Spark在Ubuntu中搭建开发环境
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark在Ubuntu中搭建开发环境相关的知识,希望对你有一定的参考价值。
一、在Windows7中安装Ubuntu双系统
工具/原料
windows7 64位
ubuntu 16.04 32位
UltraISO最新版(用来将镜像文件烤到U盘中)
空U盘(若有文件,请先备份)
1.为安装ubuntu16.04分配一块磁盘空间(100G)
Win7自带分配磁盘的工具([计算机]->[管理]->[磁盘管理]->选中压缩盘->[右键]->[压缩卷]),只需要压缩步骤即可,不需要继续分盘符格式化等操作。
2.将镜像文件iso写到U盘
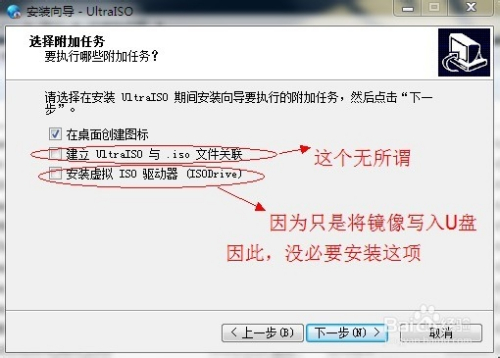
下载并安装UltraISO软件,因为我们只是要将ubuntu13.04的镜像文件写入到u盘,因此,“安装虚拟ISO驱动器(ISODriver)”没必要安装。
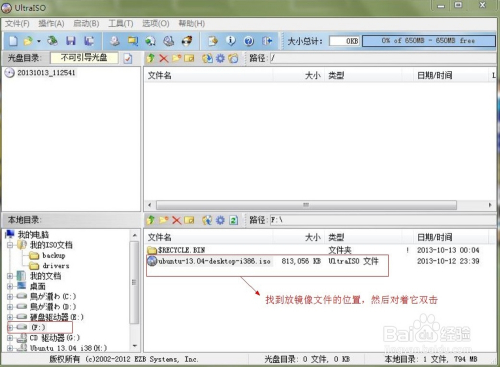
安装后输入注册码激活软件。运行UltraISO软件,在“本地目录”中查找ubuntu16.04镜像文件的位置,在右方找到后,双击该镜像文件。
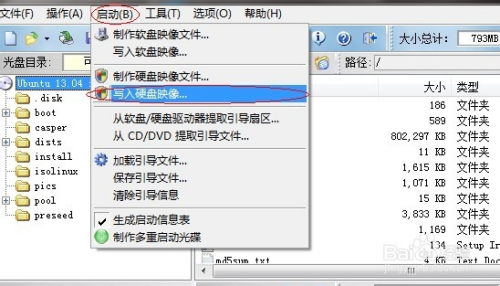
完成上步后,选择上方的“启动”--“写入硬盘映像...”。
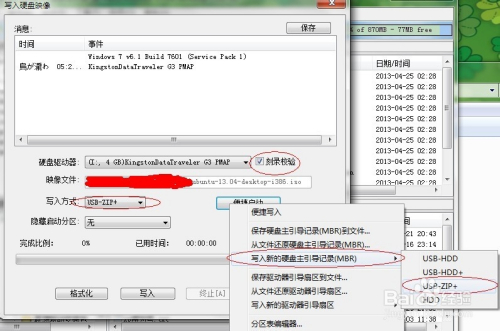
在弹出的窗口中进行如下图设置,刻录校验:打上对号;写入方式:USB-ZIP+;便捷启动:写入新的硬盘主引导记录(MBR)-USB-ZIP+。设置完毕后,单击“写入”,如下图:
上一步骤单击“写入”后,出现如下提示,请单击“是”。开始写入镜像文件,需要几分钟的等待时间。
3.安装Ubuntu16.04
1)重启计算机,从U盘启动,开机按下F12,选择“USB HDD”。
2)稍等片刻后,将进入ububtu16.04的安装界面,右侧选择“中文(简体)”,然后单击“安装Ubuntu”。
3)接下来会询问是否需要连接网络,可以联网,也可以不联网,如果联网选择安装第三方软件及更新,也可以选择不安装,安装完成后再系统里选择更新,完成后点击继续。
4)安装类型一定选择“其他选项”再继续,这样可以自己分区。
5)分区设置,如图选中空闲分区,也就是我们之前在Win7下划分出的100G的空间。
6)接下来,我们要进行四次分区,每次都是从“空闲”中分出部分区域:
第一次分区:
上一步骤点“+”,进行如下设置:挂载点:“/”;大小:22000MB;新分区的类型:主分区;新分区的位置:空间起始位置;用于:EXT4日志文件系统。
第一次分区完毕:
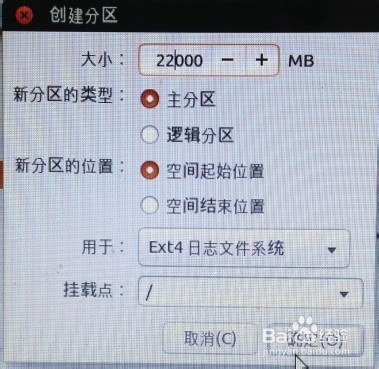
第二次分区:
“空闲”处,继续点“+”,如下设置:挂载点:(不设置);大小:2048MB;新分区的类型:逻辑分区;新分区的位置:空间起始位置;用于:交换空间。
第二次分区完毕:
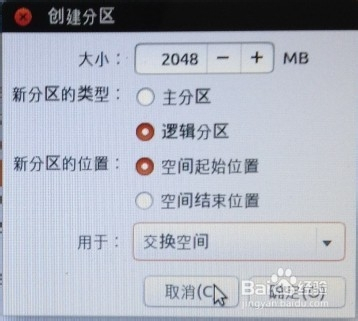
第三次分区:
“空闲”处,继续点“+”,如下设置:挂载点:/boot;大小:200MB;新分区的类型:逻辑分区;新分区的位置:空间起始位置;用于:EXT4日志文件系统。
第三次分区完毕:
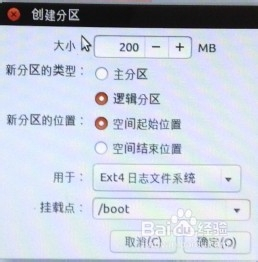
第四次分区:
“空闲”处,继续点“+”,如下设置:挂载点:/home ;大小:剩余全部空间;新分区的类型:逻辑分区;新分区的位置:空间起始位置;用于:EXT4日志文件系统。
第四次分区完毕:
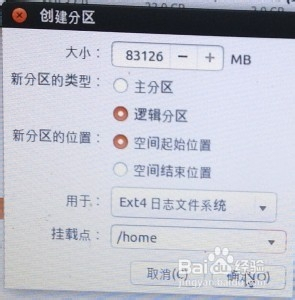
7)分区设置完毕后,下方还有一项“安装启动引导器的设备”,选择/boot所在的盘符,然后点击“现在安装”。
8)接着按提示继续,进入用户设置后,设置用户名、密码。然后进入安装界面,等待安装更新。
9)安装完成后,用所设置的用户名密码进入Ubuntu,重新启动计算机,进入到Win7系统。
4.用easyBCD修改系统启动项
安装easyBCD后打开,点击“Add New Entry”,选择Linux/BSD。
Type选择GRUB;Name自定义;Drive:选取我们设置的/boot分区,有Linux标记。设置完成后点击“Add Entry”。
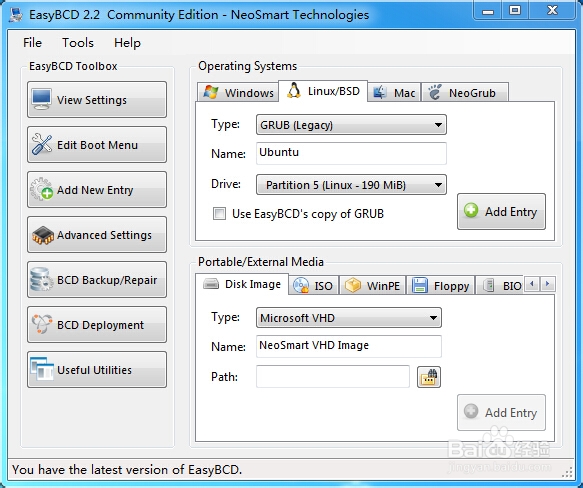
再重启电脑,现在显示Win7和Ubuntu两个启动项可以选择。
二、创建Hadoop用户
1.首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
$ sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的hadoop用户,并使用/bin/bash 作为shell。
2.接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
$ sudo passwd hadoop
3.可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
$ sudo adduser hadoop sudo
4.最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
三、更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
$ sudo apt-get update
若出现如下 “Hash校验和不符” 的提示,可通过更改软件源来解决。若没有该问题,则不需要更改。从软件源下载某些软件的过程中,可能由于网络方面的原因出现没法下载的情况,那么建议更改软件源。在学习Hadoop过程中,即使出现“Hash校验和不符”的提示,也不会影响Hadoop的安装。
后续需要更改一些配置文件,我比较喜欢用的是 vim(vi增强版,基本用法相同),建议安装一下(如果你实在还不会用 vi/vim 的,请将后面用到 vim 的地方改为 gedit,这样可以使用文本编辑器进行修改,并且每次文件更改完成后请关闭整个 gedit 程序,否则会占用终端):
$ sudo apt-get install vim
安装软件时若需要确认,在提示处输入y即可。
四、安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
$ sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
$ ssh localhost
此时会有如下提示(SSH首次登陆提示),输入yes。然后按提示输入密码 hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
$ exit # 退出刚才的 ssh localhost $ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost $ ssh-keygen -t rsa # 会有提示,都按回车就可以 $ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了。
五、安装JAVA JDK
启动火狐浏览器,下载jdk-*-linux-x*.tar.gz,解压到/opt/jdk1.8.0_*
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
问题:文件首先无法解压至/opt。
原因:opt是系统文件夹,权限受保护,需要一定的权限才可以操作。
办法:打开终端输入如下命令:
$ sudo chmod 777 /opt
Ubuntu下修改目录权限命令如下:chmod 600 name (只有所有者有读和写的权限)
chmod 644 name (所有者有读和写的权限,组用户只有读的权限)
chmod 700 name (只有所有者有读和写以及执行的权限)
chmod 666 name (每个人都有读和写的权限)
chmod 777 name (每个人都有读和写以及执行的权限)
递归修改一个目录中所有文件的权限方法:进入目录输入命令 chmod 777 -R *(其中 -R 表示递归处理,*代表所有文件)或 chmod 777 -R /home/abc/dirctoryname(此命令不用进入目录,/home/abc/dirctoryname是目录路径)。
六、安装 Hadoop 2
在Ubuntu系统打开firefox浏览器点击下面的地址下载:hadoop-2.7.1下载地址
Hadoop 2一般通过 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者 http://mirrors.cnnic.cn/apache/hadoop/common/下载最新的稳定版本,即下载 “stable” 下的 hadoop-2.x.y.tar.gz 这个格式的文件,已经编译好,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
将下载完的 Hadoop 文件解压到/opt/hadoop-2.6.0。可以将文件名改为简短的hadoop,并修改其文件权限:
$ cd /opt/hadoop-2.6.0/ $ sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop $ sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
$ cd /opt/hadoop
$ ./bin/hadoop version
七、安装scala
在浏览器中下载scala-2.11.6.tgz,解压到/opt/scala-2.11.6
下载地址: http://www.scala-lang.org/
八、安装Spark
在浏览器中下载spark-*-bin-hadoop2.6.tgz,解压到/opt/spark-*-bin-hadoop2.6
下载地址:http://spark.apache.org/downloads.html
九、配置环境变量
编辑/etc/profile,执行以下命令:
*@* :~$ sudo gedit /etc/profile
将以编辑的方式打开文件,在文件最增加:
#Seeting JDK JDK环境变量 export JAVA_HOME=/opt/jdk1.8.0_45 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH #Seeting Scala Scala环境变量 export SCALA_HOME=/opt/scala-2.11.6 export PATH=${SCALA_HOME}/bin:$PATH #setting Spark Spark环境变量 export SPARK_HOME=/opt/spark-hadoop/ #PythonPath 将Spark中的pySpark模块增加的Python环境中 export PYTHONPATH=/opt/spark-hadoop/python
重启电脑,使/etc/profile永久生效,临时生效,打开命令窗口,执行 source /etc/profile ,在当前窗口生效。
十、测试安装结果
打开命令窗口,切换到Spark根目录:
*@*:~$ cd /opt/spark-*-bin-hadoop2.6/ *@*:/opt/spark-*-bin-hadoop2.6$
执行 ./bin/spark-shell,打开Scala到Spark的连接窗口:
*@*:~$ cd /opt/spark-*-bin-hadoop2.6/ *@*:/opt/spark-*-bin-hadoop2.6$ ./bin/spark-shell
启动过程中无错误信息,出现scala>,启动成功。
执行./bin/pyspark ,打开Python到Spark的连接窗口:
*@*:/opt/spark-*-bin-hadoop2.6$ ./bin/pyspark

启动过程中无错误,在出现如上所示时,启动成功。
通过浏览器访问:出现如下页面:

测试SPark可用。
以上是关于Spark在Ubuntu中搭建开发环境的主要内容,如果未能解决你的问题,请参考以下文章