汇编器构造
Posted Florian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了汇编器构造相关的知识,希望对你有一定的参考价值。
汇编器构造
一、 汇编器简介
前面介绍了编译器构造和静态链接器构造的具体方法,而且我们实现了一个将高级语言转化为汇编语言的编译器,同时又实现了一个将多个目标文件链接为一个可执行文件的链接器。现在需要一个连接这两个模块的功能模块——汇编器,它能将一个单独的汇编文件转换为一个可重定位目标文件,如图1-1反映出汇编器在整个编译系统中的地位和功能。

图 1-1 静态编译步骤
从本质上讲,汇编器也是编译器,只是它和我们熟知的编译器的有略微的差别。汇编器处理的“高级语言”是汇编语言,输出的是机器语言二进制形式。因此,对于汇编器的构造,实质上和编译器大同小异,也都需要进行词法分析、语法分析、语义处理、符号表管理和代码生成(机器代码)等阶段。
对于编译器来说,代码生成阶段只需要将解析的语法树映射到汇编语言子模块即可(当然还要考虑指令优化问题),而对于汇编器,将解析出的指令简洁的映射到正确机器代码相对比较复杂。另外,由于本汇编器处理的输入文件为编译器生成的汇编文件,经测试,编译生成的汇编文件是正确的汇编文件,因此汇编器不需要考虑源文件会产生错误,因此它的语法分析的目的是识别出输入语言的语法结构并进行解析引导机器代码生成。
另外,汇编器和编译器最大的不同是:汇编语言允许符号后置定义,因此通过一遍扫描无法保证获得某个符号的准确定义信息,所以对于汇编器必须采用两边扫描的方式进行设计,汇编器的设计结构如图1-2所示。
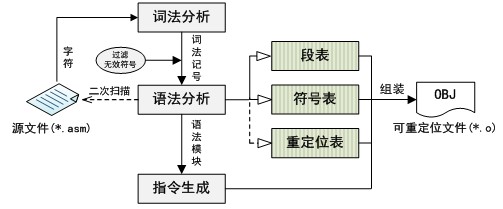
图1-2 汇编器结构
从图中可以看出汇编器的设计中,在语法分析模块之前和前述编译器的结构完全相同,只是语法分析时要进行两遍的扫描过程,通过第一遍扫描获取文件定义的所有的段的信息以及全部的符号信息,第二遍扫描根据最新的段表和符号表,将所有的重定位信息收集到重定位表中,然后通过指令生成模块生成了代码段数据。最后,从符号表中抽取有效数据定义形成数据段,符号导出到文件符号表段,再把所有的段按照elf文件的格式组装起来,形成最终的可重定位目标文件*.o。下面就按照上述路程具体说明汇编器设计的内容。
二、 文法定义
和编译器设计过程相同,首先必须明确处理汇编语言的文法定义,按照符合LL(1)文法的规则定义的待处理汇编语言的文法如表2-1所示:
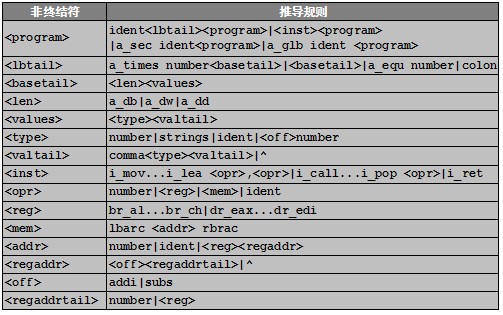
上述汇编文法可以识别之前编译器生成的所有代码,从文法定义中,可以看出汇编语言的功能主要如下:
(1)支持段声明,全局符号声明,数据定义db|dw|dd,times关键字和equ宏命令。
(2)支持数据为整数和字符串格式,允许定义中引用符号,数据使用逗号分隔。
(3)支持的指令数:双操作数指令5条,单操作数指令17条,无操作数指令1条。
(4)支持寻址模式:寄存器寻址,立即寻址,寄存器间址,间接寻址,基址+偏移寻址,基址+变址寻址。
明确汇编语言的文法后就可以构造分析程序识别语言的语法结构。
三、 词法分析
汇编器的词法分析过程和编译器相同,也需要扫描器和解析器,区别在于字母表和词法记号的差别。汇编语言的词法记号如表3-1所示。
表 3-1 词法记号
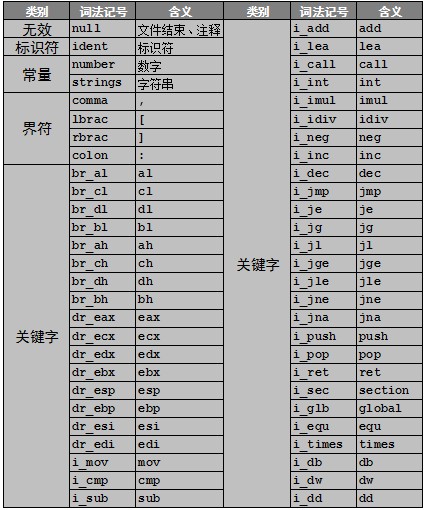
从词法记号表中可以看出汇编语言词法记号的变化:
(1)标识符可以用符号‘@’开头。
(2)增加一部分界符‘[’,‘]’,‘:’。
(3)删除了一部分界符‘*’,‘/’,‘=’,‘>’,‘<’,‘!’,‘;’,‘(’,‘)’,‘{’,‘}’。
(4)注释由分号引导的单行注释。
(5)关键字表有重大变化,所有的汇编助记符、寄存器、汇编器操作符都是关键字。
很明显,随着汇编语法结构的相对简化,词法记号的识别的复杂度也有所降低。另外由于由编译器生成的汇编语言文件是经过测试正确的,因此不需要进行异常处理。
四、 语法分析
语法分析是汇编器设计的核心,从图1-2就可以看出语法分析模块的重要地位。汇编器的语法分析模块不需要进行错误处理和修复的操作,但是必须正确识别并处理每一个关键的语法模块。汇编语言有两大类型的语法模块:数据和指令。数据语法模块要能识别所有类型的符号并存储到符号表,供指令模块和重定位表使用。指令语法模块要填充临时数据结构,供指令生成模块生成正确的操作码和操作数二进制信息。
简单的说,语法分析的目的是填充系统需要的三张表:段表、符号表、重定位表。通过第一遍扫描将输入文件的所有的段信息收集到段表中,所有的符号信息收集到符号表中,然后第二面扫描在产生重定位的地方生成重定位项,填充重定位表。这三张表是输出文件信息的核心,下边就按照这三张表的构造流程逐个说明。
4.1 段表
汇编语言使用section关键字声明段开始,直到下一个段声明或者文件结束位置结束,整个中间部分都属于section声明的段的内容。具体的说,由于编译器生成的汇编文件共有三个段:.text,.data,.bss。又因为我们使用两边扫描源文件的方式,因此,在第二遍扫描之前(第一遍.bss段结束后)汇编器就可以获得所有的段信息。参考链接器设计中elf文件Elf32_Shdr的数据结构可以看出段表项信息的最关键的信息是:段名、偏移、大小。段名在每次section声明时候记录下来即可,偏移计算之前必须知道上一个段的大小,因此段的大小计算是关键中的关键。为此汇编器使用一个全局变量curAddr记录了相对于当前段的起始偏移,每次汇编语言定义一个需要地址空间存储的语法模块,这个curAddr就会累加当前语法模块的大小,直到段声明结束时记录了整个段的大小。至于每个语法模块的大小如何计算,在后边符号表中再具体介绍。另外,由于.bss的特殊性,它的物理大小为0,但是虚拟大小需要计算。比如编译器只使用.bss存储了辅助栈供64k字节,因此虚拟大小为64k,但是占用磁盘空间大小为0。
另外还需要注意的是段的偏移并不是简单的累加段的大小计算,因为还涉及另一个概念——段对齐。这里和链接器类似,段的开始位置必须是一个数的整数倍(一般重定位目标文件是按照4字节对齐),因此在每次累加段偏移的时候需要考虑段对齐的影响。图4-1给出了一个构造段表项一个例子:
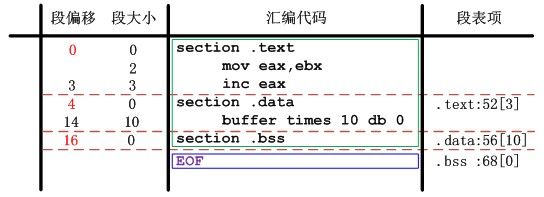
图4-1 段表构造实例
下面给出了段表项的相关代码:
{
if(scanLop==1)
{
dataLen+=(4-dataLen%4)%4;
obj.addShdr(curSeg,lb_record::curAddr);//新建一个段
if(curSeg!=".bss")
dataLen+=lb_record::curAddr;
}
curSeg="";curSeg+=id;//切换下一个段名
lb_record::curAddr=0;//清0段偏移
}
void Elf_file::addShdr(string sh_name,int size)
{
int off=52+dataLen;
if(sh_name==".text")
{
addShdr(sh_name,SHT_PROGBITS,SHF_ALLOC|SHF_EXECINSTR,0,off,size,0,0,4,0);
}
else if(sh_name==".data")
{
addShdr(sh_name,SHT_PROGBITS,SHF_ALLOC|SHF_WRITE,0,off,size,0,0,4,0);
}
else if(sh_name==".bss")
{
addShdr(sh_name,SHT_NOBITS,SHF_ALLOC|SHF_WRITE,0,off,size,0,0,4,0);
}
}
函数switchSeg在每次段声明的位置被调用,但是只是在第一次扫描时候生成段表项,每次调用后都会记录当前段名到curSeg,并清零curAddr。dataLen记录了当前的段偏移,添加段表项之前都会将之按照4字节对齐后在加上52(elf文件头大小)作为真正的段偏移添加到段表。另外,.bss段声明结束后是不累加段偏移的,这就反映了.bss无物理空间的含义。最后,addShdr按照段名分别生成具体的段表项,记录到段表。
4.2 符号表
符号表是所有表中最重要的,段表使用它计算自身大小,重定位需要它识别重定位符号,最终的数据段和符号表段还需要符号表进行导出。符号表相关的有三个最重要的数据结构:lb_record,Inst和Table。顾名思义,lb_record记录了当前分析出来的符号,Inst记录了当前分析出来的指令,Table是对所有符号的记录,即传统意义上的符号表,不过这里把Inst也作为符号表数据结构的一部分看待。下面首先给出这三种数据结构的定义:
首先说明符号数据结构:
{
static int curAddr;//一个段内符号的偏移累加量
string segName;//隶属于的段名,三种:.text .data .bss
string lbName;//符号名
bool isEqu;//是否是L equ 1
bool externed;//是否是外部符号,内容是1的时候表示为外部的,此时curAddr不累加
int addr;//符号段偏移
int times;//定义重复次数
int len;//符号类型长度:db-1 dw-2 dd-4
int *cont;//符号内容数组
int cont_len;//符号内容长度
lb_record(string n,bool ex);//L:或者创建外部符号(ex=true:L dd @e_esp)
lb_record(string n,int a);//L equ 1
lb_record(string n,int t,int l,int c[],int c_l);//L times 5 dw 1,"abc",L2 或者 L dd 23
void write();//输出符号内容
};
(1) curAddr:当前段偏移的静态变量。
(2) segName:符号隶属于的段名。
(3) lnName:符号名。
(4) isEqu:符号是否是equ定义的常量。
(5) externed:符号是否是外部符号。
(6) addr:符号的段偏移,若isEqu为true则表示符号的值。
(7) times:符号定义重复次数,不带times关键字默认为1,equ和外部符号为0。
(8) len:符号类型长度,db,dw,dd分别为1,2,4字节,无类型为0。
(9) cont:符号定义的内容,无内容为NULL。
(10) cont_len:符号定义内容长度,无内容为0。
(11) lb_record(string n,bool ex):形如L:或者符号引用L dd @e_esp。
(12) lb_record(string n,int a):形如L equ 1。
(13) lb_record(string n,int t,int l,int c[],int c_l):形如L times 5 dw 1或者 L dd 2。
(14) write():输出符号的二进制形式。
可以看出,构造符号记录有五种可能;
(1)形如L:这种标号形式,符号记录为本地局部符号,它代表一个32位地址,不占用任何存储空间。
(2)形如L equ 1这种标号形式,符号记录为本地局部符号,它代表一个32位立即数,不占用任何存储空间。
(3)形如L db 0这种标号形式,符号记录为全局符号,它对应了一串具体的数据,是数据段的组成部分,数据占用的空间大小为times*len*cont_len字节。
(4)形如L db 1这种标号形式,符号记录为全局符号的引用,是extern变量生成的代码,不占用存储空间。
(5)形如call fun这种标号形式,fun如果不存在本地,那么fun就是一个外部符号,它也不占用存储空间。
这些所有的符号都会记录在Table的中,含有实际数据的符号记录在defLbs列表中。
指令数据结构如下,Intel x86指令格式在指令生成时会具体介绍。
{
int mod;//0-1
int reg;//2-4
int rm;//5-7
};
struct SIB//sib字段
{
int scale;//0-1
int index;//2-4
int base;//5-7
};
struct Inst//指令的其他部分
{
unsigned char opcode;
int disp;
int imm32;
int dispLen;//偏移的长度
};
(1) ModRM:指令的modrm字段,若mod=-1说明不存在modrm字段。
(2) SIB:指令的sib字段,若scale=-1说明不存在SIB字段。
(3) Inst:指令中其余需要的字段集合。
(4) opcode:本意为了记录指令的操作码,但由于操作码的不具有统一性,因此此字段不再使用,输出操作码在指令生成的时候确定。
(5) disp:指令中偏移的大小,用于间接寻址和基址+偏移寻址。
(6) imm32:32位立即数,用于立即数寻址。
(7) dispLen:标识disp是8位还是32位。
指令长度的计算在后边指令生成部分会具体说明。
符号表数据结构定义如下:
{
public:
hash_map<string, lb_record*, string_hash> lb_map;//符号声明列表
vector<lb_re
以上是关于汇编器构造的主要内容,如果未能解决你的问题,请参考以下文章
Android 逆向使用 Python 解析 ELF 文件 ( Capstone 反汇编 ELF 文件中的机器码数据 | 创建反汇编解析器实例对象 | 设置汇编解析器显示细节 )(代码片段