短道速滑一OpenCV中cvResize函数使用双线性插值缩小图像到长宽大小一半时速度飞快(比最近邻还快)之异象解析和自我实现。
Posted 只(挚)爱图像处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了短道速滑一OpenCV中cvResize函数使用双线性插值缩小图像到长宽大小一半时速度飞快(比最近邻还快)之异象解析和自我实现。相关的知识,希望对你有一定的参考价值。
今天,一个朋友想使用我的SSE优化Demo里的双线性插值算法,他已经在项目里使用了OpenCV,因此,我就建议他直接使用OpenCV,朋友的程序非常注意效率和实时性(因为是处理视频),因此希望我能测试下我的速度和OpenCV相比到底那一个更有速度优势,恰好前一段时间也有朋友有这方面的需求,因此我就随意编写了一个测试程序,如下所示:
IplImage *T = cvLoadImage("F:\\\\1.JPG"); IplImage *SrcImg = cvCreateImage(cvSize(T->width, T->height), IPL_DEPTH_8U, 1); cvCvtColor(T, SrcImg, CV_BGR2GRAY); //IplImage *SrcImg = cvLoadImage("F:\\\\3.jpg"); cvNamedWindow("处理前", CV_WINDOW_AUTOSIZE); cvShowImage("处理前", SrcImg); IplImage *DestImg = cvCreateImage(cvSize(SrcImg->width / 2, SrcImg->height / 2), SrcImg->depth, SrcImg->nChannels); LARGE_INTEGER t1, t2, tc; QueryPerformanceFrequency(&tc); QueryPerformanceCounter(&t1); for(int i=0; i<100; i++) cvResize(SrcImg, DestImg, CV_INTER_CUBIC); QueryPerformanceCounter(&t2); printf("Use Time:%f\\n", (t2.QuadPart - t1.QuadPart) * 1000.0f / tc.QuadPart); cvNamedWindow("处理后", CV_WINDOW_AUTOSIZE); cvShowImage("处理后", DestImg); cvReleaseImage(&SrcImg); cvReleaseImage(&DestImg); cvReleaseImage(&T);
我使用了一张3000*2000的大图进行测试,令我非常诧异的是,执行100次这个函数耗时居然只有 Use Time:82.414300 ms,每一帧都不到1ms,目标图像的大小可是1500*1000的呢,立马打开我自己的Demo,同样的环境下测试,100次耗时达到了450ms,相差太多了,要知道,我那个可是SSE优化后的啊。有点不敢相信这个事实。
接着,我把CV_INTER_LINEAR(双线性)改为CV_INTER_NN(最近临),出来的结果是Use Time:78.921600 ms,注意到没有,时间比双线性的还要多,感觉这完全不合乎逻辑啊。
稍微冷静下来,我认为这绝对不符合真理,但是我心中已经隐隐约约知道大概为什么会出现这个情况,于是,我又做了下面几个测试。
第一、换一副图像看看,我把源图像的大小改为3001*2000,测试结果为:Use Time:543.837400 ms。
把源图像的大小改为3000*2001,测试结果为:Use Time:541.567800 ms。
把源图像的大小改为3001*2001,测试结果为:Use Time:547.325600 ms。
第二:源图像还是使用3000*2000大小,把DestImg的大小修改为1501*1000,测试结果为:Use Time:552.432800 ms。
把DestImg的大小修改为1500*1001,测试结果为:Use Time:549.956400 ms。
把DestImg的大小修改为1501*1001,测试结果为:Use Time:551.371200 ms。
这两个测试表明,这种情况只在:
一、源图像的宽度和高度均为2的倍数时;
二、目标图像的宽度和高度都必须为源图像的一半时;
时方有可能出现,那么他们是充分条件了吗?接着做试验。
第三:把插值方法改为其他的方式,比如CV_INTER_CUBIC(三次立方),若其他参数都不变,测试结果为:Use Time:921.885900 ms。
同样适使用三次立方,源图大小修改为3000*2001,测试结果为:Use Time:953.748100 ms。
适用三次立方,源图大小不变,目标图修改1501*1000,测试结果为:Use Time:913.735600 ms。
可见此时无论怎么调整输入输出,基本的耗时都差不多,换成CV_INTER_AREA或CV_INTER_NN也能得到同样的结果。
这第三个测试表明,此异常现象还只有在:
三:使用了双线性插值算法;
时才可能出现。这些条件就足够了吗?接着看。
第四:其他条件暂时不动,把测试代码修改如下:
IplImage *SrcImg = cvLoadImage("F:\\\\1.jpg"); cvNamedWindow("处理前", CV_WINDOW_AUTOSIZE); cvShowImage("处理前", SrcImg); IplImage *DestImg = cvCreateImage(cvSize(SrcImg->width / 2, SrcImg->height / 2), SrcImg->depth, SrcImg->nChannels); LARGE_INTEGER t1, t2, tc; QueryPerformanceFrequency(&tc); QueryPerformanceCounter(&t1); for(int i=0; i<100; i++) cvResize(SrcImg, DestImg, CV_INTER_CUBIC); QueryPerformanceCounter(&t2); printf("Use Time:%f\\n", (t2.QuadPart - t1.QuadPart) * 1000.0f / tc.QuadPart); cvNamedWindow("处理后", CV_WINDOW_AUTOSIZE); cvShowImage("处理后", DestImg); cvReleaseImage(&SrcImg); cvReleaseImage(&DestImg);
即使用彩色图像进行测试,运行的结果为:Use Time:271.705700 ms。看这个的时间和灰度的82ms相比,一猜就知道还是做了特别的处理。
但是我们还是多做几个测试,我们将输出图像的大小修改为1501*1000、1500*1001、1501*1001时,100次的耗时在1367ms,如果输入图像修改为长或宽为非偶数时,耗时也差不多要1300多ms,说明OpenCV对彩色图像的这种情况也有做优化处理。
因此,这个算法对彩色也是有效的。
以上三个条件在一起构成了出现上述异常现象的充分必要条件。下面根据我个人的想法来谈谈OpenCV为什么会出现这个现象(我没有去翻OpenCV的代码)。
个人认为,出现该现象核心还是由双线性插值算法的本质引起的。双线性插值算法在插值时涉及到周边四个像素,当源图像宽度和高度都为2的倍数,如果此时的目标图像的长度和高度又恰好是源图像宽度和高度的一半,这个时候的双线性插值就退化为对原图像行列方向每隔一个像素求平均值(四个像素)的过程。如果不是双线性插值,他涉及到领域范围就不是4个,比如三次立方就涉及到16个领域,而非2的倍数或非一半的大小则无法规整到0.25的权重(4个像素的平均值)。
对于这个特例,我们用C语言可以简单的写出其计算过程:
int IM_ZoomIn_Half_Bilinear(unsigned char *Src, unsigned char *Dest, int SrcW, int SrcH, int StrideS, int DstW, int DstH, int StrideD) { int Channel = StrideS / SrcW; if ((Src == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((SrcW <= 0) || (SrcH <= 0) || (DstW <= 0) || (DstH <= 0)) return IM_STATUS_INVALIDPARAMETER; if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_INVALIDPARAMETER; if ((SrcW % 2 != 0) || (SrcH % 2 != 0)) return IM_STATUS_INVALIDPARAMETER; if ((DstW != SrcW / 2) || (DstH != SrcH / 2)) return IM_STATUS_INVALIDPARAMETER; if (Channel == 1) { for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; for (int X = 0; X < DstW; X++, LineP1 += 2, LineP2 += 2) { LinePD[X] = (LineP1[0] + LineP1[1] + LineP2[0] + LineP2[1] + 2) >> 2; } } } else if (Channel == 3) { for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; for (int X = 0; X < DstW; X++) { LinePD[0] = (LineP1[0] + LineP1[3] + LineP2[0] + LineP2[3] + 2) >> 2; LinePD[1] = (LineP1[1] + LineP1[4] + LineP2[1] + LineP2[4] + 2) >> 2; LinePD[2] = (LineP1[2] + LineP1[5] + LineP2[2] + LineP2[5] + 2) >> 2; LineP1 += 6; LineP2 += 6; LinePD += 3; } } } }
代码非常简单,注意到计算式里最后的+2是为了进行四舍五入。
我们先测试下灰度图,使用上述代码在同样的环境下可以获得: Use Time:225.456300 ms 的成绩,使用循环内2路或4路并行的方式大约能将成绩提高到190ms左右,但是和OpenCV的速度相比还是有蛮大的差距。这么简答的代码,我们可以直接用SIMD指令进行优化:
我们先使用SSE进行尝试:
__m128i Zero = _mm_setzero_si128(); for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; for (int X = 0; X < Block * BlockSize; X += BlockSize, LineP1 += BlockSize * 2, LineP2 += BlockSize * 2) { __m128i Src1 = _mm_loadu_si128((__m128i *)LineP1); __m128i Src2 = _mm_loadu_si128((__m128i *)LineP2); // A0+B0 A1+B1 A2+B2 A3+B3 A4+B4 A5+B5 A6+B6 A7+B7 __m128i Sum_L = _mm_add_epi16(_mm_cvtepu8_epi16(Src1), _mm_cvtepu8_epi16(Src2)); // A8+B8 A9+B9 A10+B10 A11+B11 A12+B12 A13+B13 A14+B14 A15+1B15 __m128i Sum_H = _mm_add_epi16(_mm_unpackhi_epi8(Src1, Zero), _mm_unpackhi_epi8(Src2, Zero)); // A0+A1+B0+B1 A2+A3+B2+B3 A4+A5+B4+B5 A6+A7+B6+B7 A8+A9+B8+B9 A10+A11+B10+B11 A12+A13+B12+B13 A14+A15+B14+1B15 __m128i Sum = _mm_hadd_epi16(Sum_L, Sum_H); // (A0+A1+B0+B1+2)/4 (A2+A3+B2+B3)/4 (A4+A5+B4+B5)/4 (A6+A7+B6+B7)/4 (A8+A9+B8+B9)/4 (A10+A11+B10+B11)/4 (A12+A13+B12+B13)/4 (A14+A15+B14+1B15)/4 __m128i Result = _mm_srli_epi16(_mm_add_epi16(Sum, _mm_set1_epi16(2)), 2); _mm_storel_epi64((__m128i *)(LinePD + X), _mm_packus_epi16(Result, Zero)); } for (int X = Block * BlockSize; X < DstW; X++, LineP1 += 2, LineP2 += 2) { LinePD[X] = (LineP1[0] + LineP1[1] + LineP2[0] + LineP2[1] + 2) >> 2; } }
对SSE优化来说,也没啥,加载数据,将其转换成16位(字节相加肯定会溢出,到16位后4个数相加肯定会在16位的范围内),注意上面的最为精华的部分为_mm_hadd_epi16的使用,他的水平累加过程恰好可以完成最后的列方向的处理,如果我们先用这个函数完成A0+A1这样的工作,那如果要完成同样的工作,后续就要多了一些shuffle过程了,这样就降低了速度。
这段SIMD指令经过测试,100次循环耗时在90-100ms之间徘徊,和OpenCV的结果有点差不多了。
如果我们使用AVX指令进行优化,整体基本和SSE差不多,但是局部细节上还是有所差异的,如下所示:
for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; __m256i Zero = _mm256_setzero_si256(); for (int X = 0; X < Block * BlockSize; X += BlockSize, LineP1 += BlockSize * 2, LineP2 += BlockSize * 2) { __m256i Src1 = _mm256_loadu_si256((__m256i *)LineP1); __m256i Src2 = _mm256_loadu_si256((__m256i *)LineP2); // 注意这里使用unpack的方式来实现8位和16位的转换,如果使用_mm256_cvtepu8_epi16则低位部分需要一个__m128i变量,而 // 高位使用_mm256_unpackhi_epi8则需要一个__m256i变量,这样会存在重复加载现象的。 __m256i Sum_L = _mm256_add_epi16(_mm256_unpacklo_epi8(Src1, Zero), _mm256_unpacklo_epi8(Src2, Zero)); __m256i Sum_H = _mm256_add_epi16(_mm256_unpackhi_epi8(Src1, Zero), _mm256_unpackhi_epi8(Src2, Zero)); __m256i Sum = _mm256_hadd_epi16(Sum_L, Sum_H); __m256i Result = _mm256_srli_epi16(_mm256_add_epi16(Sum, _mm256_set1_epi16(2)), 2); // 注意_mm256_packus_epi16 并不是_mm_packus_epi16的线性扩展,很恶心的做法 _mm_storeu_si128((__m128i *)(LinePD + X), _mm256_castsi256_si128(_mm256_permute4x64_epi64(_mm256_packus_epi16(Result, Zero), _MM_SHUFFLE(3, 1, 2, 0)))); } for (int X = Block * BlockSize; X < DstW; X++,LineP1 += 2, LineP2 += 2) { LinePD[X] = (LineP1[0] + LineP1[1] + LineP2[0] + LineP2[1] + 2) >> 2; } }
特别注意到的是最后_mm256_packus_epi16指令的使用,他和_mm256_add_epi16或者 _mm256_srli_epi16不一样,并不是对SSE指令简单的从128位扩展到256位,我们从其简单的数学解释就可以看到:
_mm_add_epi16 _mm256_add_epi16


add指令就是直接从8次一次性计算简单的扩展到16次一次性计算,在来看packus指令:
_mm_packus_epi16 _mm256_packus_epi16

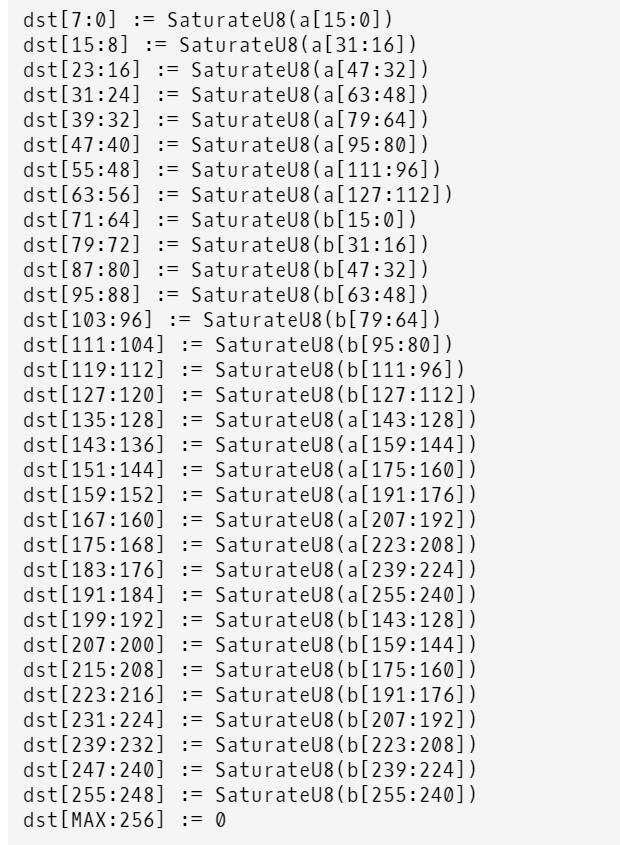
_mm256_packus_epi16 实际上可以看成是对两个__m128i变量单独进行处理,而不是把他们看成一个整体,这样同样的算法,我们就在AVX中就不能使用同样SSE指令了,比如最后的保存的语句,我们必须使用一个_mm256_permute4x64_epi64指令来进行一下shuffle调序操作。
这种不便利性也是我不愿意将大部分SSE指令扩展到AVX的一个重要障碍之一。
使用AVX编写的程序优化后的耗时大约在80ms左右波动,这个已经非常接近OpenCV的速度了,至此,我们有理由相信OpenCV在实现这个的过程中应该也采取了类似我上述的优化方式进行处理(没有仔细的翻OpenCV的代码,请有看过的朋友指导下)。
那么我们再谈谈为什么这个速度比最近邻插值还要快吧,最近邻算法中,不存在插值,直接在源图像中选择一个坐标位置的点作为新的像素值,在放大时其会出现多行像素相同的特性,这个特性可以用来加快算法执行速度,但是对于缩小,只有一个点一个点的计算,至多可以用查找表提前计算好坐标,经过尝试,这算法是不易用多媒体指令进行优化的,而且即使用,也无明显的速度提升。而对于本文的双线性的特例,其并行的特性非常好,而且本身的计算量也不是很大,因此,就出现用SIMD优化后速度还比最近邻还快的结果。
对于彩色图像,普通的C语言代码也很简单,上面也已经贴出代码,这段代码执行100次大概耗时在500ms左右,注意这个时候对他进行SIMD指令优化就不是一件很直接和很简单的事情了,因为BGRBGR这样的排列顺序到底无法直接使用灰度模式的指令扩展,必须要将BGR重新排序,变为BBB GGG RRR这样的模式,然后单独对分量进行处理,处理完成后再合成为BGR排列,因此,这样排列需要一次性加载48个字节(SSE),用3个SSE寄存器保存数据,这个时候如果使用AVX指令就显得有点繁琐了,而且就是用AVX带来的性能收益也微乎其微。 同样的,这种计算量不大的算法,用SIMD指令优化后的收益并不是特别明显,对于彩色图像,SSE优化后其时间大概能缩短到300ms,这个速度要比OpenCV的稍微慢一点。
随着现在的视频显示设备越来越先进,采集的图像也越来越大,比如现在4K的高清摄像头也不在少数,在有些实时要求性很好的场合,我们必须考虑处理能力,将图像缩小在处理是常用的手段,而且,我想长宽各一半的这种缩小场合在此情况下也应该是很常见的,因此,特列的特别优化就显得非常有意义。
还有,一般情况下图像多次缩小2倍要比直接缩小大于2倍的效果更好,或者说通过多次缩放得到的结果一般要比直接一次性缩放得到的结果要更好,比如,下面左图是直接缩放到原图1/4长宽的结果,右图是先缩小一半,在缩小一半的结果,在风车的边缘可以看到后者更为平滑。


在耗时上,比如上面这个操作,直接缩小到1/4因不是特殊处理,而通过2次一半的处理每次都是特殊算法,虽然次数多了,但是总耗时也就比直接缩小1/4多了0.5倍,效果却要好一点,对于那些重效果的地方,还是非常有意义的,特别是如果是处理4K的图,这种处理也有很好的借鉴意义。
最后说一下,进一步测试表面我自行优化的缩放算法和OpenCV的相比灰度图上基本差不多,彩色图像大概要快20%左右。
本文Demo下载地址: http://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar,位于Edit-Resample菜单下,里面的所有算法都是基于SSE实现的。

以上是关于短道速滑一OpenCV中cvResize函数使用双线性插值缩小图像到长宽大小一半时速度飞快(比最近邻还快)之异象解析和自我实现。的主要内容,如果未能解决你的问题,请参考以下文章
OpenCV中使用cvResize函数或resize函数进行图象放缩