基于HTTP访问特定URL的抓包程序该怎么写
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于HTTP访问特定URL的抓包程序该怎么写相关的知识,希望对你有一定的参考价值。
抓包是一个简单易行的事,它可以帮你分析网络的行为。我记得早在2004年的时候,老师就讲过抓包有多么重要。作为程序员而言,除了抓包几乎没有任何手段探测网络行为,程序员没有机会触摸网络设备,也就没有能力洞悉网络细节,程序员唯一能触摸到的就是自己的终端,在这个终端上唯一能做的就是抓包。我是半个程序员,所以不管站在谁的立场上,我都认为抓包是一个重要的事,虽然在我内心看来,抓包和分析数据包解决不了大多数的问题。
...
在一台承载大量业务的机器上怎么抓包成了一个问题。因为虚拟主机的存在,一台机器上可以承载大量的URL,这些机器的pps动辄数以千万记,如果我们用tcpdump抓包的话,几秒钟就会抓到上G的数据,这对磁盘来讲是一个巨大的压力。在这些抓到的数据中,可能根本就没有我们想要的数据,比如我指向抓取访问www.a.b/abc的数据包,我该怎么办?!在抓包这个层面,你根本无法区分www.a.b/abc,www.a.b/def,www.123.abc/sdf...因为它们都是本地80端口的流量,你要做的不得不是把所有流量抓取,然后再用Wireshark/tshark之类的工具去分流,
关于这个分流操作,我也写了一些文章:
《 如何抓取访问特定URL的HTTP流的数据包》
《 使用Python来分离或者直接抓取pcap抓包文件中的HTTP流》
《 Python实现抓取访问特定URL的数据包》
现在的问题是,如果时间和空间不允许我这么做,我该怎么在第一时间去抓取访问特定URL的数据包呢?
访问特定URL的GET请求是在TCP三次握手(HTTP可以跑在UDP之上,但是本文只考虑TCP的情况)之后才发出的,此时一个数据流已经建立了!在决定是否要基于URL抓取一个流之前,这个流已经建立了,因此当看到一个TCP握手过程时,根本不知道这是不是一个感兴趣的流!这就是问题所在。因此,为了使得一个流的抓包完整,必须在碰到URL之前,缓存从握手包开始的所有数据包。当发现有感兴趣的URL时,输出之前缓存的所有数据包,当在可以承受的时间范围内没有发现感兴趣的URL,则释放缓存的数据包。这就是基本的思路。如果有一个pcap包,按照上述思路去分离感兴趣的数据流是一个比较简单的事,用Python可以分秒搞定,这在我前面的文章也有提及。然而本文要讲述的则是实时抓取这样的数据包,而不是事后分析。
我起初想在tcpdump程序里面做,建立一个HASH表保存每一个五元组流,类似Netfilter的nf_conntrack那样,事实上这么做也是容易的。然而不够优雅,因为这个HASH表有冗余!跟谁冗余呢?答案是跟内核维护的socket HASH表冗余了。socket HASH表是一个天然的连接跟踪信息池啊。我并不鄙视Python的字典,元组,List的实现效率,但是我觉得直接利用内核的socket HASH表会更好!换句话说,如果我能在这个socket结构体中记录这个socket的数据包要不要抓取,那只要我能将一个skb(即数据包)对应到一个socket,就万事大吉了。系统中既然已经有了这么一个组织良好的HASH表,我干嘛还要自己再创建一个呢?
...其实我根本没有想自己创建,我只是利用了Python的内建数据类型而已!然而我连这个也不想用了,那么我直接利用socket!socket对应一个五元组,对应一个数据流,如果说我只是想在服务所在的本机抓包,这个socket的利用正是将数据包状态化的必杀技!
为了实现以上的想法,我需要在sock结构体里加字段吗?看样子是的。然而这需要重新编译内核!为了不重新编译,我发现可以利用sock结构体的sk_flags字段完成这个需求。sk_flags字段中的高4位是没有被用到的,因为我准备借用它们!
这样,sock结构体的高4位形成了一个状态机:
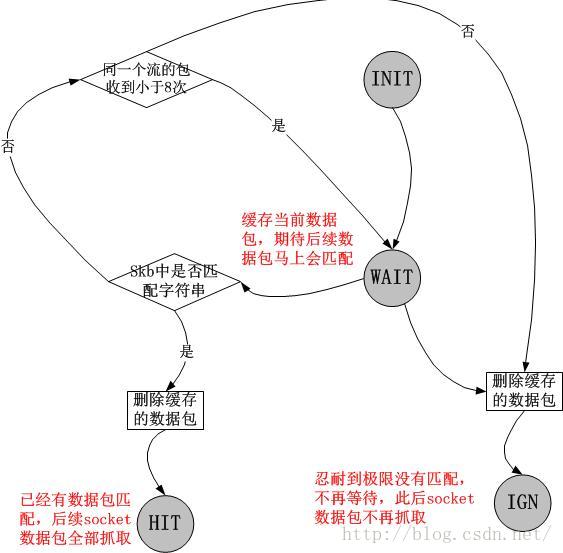
实现这个状态机的流程图我就不画图了,没有时间...我觉得代码的注释还算清晰。把上述的状态机以及流程图编程实现,就是下面的这个Netfilter模块:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/skbuff.h>
#include <linux/list.h>
#include <linux/ip.h>
#include <net/tcp.h>
MODULE_AUTHOR("marywangran");
MODULE_LICENSE("GPL");
#define CAP_HIT 31
#define CAP_WAIT 30
#define CAP_IGN 29
#define CAP_DEL 28
#define MAX_CACHE 8
unsigned char *url = "test";
struct wait_entry {
struct list_head list;
u16 cnt;
__be32 saddr;
__be32 daddr;
u16 sport;
u16 dport;
unsigned long save_flags;
struct sk_buff *skb[MAX_CACHE];
};
static DEFINE_SPINLOCK(caplist_lock);
static LIST_HEAD(wait_list);
static struct wait_entry * find_add_entry(struct sk_buff *skb)
{
struct list_head *lh, *n;
struct wait_entry *wn;
struct iphdr *iph = ip_hdr(skb);
struct tcphdr *th = (void *)iph + iph->ihl*4;
u32 cmp_saddr, cmp_daddr;
u16 cmp_sport, cmp_dport;
cmp_saddr = iph->saddr > iph->daddr ? iph->saddr:iph->daddr;
cmp_daddr = iph->saddr > iph->daddr ? iph->daddr:iph->saddr;
cmp_sport = th->source > th->dest ? th->source:th->dest;
cmp_dport = th->source > th->dest ? th->dest:th->source;
spin_lock(&caplist_lock);
list_for_each_safe(lh, n, &wait_list) {
wn = list_entry(lh, struct wait_entry, list);
if (cmp_saddr == wn->saddr &&
cmp_daddr == wn->daddr &&
cmp_sport == wn->sport &&
cmp_dport == wn->dport) {
if (wn->cnt < MAX_CACHE) {
wn->skb[wn->cnt] = skb_clone(skb, GFP_ATOMIC);;
wn->cnt += 1;
spin_unlock(&caplist_lock);
return wn;
} else {
int i = 0;
for (i = 0; i < wn->cnt; i++) {
if (wn->skb[i]) {
kfree_skb(wn->skb[i]);
}
}
list_del(lh);
kfree(wn);
spin_unlock(&caplist_lock);
return NULL;
}
}
}
wn = (struct wait_entry *)kzalloc(sizeof(struct wait_entry), GFP_ATOMIC);
wn->saddr = iph->saddr > iph->daddr ? iph->saddr:iph->daddr;
wn->daddr = iph->saddr > iph->daddr ? iph->daddr:iph->saddr;;
wn->sport = th->source > th->dest ? th->source:th->dest;
wn->dport = th->source > th->dest ? th->dest:th->source;
wn->skb[0] = skb_clone(skb, GFP_ATOMIC);;
wn->cnt = 1;
__set_bit(CAP_WAIT, &wn->save_flags);
list_add(&wn->list, &wait_list);
spin_unlock(&caplist_lock);
return wn;
}
char *findstr(const char *s1, const char *s2, unsigned int len)
{
int l1, l2;
l2 = strlen(s2);
if (!l2)
return (char *)s1;
l1 = len;
while (l1 >= l2) {
l1--;
if (!memcmp(s1, s2, l2))
return (char *)s1;
s1++;
}
return NULL;
}
static int string_match(struct sk_buff *skb, char *str)
{
char *ret = NULL;
ret = findstr(skb->data, str, 512);
if (ret) {
return 1;
}
return 0;
}
static void capture_skb(struct sk_buff *skb, const struct net_device *dev)
{
struct iphdr *iph = ip_hdr(skb);
struct tcphdr *th = (void *)iph + iph->ihl*4;
u16 sport = 0, dport = 0;
u32 saddr = 0, daddr = 0;
saddr = iph->saddr;
daddr = iph->daddr;
sport = th->source;
dport = th->dest;
// 简单打印而已
printk("###print %0x %0x %0x %0x S:%u A:%u len:%u\\n", saddr, daddr, sport, dport, ntohl(th->seq), ntohl(th->ack_seq), skb->len);
}
static void check_pcap(struct sock *sk, struct sk_buff *skb, char *url, int hook, const struct net_device *dev)
{
struct wait_entry *entry = NULL;
if (sk->sk_state == TCP_LISTEN) {
// 这里注意半连接攻击!所以需要entry表项的超时机制。
entry = find_add_entry(skb);
if (!entry) {
goto out;
}
// 注意TCP_DEFER_ACCEPT选项,该选项允许在Listen状态下接收GET请求!
if (url && string_match(skb, url)) {
int i = 0;
spin_lock(&caplist_lock);
// 如果匹配到了字符串,那么就把之前缓存的最多8个数据包一并导出,如果要实现好一些,在缓存这些数据包时就要把时间戳带上,不然这里会有一个突发。
for (i = 0; i < entry->cnt; i++) {
capture_skb(entry->skb[i], dev);
}
spin_unlock(&caplist_lock);
// 由于此时的Listen状态socket并不对应五元组,因此entry作为一个五元组替代要保存flags信息,最终这个flags要映射到建立好的ESTABLISH socket中!
// 匹配成功,这个entry对应的最终的socket flag要有HIT标志,表示这个socket上的数据包均需要抓取。
__set_bit(CAP_HIT, &entry->save_flags);
// 匹配成功,等这个entry代表的元组创建了ESTABLISH socket之后,将flags转交给该socket的flags后,就要删除它,因为已经不需要了。
__set_bit(CAP_DEL, &entry->save_flags);
// 匹配成功,不要继续等待GET了,清除WAIT标识
__clear_bit(CAP_WAIT, &entry->save_flags);
}
} else if (sk->sk_state == TCP_TIME_WAIT) {
//TODO
} else {
int add = 0;
if (!sock_flag(sk, CAP_IGN) && !sock_flag(sk, CAP_WAIT) && !sock_flag(sk, CAP_HIT)) {
// 这里代表这是第一次从Listen状态进入ESTABLISH状态
entry = find_add_entry(skb);
if (entry) {
// 转交entry的flags到socket(注意只使用了高4位)
sk->sk_flags |= (entry->save_flags & 0xf0000000);
if (test_bit(CAP_DEL, &entry->save_flags)) {
// 如果设置了DEL位,说明已经匹配成功,不需要这个entry了,直接删除
// 注意,此时的flags同时也有了HIT位
int i = 0;
spin_lock(&caplist_lock);
for (i = 0; i < entry->cnt; i++) {
if (entry->skb[i]) {
kfree_skb(entry->skb[i]);
}
}
list_del(&entry->list);
kfree(entry);
entry = NULL;
spin_unlock(&caplist_lock);
}
} else {
// 如果根本就没有经过Listen,或者说在Listen阶段就被删除了entry,直接忽略,关于此socket,永不抓包
sock_set_flag(sk, CAP_IGN);
goto out;
}
add = 1;
}
if (sock_flag(sk, CAP_HIT)) {
// 携带HIT标志的,抓包。
capture_skb(skb, dev);
} else if (sock_flag(sk, CAP_WAIT)){
// 携带WAIT标志的,继续等待数据包,期待在收发8个数据包内匹配到特定的URL
if (add == 0) {
entry = find_add_entry(skb);
}
if (!entry) {
sock_set_flag(sk, CAP_IGN);
sock_reset_flag(sk, CAP_WAIT);
goto out;
}
if (url && string_match(skb, url)) {
int i = 0;
spin_lock(&caplist_lock);
// 如果匹配到了字符串,那么就把之前缓存的最多8个数据包一并导出,如果要实现好一些,在缓存这些数据包时就要把时间戳带上,不然这里会有一个突发。
for (i = 0; i < entry->cnt; i++) {
capture_skb(entry->skb[i], dev);
}
// 匹配成功,HIT位将进入socket的flags,不再需要继续等待匹配,无需缓存未决数据包了,删除entry
for (i = 0; i < entry->cnt; i++) {
if (entry->skb[i]) {
kfree_skb(entry->skb[i]);
}
}
list_del(&entry->list);
kfree(entry);
spin_unlock(&caplist_lock);
sock_set_flag(sk, CAP_HIT);
sock_reset_flag(sk, CAP_WAIT);
} // ignore
}
}
out:
return;
}
static unsigned int ipv4_tcp_urlcap_in (unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
struct sock *sk;
struct iphdr *iph = ip_hdr(skb);
struct tcphdr *th = (void *)iph + iph->ihl*4;
if (iph->protocol != IPPROTO_TCP) {
return NF_ACCEPT;
}
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest);
if (!sk) {
goto out;
}
skb->sk = sk;
check_pcap(sk, skb, url, hooknum, in);
out:
return NF_ACCEPT;
}
static unsigned int ipv4_tcp_urlcap_out (unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
struct sock *sk;
struct iphdr *iph = ip_hdr(skb);
if (iph->protocol != IPPROTO_TCP) {
return NF_ACCEPT;
}
sk = skb->sk;
if (!sk) {
goto out;
}
check_pcap(sk, skb, url, hooknum, out);
out:
return NF_ACCEPT;
}
static struct nf_hook_ops ipv4_urlcap_ops[] __read_mostly = {
{
.hook = ipv4_tcp_urlcap_in,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = -199,
},
{
.hook = ipv4_tcp_urlcap_out,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = -199,
},
};
static int __init url_cap_init(void)
{
int ret;
ret = nf_register_hooks(ipv4_urlcap_ops, ARRAY_SIZE(ipv4_urlcap_ops));
if (ret) {
goto out;;
}
return 0;
out:
return ret;
}
static void __exit url_cap_fini(void)
{
nf_unregister_hooks(ipv4_urlcap_ops, ARRAY_SIZE(ipv4_urlcap_ops));
}
module_init(url_cap_init);
module_exit(url_cap_fini); 然后,我们来测试一下。将该模块加载在一台运行Apache Web服务器的主机1.1.1.2上,/var/www/html目录下放两个小文件,一个是big10,另一个是test,将该模块的URL匹配关键字设置成“test”,那么当我执行curl http://1.1.1.2/big10的时候,dmesg没有任何输出,然而当我执行curl http://1.1.1.2/test的时候,dmesg输出了所有交互包的五元组以及序列号信息。
面临的问题
0.能写出代码完全在于一个前提
这个前提是,HTTP的GET请求会在TCP三次握手之后的固定的数量数据包内到来,比如我取的是8!一般而言,三次握手一共3个包,此后预期客户端马上就会有GET请求到来,加上重传等不固定行为,也会在预期的8个数据包内到达。然而如果有的WEB实现,在10个包之内没有GET请求,或者一个TCP连接内有多个GET请求,本程序就无能无力了。1.无法处理本机作为客户端的情况
不要以为skb是一个简单的结构体,其data字段并不一定保存了数据包的数据。对于接收路径的skb,一般而言data就表示数据内容,然而对于发送路径,为了处理的高效,一般而言并不会进行内存的合并拷贝,而是采用类似分散/聚集IO的方式,“让数据呆在应用层的原地不动”然后让驱动去自行予取予求。因此为了匹配个字符串,你不得不去解析skb的frag字段,碰到page结构体,处理时为了读取数据还要临时内存映射等...因此对于发送路径的匹配,本程序暂不支持!2.IP层Netfilter的抓包和PACKET套接字抓包存在差异
注意,以上的代码工作在IP层的Netfilter,而真正的抓包则是工作在紧贴着网卡之上的位置,在这两者中间有一个“队列模块”,对于Linux而言就是Qdisc。我们可以从该模块导出的数据以及真正的抓包之间的对比来看一下究竟,这种差异主要表现在时间戳和数据包序列上,曾经我用tcpprobe工具导出的数据和用tcpdump抓取的数据严重不一致,这就是隔了这么个Qdisc引起的,详情参见《 流量整形,延迟以及ACK丢失对TCP发送时序的影响》。对于本文而言,由于我没有配置任何TC规则,所以二者看起来是一致的: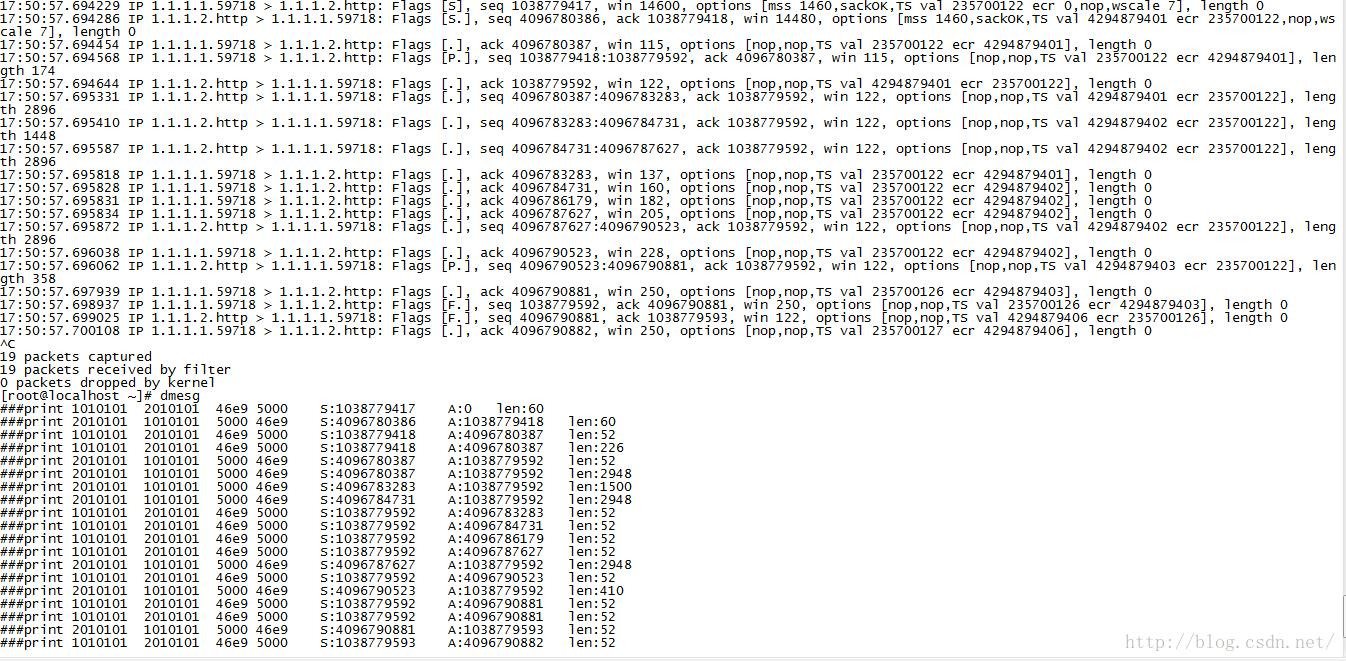
要保持与tcpdump结果的一致性,就必须保持PACKET套接字抓包的位置不变,Netfilter模块只是为了给一个skb打上特定的标签,对于发送路径,这很容易,Netfilter模块为skb打签,然后在网卡xmit函数中抓包时抓取打上签的skb即可,但是对于接收路径,由于Netfilter早就已经过了netif_receive_skb这个底层函数,所以说需要在Netfilter模块为skb打上标签之后,重新将其clone一份注入到一个虚拟设备模拟数据包接收,让打签的skb再次经过netif_receive_skb完成抓包!
千万不要觉得这种方式会损失性能,在实际能工作之前就考虑性能的,得到的都是浮云!再者,Linux的Bridge,VLAN,Bonding以及IMQ,全都是这么干的。
3.编码有待优化
可以看到,我使用了list_head以及spin_lock,而不是使用hlist以及rcu,这就说明,在系统开销方面,还是可以有很大的优化空间的。另外,我只是在内核中打印了数据包的元数据,并没有真正的去用PACKET套接字抓包,曾经我想让温州皮鞋厂老板帮我搞一下,但是被皮鞋老板拒绝了。以上是关于基于HTTP访问特定URL的抓包程序该怎么写的主要内容,如果未能解决你的问题,请参考以下文章