配置项,对比标准配置文件,有0个错误配置项
global-cacheIndex工程:缺少0个配置文件,5个配置项,对比标准配置文件,有0个错误配置项
haitao工程:缺少3个配置文件,177个配置项,对比标准配置文件,有0个错误配置项
account工程:缺少0个配置文件,2个配置项,对比标准配置文件,有0个错误配置项
cps-platform工程:缺少2个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
global-online工程:缺少0个配置文件,6个配置项,对比标准配置文件,有0个错误配置项
haitao-matter工程:缺少0个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
haitao-pay工程:缺少0个配置文件,78个配置项,对比标准配置文件,有0个错误配置项
stable环境
credits工程:缺少1个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
global-ms工程:缺少1个配置文件,19个配置项,对比标准配置文件,有0个错误配置项
disconf工程:缺少0个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
haitaowap工程:缺少1个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
haitao-web工程:缺少1个配置文件,4个配置项,对比标准配置文件,有0个错误配置项
global-cacheIndex工程:缺少0个配置文件,8个配置项,对比标准配置文件,有0个错误配置项
haitao工程:缺少5个配置文件,190个配置项,对比标准配置文件,有0个错误配置项
account工程:缺少0个配置文件,2个配置项,对比标准配置文件,有0个错误配置项
cps-platform工程:缺少2个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
global-online工程:缺少1个配置文件,6个配置项,对比标准配置文件,有0个错误配置项
haitao-matter工程:缺少0个配置文件,0个配置项,对比标准配置文件,有0个错误配置项
haitao-pay工程:缺少0个配置文件,79个配置项,对比标准配置文件,有0个错误配置项
效果如下图:
以上是关于基于配置文件检测结果生成表格结果的主要内容,如果未能解决你的问题,请参考以下文章
pyhton—opencv直线检测(HoughLines)找到最长的一条线
pyhton—opencv直线检测(HoughLines)找到最长的一条线