记录一个不同的流媒体网站实现方法,和用Python爬虫爬它的坑
Posted lyj00912
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录一个不同的流媒体网站实现方法,和用Python爬虫爬它的坑相关的知识,希望对你有一定的参考价值。
今天找到一片电影,想把它下载下来。
先开Networks工具分析一下:
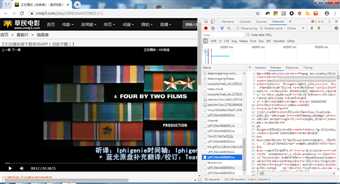
初步分析发现,视频加载时会拉取TS格式的文件,推测这是一个m3u8的索引,记录着几百段TS文件,这样方便快进时加载。
但是实际分析m3u8文件时,发现这并不是一个有效的索引文件,应该只是载入一个形式,实际的handler在其他地方:
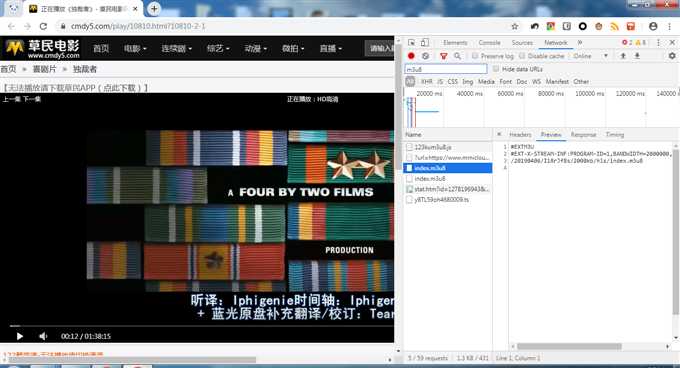
但这样分析js太麻烦了。通过几次尝试,发现了规律:视频文件名是由y8TL59oh4680xxx.ts组成的,xxx是序号,这样就简单多了!
把之前爬音乐文件的爬虫改一改,得到这样一个程序:
import requests import os import re from tkinter import Tk from tkinter.simpledialog import askinteger, askfloat, askstring from tkinter.filedialog import askopenfilename, askopenfilenames, asksaveasfilename, askdirectory from tkinter.messagebox import showinfo, showwarning, showerror def downloadSong(SongID, FileName): headers = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/39.0.2171.71 Safari/537.36"} r = requests.get("https://www.mmicloud.com/20190406/I1RrJf8s/2000kb/hls/y8TL59oh" + str(SongID) + ".ts",headers=headers); #print("State:") #print(r) filepath=os.path.join(str(SongID) + ".ts") with open(filepath,"wb") as file: file.write(r.content) print(SongID) for i in range(4680000, 4680900): downloadSong(i, str(i))
这个程序循环爬取文件名从y8TL59oh4680000.ts到y8TL59oh4680899.ts的900个视频文件。
程序中的循环最大值之所以定在4680900,是因为我发现影片有860多段,于是就多下载一些,如果下载不了就是下完了,出错倒也无所谓。
让他开始运行,看起来工作良好,有在顺利的下载文件:
于是我就放下手头的事,先休息去了。过了大约半个小时,他已经下载了300多个文件了:
我就放下心来,这个爬虫应该是没什么问题了,于是我就用VSCode写了一些代码。当我再次看到任务栏时,爬虫已经不见了!
我再次启动爬虫,过了一会又会有同样的问题!难道是变量i溢出了?试着debug一下,把i的范围缩小试试:
import requests import os import re from tkinter import Tk from tkinter.simpledialog import askinteger, askfloat, askstring from tkinter.filedialog import askopenfilename, askopenfilenames, asksaveasfilename, askdirectory from tkinter.messagebox import showinfo, showwarning, showerror def downloadSong(SongID, FileName): headers = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36"} r = requests.get("https://www.mmicloud.com/20190406/I1RrJf8s/2000kb/hls/y8TL59oh4680" + str(SongID) + ".ts",headers=headers); #print("State:") #print(r) filepath=os.path.join(str(SongID) + ".ts") with open(filepath,"wb") as file: file.write(r.content) print(SongID) for i in range(566, 900): downloadSong(i, str(i))
经过debug,发现程序应该是没有问题,只是因为控制台窗口最小化时,爬虫会被内存回收掉,所以导致了程序退出。
折腾了半天!
我换成用IDLE编辑器自带的Run Modules,有普通窗口的话就不容易被回收掉把:
过了一阵子,爬虫终于把文件爬完了。一看文件夹,又出问题了:
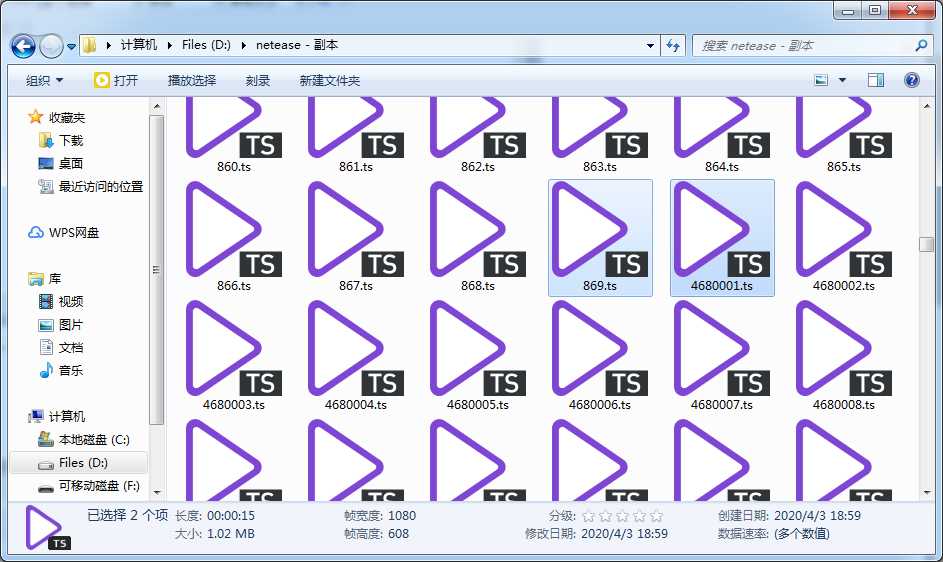
文件名不一致!
还记得之前我们debug的时候把变量i的范围改小了吗?这就是原因!
那好吧,选中所有名字长的文件,右键,重命名,命名成a,然后文件就可以自动命名为a (1), a (2), a (3), a (4), a (5), ...这样。
问题。。解决了?
我拿着这些命名为a (1), a (2), a (3), a (4), a (5), ...的文件去转码,合并,来来回回整了一个小时多。当合并之后,才发现,
文件顺序全是乱的!!!
啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊天煞的Windows!!!!!!!!!!
没办法,有气出不来,只好继续写代码。。。
还好我留了一份没有重命名过的文件夹,那就用python写一个批量重命名程序吧:
import os PROJECT_DIR_PATH = os.path.dirname(os.path.abspath(os.path.abspath(__file__))) DIR_PATH = os.path.join(PROJECT_DIR_PATH, ‘data‘) files = os.listdir(DIR_PATH) for filename in files: name, suffix = os.path.splitext(filename) new_name = os.path.join(DIR_PATH, name[4:7]) old_name = os.path.join(DIR_PATH, filename) os.rename(old_name, new_name)
把文件目录改成这样,就可以使用上面的程序了:
爽爽快快的运行完程序,发现命名是成功了,但后缀名没有了。。。
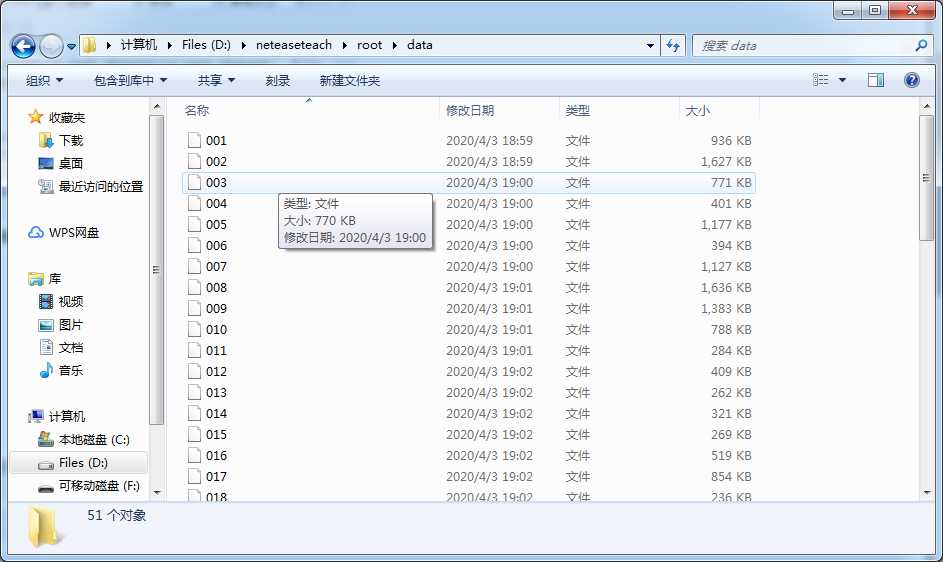
失误失误!再写一个补救程序:
import os PROJECT_DIR_PATH = os.path.dirname(os.path.abspath(os.path.abspath(__file__))) DIR_PATH = os.path.join(PROJECT_DIR_PATH, ‘data‘) files = os.listdir(DIR_PATH) for filename in files: name, suffix = os.path.splitext(filename) new_name = os.path.join(DIR_PATH, filename + ".ts") old_name = os.path.join(DIR_PATH, filename) os.rename(old_name, new_name)
心惊胆战的运行完,目录终于正常了:
然后又是转码、合并,又是一个多小时。最后,总算拿到了胜利的果实:

太难了!
下载这篇电影花费了我一整天的时间。上午和中午找片源,下午写代码+写爬虫+爬资源,晚上还得操心重命名和转码的问题,这中间都够我看6-7片电影了。ε=(´ο`*)))唉。。。
不多说了,电影只能明天看了。各位,晚安!
以上是关于记录一个不同的流媒体网站实现方法,和用Python爬虫爬它的坑的主要内容,如果未能解决你的问题,请参考以下文章