编写一个网易云音乐爬虫程序
Posted 我是冰霜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编写一个网易云音乐爬虫程序相关的知识,希望对你有一定的参考价值。
本次借助wxPython编写一个网易云音乐的爬虫程序,能够根据一个歌单链接下载其下的所有音乐
前置说明
网易云音乐提供了一个下载接口:http://music.163.com/song/media/outer/url?id=xxx
所以只需要拿到歌单中每首歌曲对应的 id 即可
1.分析歌单网页元素
打开网易云音乐,复制一个歌单链接
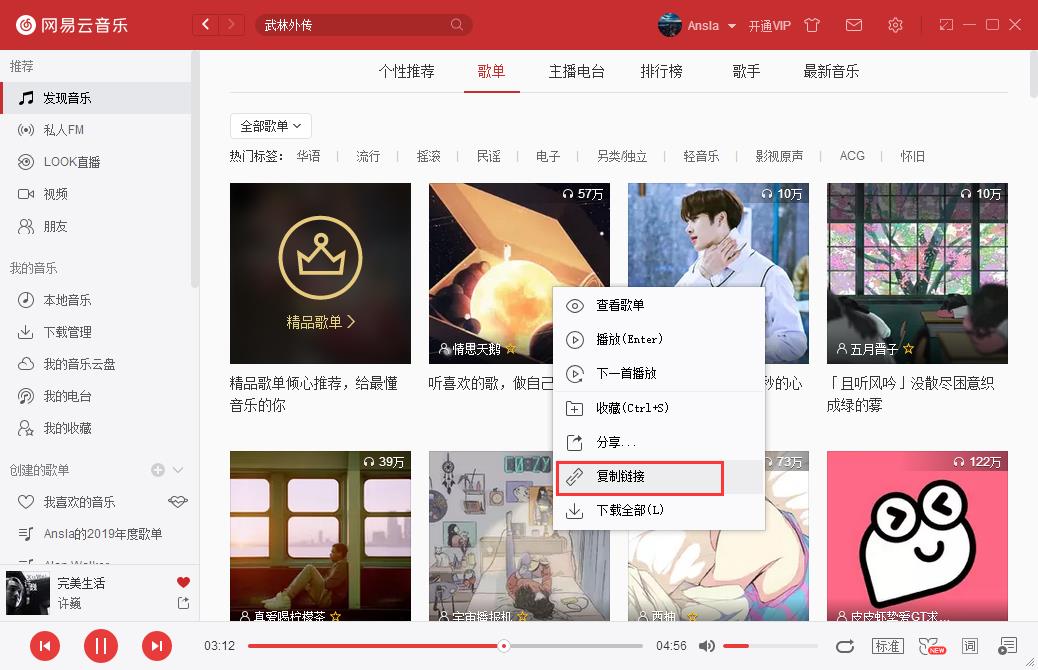
打开chrome,查看网页元素
这里有个细节,我们拿到的歌单url中有一个符号“/#”,因为之前爬虫其他网站时,也是直接请求初始url,一般Elements标签中的内容就是response返回的内容,所以刚开始我一直在请求这个url,但是发现这次返回的内容总是不对,响应内容和页面元素不一致;
后来切换到Network标签下的Doc菜单查看具体发送了哪些请求,如下图标记所示,实际有效请求的url中没有 "/#" 这个符号,所以后面在定义初始url时,需要把这部分字符串替换掉
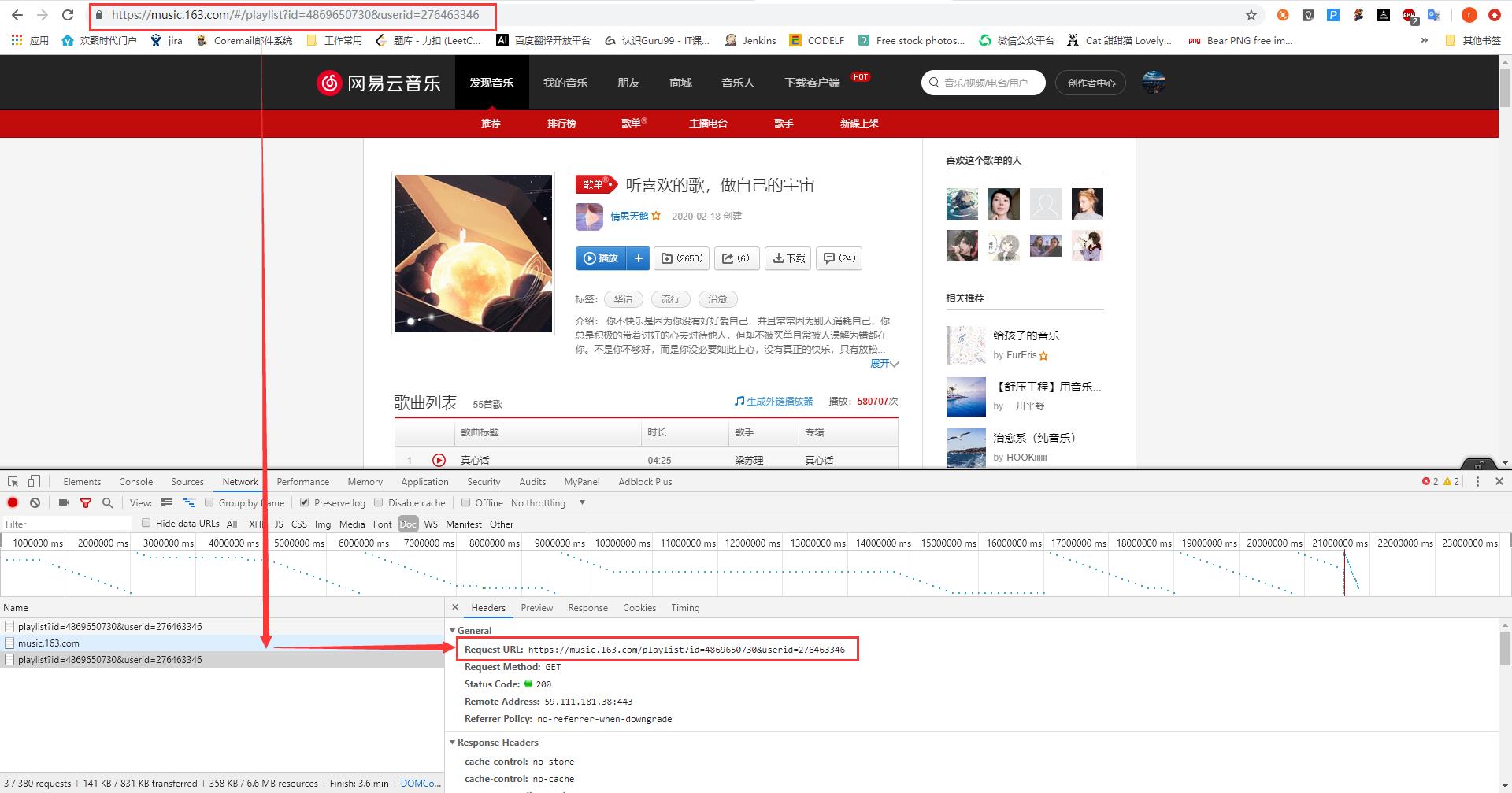
要提取的元素如下
(1)提取歌曲名称 (2)提起歌曲对应的id(下载歌曲时需要使用)

2.解析响应内容
获取到歌单页面的响应内容后,下一步就是提取出想要的内容,方法有很多种,如BeautifulSoup、XPATH、pyquery、正则表达式
这次使用正则表达式提取,这里我提取了歌单名称、歌曲id、歌曲名称,如下
1 def parse_html(self, request_url): 2 """解析歌单页面,提取元素""" 3 global headers 4 html_text = self.get_html_text(url=request_url, header=headers, method="get") # 调用get_html_text()方法,获取歌单页面响应内容 5 # print(html_text) 6 7 ###########使用正则表达式提取歌单名称、歌曲名称以及歌曲id############ 8 try: 9 title = re.search(r\'<title>(.*?) -.*?</title>\', html_text).group(1) # 匹配歌单名称 10 # print(title) 11 12 13 pattern_1 = re.compile(r\'<li><a.*?id=(\\d+)">\' # 匹配歌曲id 14 r\'(.*?)</a>\', re.S) # 匹配歌曲名称 15 musics = pattern_1.findall(html_text) # 查找所有结果,每组数据以一个元组形式,组成一个列表格式返回 16 # print(musics) 17 music_list = { 18 "title": title, 19 "music_list": musics 20 } 21 return music_list 22 except Exception as e: 23 print("请求歌单UR了出错,检查url是否正确,报错信息为:", e)
3. 构造程序界面
因为这次要做一个界面程序,实现如下要求
- 能够自定义选择保存路径
- 在界面输入歌单url后,可以直接爬取其下歌曲
- 下载过程能够展示在界面中
以前写的几个界面工具都是用的python自带的tkinter,这次试着用一下wxPython,看下效果如何
(1)确保自己的电脑中安装了wxPython,这一步略过,贴几个学习网站
痞子衡嵌入式:极易上手的可视化wxPython GUI构建工具(wxFormBuilder) - 痞子衡 - 博客园
(2)下载安装wxFormBuilder
这是一个可视化的GUI布局工具,并且可以生成对应的python代码
当然也可以通过一个一个的敲代码把界面布局搞好,但是如果元件过多的话,这种方式还是比较麻烦,相对来说还是觉界面拖拽布局比较直观
(3)界面布局
先来看下最终的效果
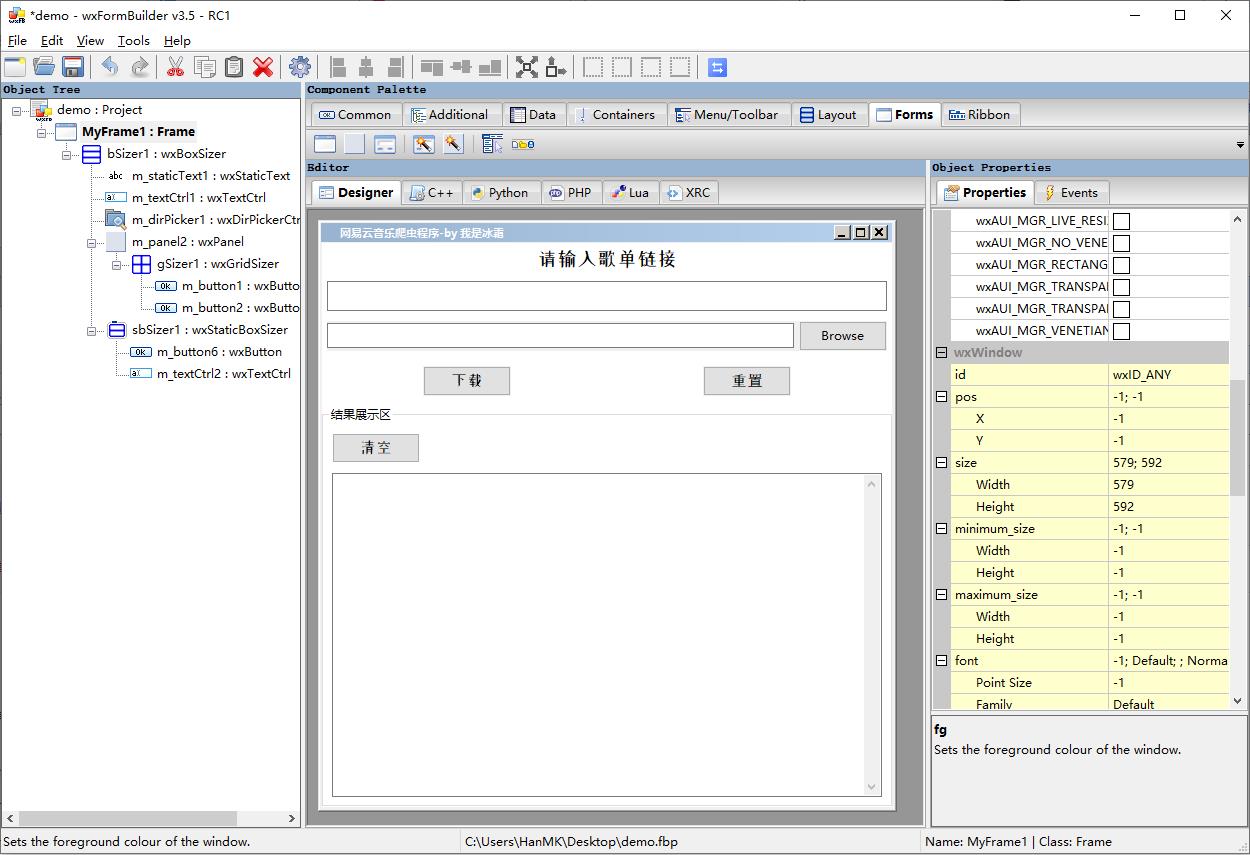
第一步
打开wxFormBuilder,新建一个project,切换到Forms标签,新建一个Frame

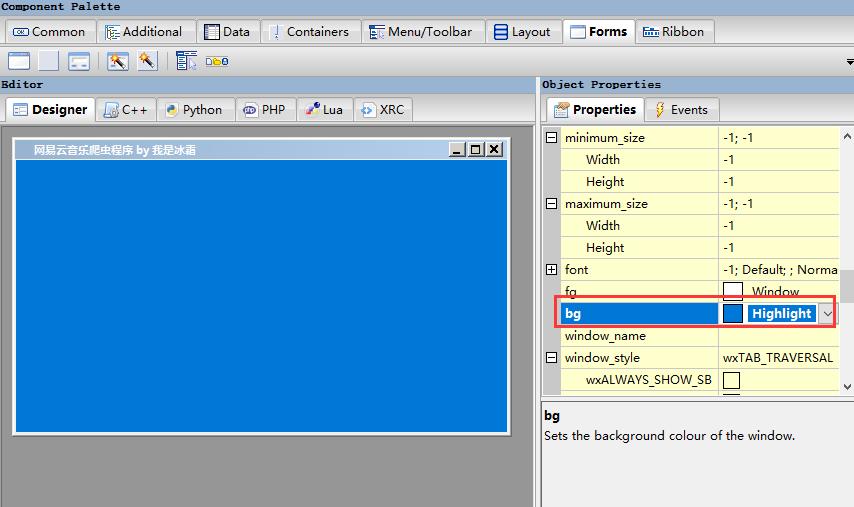
Frame是这个界面的主界面,可以在右侧属性栏修改一些属性,如大小、背景色
title表示工具栏显示的名称
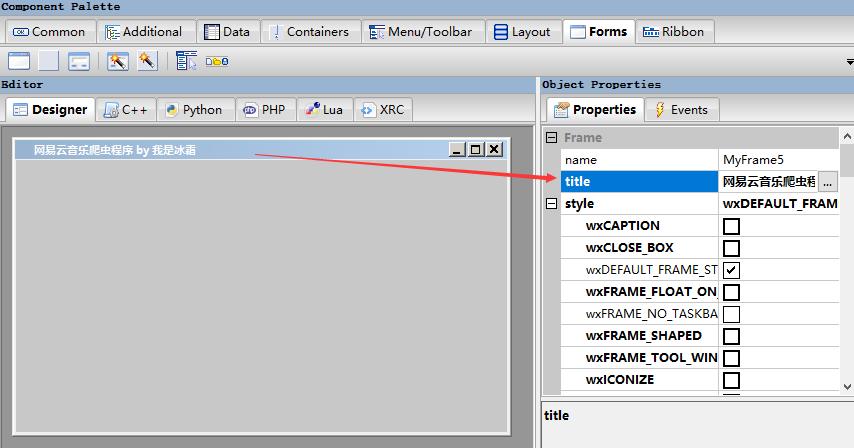
下划至wxWindow有一个bg属性,可以改变背景色,其他诸如窗口大小等也是在wxWindow下的size属性修改,可以自行探索
第二步
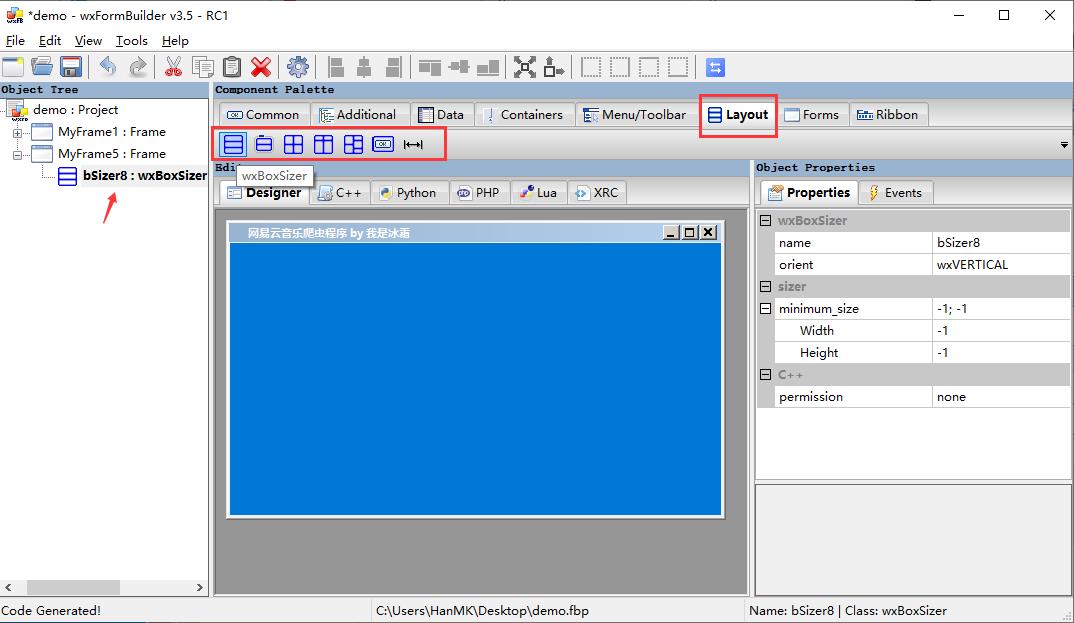
有了Frame后,还需要添加Layout,它的意思是规定了按钮、输入框、文本框等这些元件如何在界面中布局,给它们划定了位置,没有添加Layout的话,是不能添加那些元件的
常用的有wxBoxSizer、wxStaticBoxSizer、wxGridBoxSizer、wxFlexGridBoxSizer等,可以通过组合这些不同的布局方式形成多样化的展示页面(我也是边做边摸索,刚开始学弄的不太美观,别介意.....)
第三步
开始添加控件,如静态文本展示框、文本框、按钮、路径选择控件
切换到Common标签,可以在这里面添加文本框和按钮
(1)按钮一般需要绑定事件,点击触发对应的操作,可以先在右侧Events菜单定义事件名称(也就是函数名),后面在写功能代码时补充即可
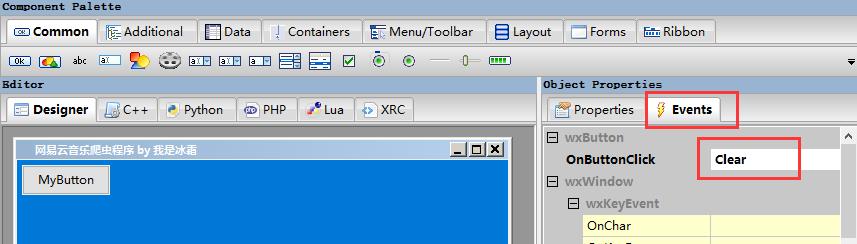
(2)静态文本wxStaticText,我一般用来展示一些说明性的文字
这里有一点很厉害,可以给文本设置字体,如果你的电脑字库中安装了某些字体,可以直接选择展示(注意的是如果把程序拷贝到其他电脑,如果没有对应字体的话,会看不到效果的)
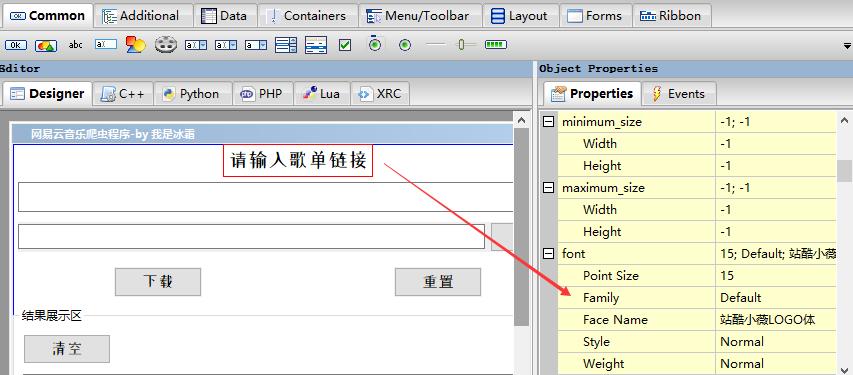
(3)文本框wxTextCtrl,用来设置输入框、输出框
例如可以设置一个文本框来接收输入的歌单url,或者用来把代码运行日志展示在文本框 ,同样的,它也可以设置文本框展示文字的字体和大小;
另外如果当做输出框展示的话,一般会把文本框设置的大一些,同时,希望能够随着文本增加自动往下滚动(就是滚动条)
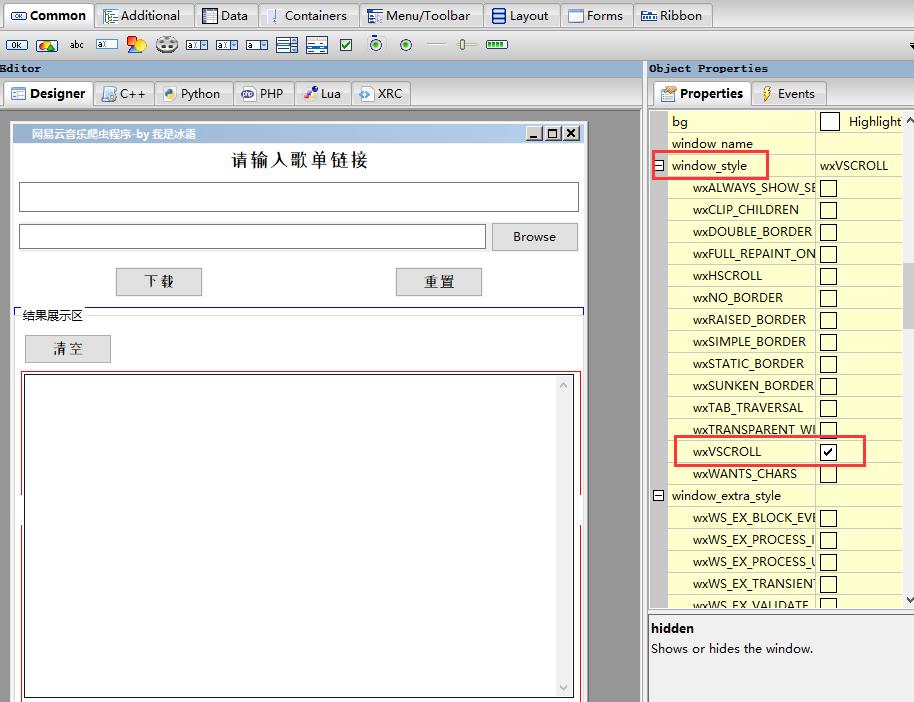
勾选右侧属性栏-window_style中的wxVSCROLL,可以添加垂直方向滚动条;勾选wxHSCROLL可以添加横向滚动条
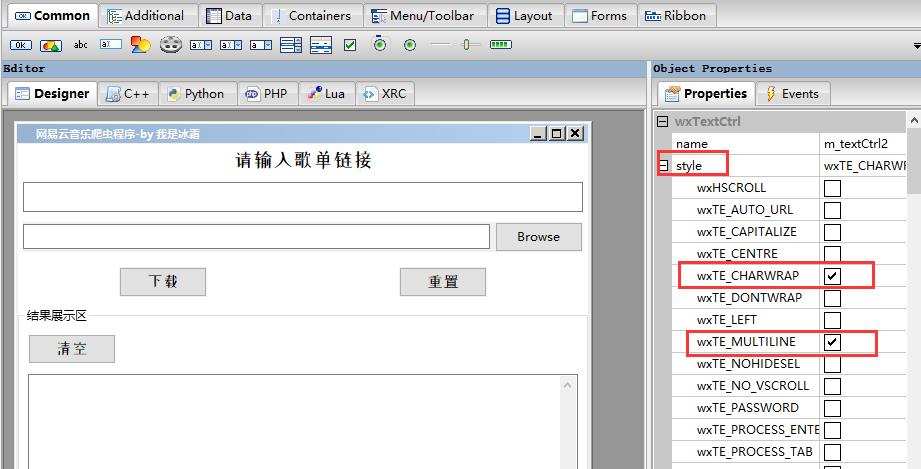
另外如果想换行展示文本,可以通过style中的 wxTE_CHARWRAP和wxTE_MULTILINE来实现,它可以识别输出文本中的换行符,实现换行效果
(4)下拉菜单wxComboBox,它可以实现下拉菜单的功能,自定义几个选项
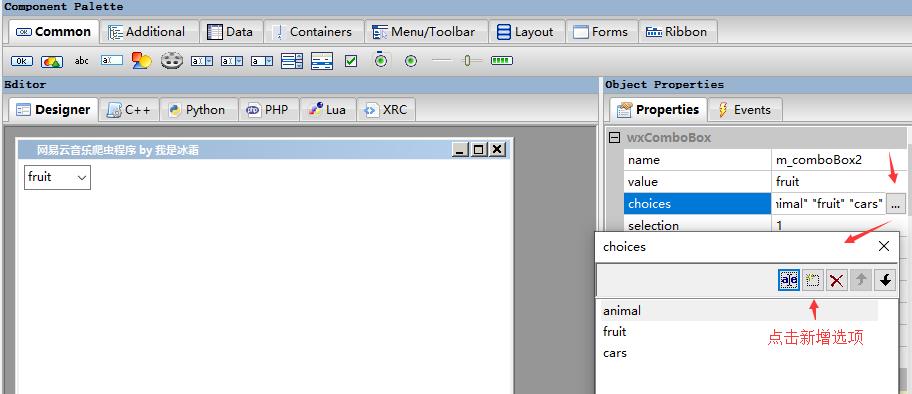
(5)路径选择框,wxpython也提供了路径选择控件,可以直接使用
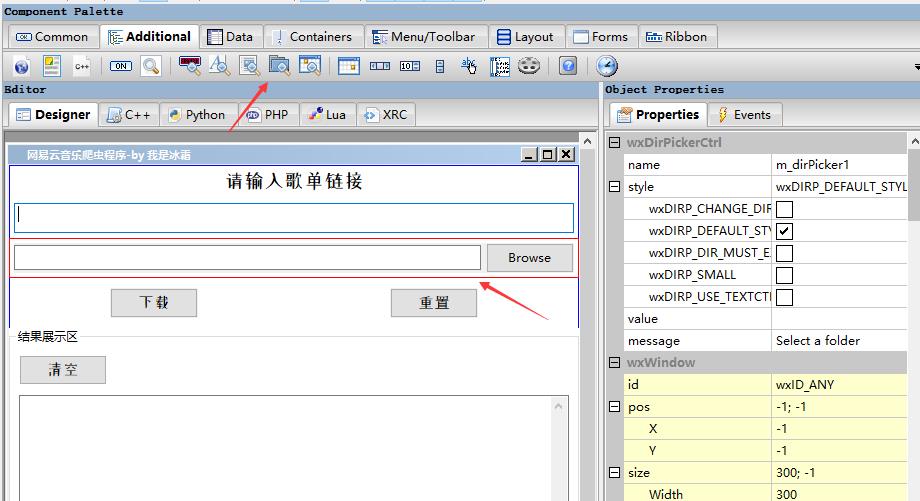
4. 将界面布局代码拷贝到python中
在进行页面布局的过程中,会实时在Bditor中的python下生成对应的python代码
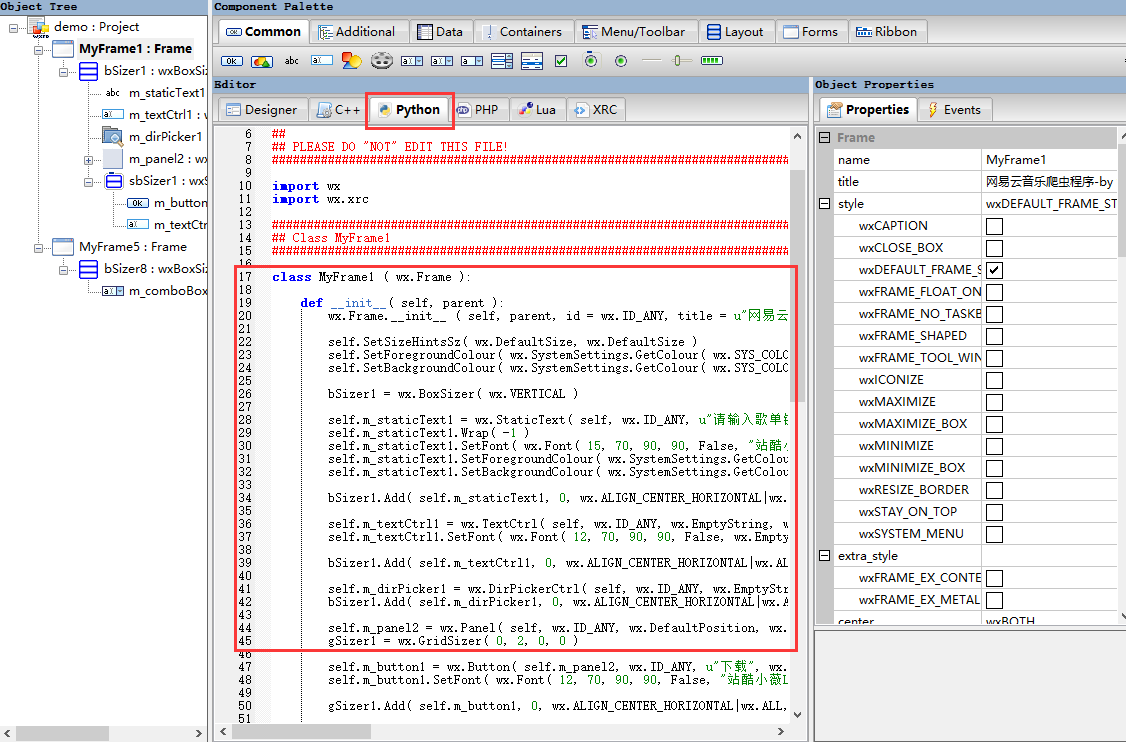
接下来需要做2件事情
(1)打开pycharm新建一个py文件,比如新建一个Net_Music_GUI.py,然后把wxFormBuilder生成的代码拷贝这个文件中
这样做的目的是保持页面布局代码的独立性,方便后续调整页面布局
(2)再次新建一个py文件,比如新建一个download_music.py,这个文件是最终执行的文件,在这里面新建一个类并继承Net_Music_GUI.py中的MyFrame1类
这样的话就可以使用页面布局了
5.完善download_music.py
这里说的完善,一是要继承之前的创建好的页面布局代码,二是柔和爬虫功能代码,三是补充之前定义的按钮绑定事件
之前定义了3个按钮,下面是对应的事件回调代码
1 def download(self, event): 2 """定义下载按钮回调方法""" 3 url =self.m_textCtrl1.GetValue().replace("/#", "") # 拿到url输入框的值,并去掉url中的/#符号 4 5 if url: 6 print(url) 7 self.download_music(url) 8 else: 9 self.m_textCtrl1.SetValue("请输入url") 10 11 def reset(self, event): 12 """定义清空url输入框内容方法""" 13 self.m_textCtrl1.Clear() 14 15 def clear(self, event): 16 """定义清空日志输出框的方法""" 17 self.m_textCtrl2.Clear()
还有一点需要说一下,因为是自定义保存路径,所以需要拿到界面工具自选的路径
wxDirPickerCtrl有一个方法 GetPath(),可以获取当前显示的路径值
root_dir = self.m_dirPicker1.GetPath() # 获取GUI界面自定义选择的路径
贴一下完整代码
Net_Music_GUI.py


1 # -*- coding: utf-8 -*- 2 3 ########################################################################### 4 ## Python code generated with wxFormBuilder (version Jun 17 2015) 5 ## http://www.wxformbuilder.org/ 6 ## 7 ## PLEASE DO "NOT" EDIT THIS FILE! 8 ########################################################################### 9 10 import wx 11 import wx.xrc 12 13 14 ########################################################################### 15 ## Class MyFrame1 16 ########################################################################### 17 18 class MyFrame1(wx.Frame): 19 def __init__(self, parent): 20 wx.Frame.__init__(self, parent, id=wx.ID_ANY, title=u"网易云音乐爬虫程序-by 我是冰霜", pos=wx.DefaultPosition, 21 size=wx.Size(579, 592), style=wx.DEFAULT_FRAME_STYLE | wx.TAB_TRAVERSAL) 22 23 self.SetSizeHints(wx.DefaultSize, wx.DefaultSize) 24 self.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_BTNTEXT)) 25 self.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_WINDOW)) 26 27 bSizer1 = wx.BoxSizer(wx.VERTICAL) 28 29 self.m_staticText1 = wx.StaticText(self, wx.ID_ANY, u"请输入歌单链接", wx.DefaultPosition, wx.DefaultSize, 0) 30 self.m_staticText1.Wrap(-1) 31 self.m_staticText1.SetFont(wx.Font(15, 70, 90, 90, False, "站酷小薇LOGO体")) 32 self.m_staticText1.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_BTNTEXT)) 33 self.m_staticText1.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_WINDOW)) 34 35 bSizer1.Add(self.m_staticText1, 0, wx.ALIGN_CENTER_HORIZONTAL | wx.ALL, 5) 36 37 self.m_textCtrl1 = wx.TextCtrl(self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.Size(500, 30), 0) 38 self.m_textCtrl1.SetFont(wx.Font(12, 70, 90, 90, False, wx.EmptyString)) 39 40 bSizer1.Add(self.m_textCtrl1, 0, wx.ALIGN_CENTER_HORIZONTAL | wx.ALL | wx.EXPAND, 5) 41 42 self.m_dirPicker1 = wx.DirPickerCtrl(self, wx.ID_ANY, wx.EmptyString, u"Select a folder", wx.DefaultPosition, 43 wx.Size(300, -1), wx.DIRP_DEFAULT_STYLE) 44 bSizer1.Add(self.m_dirPicker1, 0, wx.ALIGN_CENTER_HORIZONTAL | wx.ALL | wx.EXPAND, 5) 45 46 self.m_panel2 = wx.Panel(self, wx.ID_ANY, wx.DefaultPosition, wx.DefaultSize, wx.TAB_TRAVERSAL) 47 gSizer1 = wx.GridSizer(0, 2, 0, 0) 48 49 self.m_button1 = wx.Button(self.m_panel2, wx.ID_ANY, u"下载", wx.DefaultPosition, wx.DefaultSize, 0) 50 self.m_button1.SetFont(wx.Font(12, 70, 90, 90, False, "站酷小薇LOGO体")) 51 52 gSizer1.Add(self.m_button1, 0, wx.ALIGN_CENTER_HORIZONTAL | wx.ALL, 5) 53 54 self.m_button2 = wx.Button(self.m_panel2, wx.ID_ANY, u"重置", wx.DefaultPosition, wx.DefaultSize, 0) 55 self.m_button2.SetFont(wx.Font(12, 70, 90, 90, False, "站酷小薇LOGO体")) 56 57 gSizer1.Add(self.m_button2, 0, wx.ALIGN_CENTER_HORIZONTAL | wx.ALL, 5) 58 59 self.m_panel2.SetSizer(gSizer1) 60 self.m_panel2.Layout() 61 gSizer1.Fit(self.m_panel2) 62 bSizer1.Add(self.m_panel2, 1, wx.ALL | wx.EXPAND, 5) 63 64 sbSizer1 = wx.StaticBoxSizer(wx.StaticBox(self, wx.ID_ANY, u"结果展示区"), wx.VERTICAL) 65 66 self.m_button6 = wx.Button(sbSizer1.GetStaticBox(), wx.ID_ANY, u"清空", wx.DefaultPosition, wx.DefaultSize, 0) 67 self.m_button6.SetFont(wx.Font(12, 70, 90, 90, False, "站酷小薇LOGO体")) 68 69 sbSizer1.Add(self.m_button6, 0, wx.ALL, 5) 70 71 self.m_textCtrl2 = wx.TextCtrl(sbSizer1.GetStaticBox(), wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, 72 wx.Size(500, 600), wx.TE_CHARWRAP | wx.TE_MULTILINE | wx.VSCROLL) 73 self.m_textCtrl2.SetFont(wx.Font(12, 70, 90, 90, False, "杨任东竹石体-Regular")) 74 self.m_textCtrl2.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_HIGHLIGHTTEXT)) 75 76 sbSizer1.Add(self.m_textCtrl2, 0, wx.ALIGN_CENTER_HORIZONTAL | wx.ALL | wx.EXPAND, 5) 77 78 bSizer1.Add(sbSizer1, 1, wx.EXPAND, 5) 79 80 self.SetSizer(bSizer1) 81 self.Layout() 82 83 self.Centre(wx.BOTH) 84 85 # Connect Events 86 self.m_dirPicker1.Bind(wx.EVT_DIRPICKER_CHANGED, self.select_path) 87 self.m_button1.Bind(wx.EVT_BUTTON, self.download) 88 self.m_button2.Bind(wx.EVT_BUTTON, self.reset) 89 self.m_button6.Bind(wx.EVT_BUTTON, self.clear) 90 91 def __del__(self): 92 pass 93 94 # Virtual event handlers, overide them in your derived class 95 def select_path(self, event): 96 event.Skip() 97 98 def download(self, event): 99 event.Skip() 100 101 def reset(self, event): 102 event.Skip() 103 104 def clear(self, event): 105 event.Skip()
download_music.py
1 # coding: utf-8 2 """ 3 author: 我是冰霜 4 describe: 爬虫网易云音乐歌单 5 create_time: 2020/03/07 6 """ 7 8 from common.Net_music_GUI import MyFrame1 9 import wx 10 import requests 11 import re 12 import os 13 import time 14 from requests.exceptions import RequestException 15 16 17 base_url = "http://music.163.com/song/media/outer/url?id=" # 定义一个全局变量,该链接为下载url前缀,id为歌曲唯一的id值 18 headers={ 19 "authority": "music.163.com", 20 "method": "GET", 21 "path": "/", 22 "scheme": "https", 23 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3", 24 "accept-encoding": "gzip,deflate,br", 25 "accept-language": "zh-CN,zh;q=0.9", 26 "cache-control": "max-age=0", 27 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36" 28 } 29 30 class NetMusic(MyFrame1): 31 32 @staticmethod 33 def get_html_text(url, data=None, header=None, method=None, cookies=None): 34 """获取一个url的html格式文本内容""" 35 36 if method == "get": 37 response = requests.get(url=url, params=data, headers=header, cookies=cookies, timeout=10) 38 else: 39 response = requests.post(url=url, data=data, headers=header, cookies=cookies, timeout=10) 40 try: 41 if response.status_code == 200: 42 response.encoding = response.apparent_encoding 43 # print(response.status_code) 44 # print(response.text) 45 return response.text 46 return None 47 except RequestException: 48 print("请求失败") 49 return None 50 51 @staticmethod 52 def get_content(url): 53 """请求最终下载文件的url,返回二进制内容""" 54 # print("正在下载", url) 55 try: 56 r = requests.get(url, timeout=10) 57 if r.status_code == 200: 58 return r.content 59 else: 60 print("请求连接失败,url为:%s" % url) 61 except RequestException: 62 return None 63 64 def parse_html(self, request_url): 65 """解析歌单页面,提取元素""" 66 global headers 67 html_text = self.get_html_text(url=request_url, header=headers, method="get") # 调用get_html_text()方法,获取歌单页面响应内容 68 # print(html_text) 69 70 ###########使用正则表达式提取歌单名称、歌曲名称以及歌曲id############ 71 try: 72 title = re.search(r\'<title>(.*?) -.*?</title>\', html_text).group(1) # 匹配歌单名称 73 # print(title) 74 75 76 pattern_1 = re.compile(r\'<li><a.*?id=(\\d+)">\' # 匹配歌曲id 77 r\'(.*?)</a>\', re.S) # 匹配歌曲名称 78 musics = pattern_1.findall(html_text) # 查找所有结果,每组数据以一个元组形式,组成一个列表格式返回 79 # print(musics) 80 music_list = { 81 "title": title, 82 "music_list": musics 83 } 84 return music_list 85 except Exception as e: 86 print("请求歌单UR了出错,检查url是否正确,报错信息为:", e) 87 88 def download_music(self, music_url): 89 """下载文件至本地""" 90 91 global base_url 92 93 root_dir = self.m_dirPicker1.GetPath() # 获取GUI界面自定义选择的路径 94 # os.path.dirname(os.path.abspath(\'.\')) # 表示获取当前文件所在目录的上一级目录 95 """ 96 os.path.abspath(\'.\'), 获取当前文件所在路径; 97 os.path.dirname(path),返回path的目录; 98 """ 99 music_data = self.parse_html(music_url) # 调用parse_html()方法,获取歌单页面解析出来的数据 100 101 title = music_data["title"] # 获取歌单名称 102 # print(title) 103 if not os.path.exists(root_dir + \'/music\'): 104 os.makedirs(root_dir + \'/music\') # 在上一级目录下新建一个music文件夹 105 if not os.path.exists(root_dir + "/music/" + title): 106 os.makedirs(root_dir + "/music/" + title) # 在music下新建一个歌单目录 107 # print(root_dir) 108 109 music_list = music_data["music_list"] 110 # print(music_list) 111 i = 1 # 标记位,表示第i首音乐 112 j = 0 # 标记位,表示下载成功总个数 113 k = 0 # 标记位,表示下载失败总个数 114 # print(len(music_list)) # 获取歌单包含音乐总数 115 print("当前歌单共有{}首音乐,开始下载******".format(len(music_list))) 116 for music in music_list: 117 118 music_url = base_url + music[0] 119 music_name = music[1] 120 try: 121 file_path = root_dir + "/music/" + title + \'/\' + music_name + ".mp3" 122 # print(mote_pics_collection_path + \'/\' + img.split(\'/\')[-1]) 123 if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取 124 print("正在下载第{}首音乐:{}".format(i, "《"+ music_name +"》")) 125 self.m_textCtrl2.AppendText("正在下载第{}首音乐:{}{}".format(i, "《"+ music_name +"》", "\\n")) # 把日志追加到界面程序显示 126 # print(self.get_content(music_url)) 127 try: 128 with open(file_path, \'wb\') as f: 129 f.write(self.get_content(music_url)) 130 f.close() 131 i = i+1 132 j = j+1 133 134 except Exception as e: 135 print("遇到错误:", e) 136 print("第{}首下载失败,对应的歌曲url为:{}".format(i, music_url)) 137 self.m_textCtrl2.AppendText("第{}首下载失败,对应的歌曲url为:{}{}".format(i, music_url, "\\n")) 138 i = i+1 139 k = k+1 140 141 elif os.path.exists(file_path): 142 if os.path.getsize(file_path): 143 print("文件夹已经包含第{}首音乐:{}+{}".format(i, "《"+ music_name +"》", "\\n"以上是关于编写一个网易云音乐爬虫程序的主要内容,如果未能解决你的问题,请参考以下文章