利用backgroundwork----递归读取网页源代码,并下载href链接中的文件
Posted stonewl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用backgroundwork----递归读取网页源代码,并下载href链接中的文件相关的知识,希望对你有一定的参考价值。
今天闲着没事,研究了一下在线更新程序版本的问题。也是工作中的需要,开始不知道如何下手,各种百度也没有找到自己想要的,因为我的需求比较简单,所以就自己琢磨了一下。讲讲我的需求吧。自己在IIs上发布了一个网站,这个网站仅仅只是内部使用的,网站的内容就是我的另外一个程序(就叫A程序吧)的打包发布的文件放进去。然后在客户端启动我的A程序之前检查是否有新版本文件发布。如果有,我根据网页源代码的信息和本地文件信息进行比较,决定是否下载。如果有下载,下载完成后执行A程序的.exe文件启动A程序。大致的要求就是这样。
首先自己发布一个测试网站,也就是简单的在IIS上将我本机的一个文件夹发布出来,具体怎么操作就不做讲解了。得到我的网址:http://localhost/webTest/。这个网站就作为我以后有新版本文件要发布就直接丢进去。
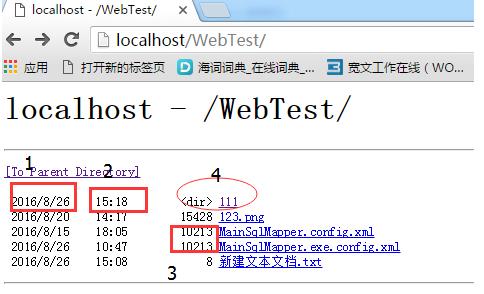
上面的截图中有几个地方需要注明一下:
1.是这个文件最后一次编辑日期。
2.是最后一次编辑时间点。
3.是你这个文件的大小。
4.椭圆部分是一个文件夹。
前面标题说用递归,就是因为网站中可能存在子文件夹,遇到子文件夹我就要继续跟进去读取源代码获取我要的信息。
注:网页中有个[to parent Directory]这是他的父文件夹,我们在读取网页源代码的时候要对这部分进行处理
注:1,2部分是指这个文件最后一次编辑时间,比如说你在本地有个文件你对他进行最后一次的编辑时间2016/8/26 13:15 那不管你把这个文件拷贝或是上传到其他地方,那他的编辑时间始终不会变的。
大致的情况介绍的差不多了,接下来直接开始我的读取网页下载文件的程序吧!上代码,一如既往,图文并茂的文章才是好文章。
一、创建一个winform工程。
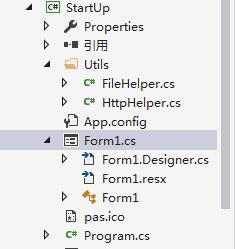
图(1):工程结构

图(2):winform需要的控件
图(1)中我添加了两个帮助类:FileHelper.cs/HttpHelper.cs。在后面做详细介绍
图(2)中1是一个label控件,用来显示正在下载的文件名。2是progressBar控件,winform自带的进度条控件,我觉得还挺好用的。。还需要一个backgroundwork控件
二:帮助类文件
FileHelper.cs帮助类文件。


1 public class FileHelper 2 { 3 public DateTime ModiDate { get; set; } //最后编辑时间 4 5 public long Size { get; set; } //文件大小 6 7 public String FilePath { get; set; } //路径+文件名 8 }
HttpHelper.cs
1 /// <summary> 2 /// 获取网页源代码 3 /// </summary> 4 /// <param name="serverUrl">网址</param> 5 /// <param name="listFile">存放下载文件的集合</param> 6 /// <param name="listHref">存放子目录集合</param> 7 8 public static void GethtmlResource(string serverUrl, List<FileHelper> listFile, List<string> listHref) 9 { 10 #region 11 //Uri u = new Uri(serverUrl); 12 //string host = u.Host; 13 //if (serverUrl.EndsWith("/")) 14 //{ 15 // //1.获取网页源代码 16 // WebClient wc = new WebClient(); 17 // wc.Credentials = CredentialCache.DefaultCredentials; 18 // byte[] htmlData = wc.DownloadData(serverUrl); 19 // string htmlStr = Encoding.Default.GetString(htmlData); 20 // //2.正则找到href属性内容截取 21 // string regMat = @"(?is)<a[^>]*?href=([\'""\\s]?)(?<href>[^\'""\\s]*)\\1[^>]*?"; 22 // MatchCollection mat = Regex.Matches(htmlStr, regMat, RegexOptions.IgnoreCase); 23 // List<string> listHref = new List<string>(); //存放href结合 24 // for (int i = 0; i < mat.Count; i++) 25 // { 26 // string item = mat[i].Groups["href"].Value; 27 // listHref.Add(item); 28 // MatchCollection match = Regex.Matches(htmlStr, "([0-9]{1,})\\\\s\\\\<A\\\\sHREF=\\""+ item+"\\"", RegexOptions.IgnoreCase); 29 // if(match.Count == 1 && match[0].Groups.Count==2) 30 // { 31 // fileSize.Add(@"http://" + host + item, int.Parse(match[0].Groups[1].Value)); 32 // } 33 // } 34 // foreach (var item in listHref) //Match item in mat 35 // { 36 // string url = @"http://"+host + item; 37 // if (serverUrl.StartsWith(url)) 38 // { 39 // continue; 40 // } 41 // GetHtmlResource(url, serverFilePath,fileSize); 42 // } 43 //} 44 //else 45 //{ 46 // serverFilePath.Add(serverUrl); 47 //} 48 #endregion 49 50 Uri u = new Uri(serverUrl); 51 string host = u.Host; 52 if (serverUrl.EndsWith("/")) 53 { 54 //1.获取网页源代码 55 WebClient wc = new WebClient(); 56 wc.Credentials = CredentialCache.DefaultCredentials; 57 byte[] htmlData = wc.DownloadData(serverUrl); 58 string htmlTempStr = Encoding.Default.GetString(htmlData); 59 //完全用字符串截取的方式得到自己想要的东西 60 htmlTempStr = htmlTempStr.Substring(htmlTempStr.IndexOf("<pre>")); 61 htmlTempStr = htmlTempStr.Substring(0, htmlTempStr.IndexOf("</pre>")); 62 htmlTempStr = htmlTempStr.Replace("<pre>", ""); 63 htmlTempStr = htmlTempStr.Replace("</pre>", ""); 64 htmlTempStr = htmlTempStr.Replace("<dir>", "-1"); //把子菜单前面的"<dir&"改为-1,为了跟其他的信息一致有规律 65 htmlTempStr = htmlTempStr.Replace("<br>", "#"); 66 string[] tempStr = htmlTempStr.Split(\'#\'); 67 ArrayList listStr = new ArrayList(tempStr); 68 //移除每个新网页的父级文件夹 69 listStr.RemoveAt(0); 70 for (int i = 0; i < listStr.Count; i++) 71 { 72 if (String.IsNullOrWhiteSpace(listStr[i].ToString())) 73 { 74 listStr.RemoveAt(i); 75 } 76 } 77 tempStr = (string[])listStr.ToArray(typeof(string)); 78 79 for (int f = 0; f < tempStr.Length; f++) 80 { 81 //截取最后修改日期带时间 82 string fileModiTime = tempStr[f].Substring(0, 20); 83 //截取文件大小 84 string fileSize = tempStr[f].Substring(20, tempStr[f].IndexOf("<A") - 20); 85 //截取文件路径 86 string filePath = tempStr[f].Split(\'\\"\')[1]; 87 FileHelper file = new FileHelper(); 88 file.ModiDate = Convert.ToDateTime(fileModiTime.Trim()); 89 file.Size = Convert.ToInt32(fileSize.Trim()); 90 file.FilePath = @"http://" + host + filePath; 91 //如果大小为-1,我就认为是子文件夹,添加到集合中 92 if (file.Size == -1) 93 { 94 listHref.Add(file.FilePath); 95 } 96 else 97 { 98 //添加到要下载的文件集合中 99 listFile.Add(file); 100 } 101 } 102 //循环我的子文件夹集合 103 foreach (var item in listHref) 104 { 105 //如果item等于我的serverUrl继续 106 if (serverUrl.StartsWith(item)) 107 { 108 continue; 109 } 110 //递归 111 GetHtmlResource(item, listFile, listHref); 112 } 113 114 } 115 }
1 /// <summary> 2 /// 下载文件 3 /// </summary> 4 /// <param name="serverUrl">文件在服务器的全路径</param> 5 /// <param name="localFilePath">下载到本地的路径</param> 6 public static void DownLoadMdiFile(string serverUrl,string localFilePath) 7 { 8 //localFilePath = localFilePath.Replace(".exe.config.xml", ".exe.config"); 9 if (localFilePath.Contains(".exe.config.xml")) 10 { 11 localFilePath = localFilePath.Replace(".exe.config.xml", ".exe.config"); 12 } 13 if (localFilePath.Contains(".config.xml")) 14 { 15 localFilePath = localFilePath.Replace(".config.xml", ".config"); 16 } 17 //网页中子文件夹是否存在,如果不存在,创建文件夹,存在直接下载文件 18 FileInfo file = new FileInfo(localFilePath); 19 if(!file.Directory.Exists) 20 { 21 Directory.CreateDirectory(file.Directory.FullName); 22 23 } 24 try 25 { 26 WebClient wc = new WebClient(); 27 if (!localFilePath.Contains("web.config")) 28 { 29 wc.DownloadFile(serverUrl, localFilePath); 30 } 31 } 32 catch (Exception e) 33 { 34 throw; 35 } 36 }
三:banckgroundwork控件
对于这个控件我需要实现他的三个事件。很简单的三个事件,看事件名称就能知道他的意思了
第一个:backgroundWorker1_DoWork
1 private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e) 2 { 3 #region 4 //string installUrl = GetInstallPath(); 5 //List<string> listFilePath = new List<string>(); 6 //Dictionary<string, int> fileSize = new Dictionary<string, int>(); 7 //HttpHelper.GetHtmlResource(installUrl, listFilePath, fileSize); 8 //for (int i=0;i<listFilePath.Count;i++) 9 //{ 10 // if (backgroundWorker1.CancellationPending) 11 // { 12 // e.Cancel = true; 13 // return; 14 // } 15 // double total = listFilePath.Count; 16 // double current = i+1; 17 // int progress = (int)(current / total * 100); 18 // string serverUrl = listFilePath[i]; 19 // int size = fileSize[serverUrl]; 20 // backgroundWorker1.ReportProgress(progress, serverUrl.Replace(installUrl, "")); 21 // string localPath = serverUrl.Replace(installUrl, localInstallPath); 22 // if (File.Exists(localPath)) 23 // { 24 // FileStream fs = new FileStream(localPath, FileMode.Open); 25 26 // if (fs.Length != size) 27 // { 28 // try 29 // { 30 // HttpHelper.DownLoadMdiFile(serverUrl, localPath); 31 // } 32 // catch (Exception ) 33 // { 34 // throw; 35 // } 36 // } 37 // fs.Close(); 38 // } 39 // else 40 // { 41 // HttpHelper.DownLoadMdiFile(serverUrl, localPath); 42 // } 43 //} 44 #endregion 45 string installUrl = GetInstallPath(); 46 List<string> listHref = new List<string>();//存放子文件夹集合 47 List<FileHelper> listFile = new List<FileHelper>();//存放下载文件集合 48 HttpHelper.GetHtmlResource(installUrl, listFile, listHref); 49 for (int i = 0; i < listFile.Count; i++) 50 { 51 if (backgroundWorker1.CancellationPending) 52 { 53 e.Cancel = true; 54 return; 55 } 56 double total = listFile.Count; 57 double current = i + 1; 58 int progress = (int)(current / total * 100); 59 //服务器文件+全路径 60 string serverUrl = listFile[i].FilePath; 61 //服务器文件大小 62 long size = listFile[i].Size; 63 //服务器文件最后修改时间 64 DateTime modiTine = listFile[i].ModiDate; 65 //backgroundWorker1执行到那个阶段 66 backgroundWorker1.ReportProgress(progress, serverUrl.Replace(installUrl, "")); 67 string localPath = serverUrl.Replace(installUrl, localInstallPath); 68 //判断文件是否存在 69 if (File.Exists(localPath)) 70 { 71 //获取本地文件 72 FileInfo fs = new FileInfo(localPath); 73 //如果服务器文件大小,最后修改时间和本地文件进行对比,是否有变化 74 if (fs.Length != size || fs.LastWriteTime != modiTine) 75 { 76 77 try 78 { 79 HttpHelper.DownLoadMdiFile(serverUrl, localPath); 80 } 81 catch (Exception) 82 { 83 84 throw; 85 } 86 } 87 88 } 89 else 90 { 91 HttpHelper.DownLoadMdiFile(serverUrl, localPath); 92 } 93 } 94 }
第二个:backgroundWorker1_ProgressChanged
1 private void backgroundWorker1_ProgressChanged(object sender, ProgressChangedEventArgs e) 2 { 3 this.progressBar.Value = e.ProgressPercentage; 4 var display = e.UserState.ToString(); 5 labDisplay.Text = display.Trim(); 6 //lbl_pbvalue.Text = "更新进度" + e.ProgressPercentage + "%"; 7 }
第三个:backgroundWorker1_RunWorkerCompleted
1 private void backgroundWorker1_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e) 2 { 3 runningPath += "A.exe"; 4 try 5 { 6 System.Diagnostics.Process.Start(runningPath); 7 } 8 catch (Exception ex) 9 { 10 MessageBox.Show(ex.Message); 11 } 12 13 this.Close(); 14 }
在使用backgroundwork和progressBar控件的时候需要注意几个点
this.backgroundWorker1.WorkerReportsProgress = true; 用于进度条更新
this.backgroundWorker1.WorkerSupportsCancellation = true; 提供中途终止进程
this.progressBar.Maximum = 100;给一个最大值
好吧!就这样一个简单的在线更新文件的程序就搞定啦!
【转载注明出处!谢谢】
以上是关于利用backgroundwork----递归读取网页源代码,并下载href链接中的文件的主要内容,如果未能解决你的问题,请参考以下文章