获取某个平台(例如微博知乎微信百度等)的热点前十名的标题信息以及热度数据
Posted 黄含斌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了获取某个平台(例如微博知乎微信百度等)的热点前十名的标题信息以及热度数据相关的知识,希望对你有一定的参考价值。
#页面结构
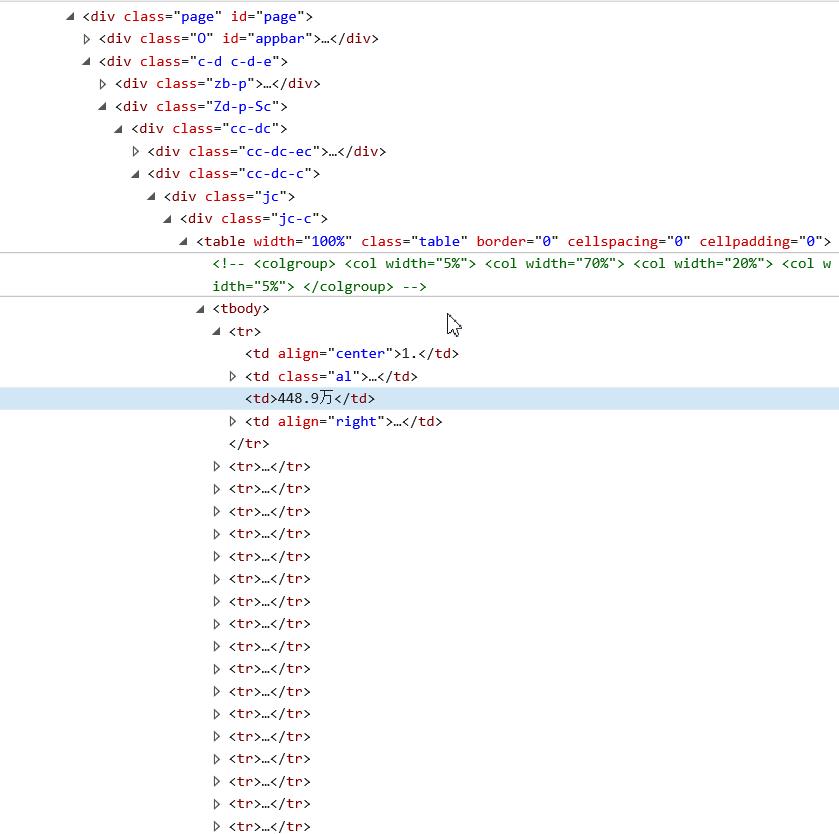
#源代码
import requests from bs4 import BeautifulSoup import bs4 def gethtmlText(url): try: headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"} r = requests.get(url, timeout=30, headers=headers) r.raise_for_status() # 产生异常信息 r.encoding = r.apparent_encoding # 修改编码 return r.text # 返回网页信息 except: return "" # 提取html信息中关键的数据,并提取到列表中 def fillList(ulist, html): soup = BeautifulSoup(html, "html.parser") # 所有新闻信息被封装在表格中,这个表格标签叫tbody # 在tbody中,每个新闻信息又被封装在tr中,每个tr标签,包含所有当前新闻的所有信息 # 每个tr中信息,又被td所包围 # 1. 遍历tbody,tr即每个新闻的信息 for tr in soup.find(\'tbody\').children: # 过滤非标签类型的其他数据 if isinstance(tr, bs4.element.Tag): tds = tr(\'td\') # 查询tr中的 td ulist.append([tds[1].string, tds[2].string]) def printList(ulist, num): print("{:^6}\\t{:^10}".format("标题", "热度")) for i in range(num): u = ulist[i] print("{:^6}\\t{:^10}".format(u[0], u[1])) def main(): # 新闻信息放到列表中 uinfo = [] # 百度新闻的url url = "https://tophub.today/n/Jb0vmloB1G" # 将url转换成html html = getHTMLText(url) fillList(uinfo, html) printList(uinfo, 10) # 10 news if __name__ == \'__main__\': main()
#获取数据截图

以上是关于获取某个平台(例如微博知乎微信百度等)的热点前十名的标题信息以及热度数据的主要内容,如果未能解决你的问题,请参考以下文章
23个Python爬虫开源项目代码:爬取微信淘宝豆瓣知乎微博等
前端周报:印度政府已要求应用商店下架百度和微博;微信回应特朗普封禁:正在评估;安卓版 Chrome 会发通知提醒你使用它