编译原理-第二章 一个简单的语法指导编译器-2.2 词法分析
Posted 方知有
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理-第二章 一个简单的语法指导编译器-2.2 词法分析相关的知识,希望对你有一定的参考价值。
词法分析:
- 主要功能:词法分析器从输入中读入字符,并将它们组成词法单元对象
- 主要步骤:
- 预读:使用一个变量peek来保存当前已读入的数字或字符的下一个输入字符,来对已读入的字符进行预判,如果当前已读入字符能够识别,则peek设置为空白符。当词法分析器返回一个词法单元时,变量peek要么保存了当前词法单元的词素后的那个字符,要么保存空白符。
- 剔除空白和注释:

-
图2-29中的伪代码在遇到空格、制表符或换行符时不断读取输入字符,从而跳过了空白部分。变量peek存放了下一个输入字符。在错误消息中加入行号和上下文有助于定位错误。这个代码使用变量line统计输入中的换行符个数。
- 识别和计算常量:

-
图2-30中的伪代码读取一个整数中的数位,并用变量v累计得到这个整数的值。
- 识别关键字和标识符:

-
图2-31中的伪代码使用get操作来查找保留字。这个伪代码从输入中读取一个以字母开头、由字母和数位组成的字符串s。我们假定读取的s尽可能地长,即只要词法分析器遇到字母或数位,它就不断从输入中读取字符。当它遇到的不是字母或数位,比如它遇到了空白符,已读取的词素就被复制到缓冲区b中。如果字符串表中已经有一个s的条目,它就返回由words.get得到的词法单元。这里s可能是一个关键字,在表words初始化的时候这个s就已经在表中了;它也可能是一个之前被加入到表中的标识符。如果不存在s对应的条目,那么由id和属性值s组成的词法单元被加入到字符串表中,并被返回。
- 词法分析器:
- 主流程:

- 返回词法单元对象的函数scan
- 各个对象:
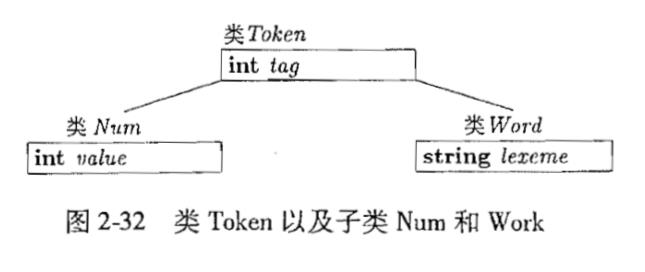
- 类Token:


- 类Token有一个tag字段,用于做出语法分析决定
- 子类Num和子类Word:

-
子类Num增加了一个字段value,用于存放整数值
-
子类Word增加了一个字段lexem,用于保存关键字和标识符的词素
- Lexer:

- 主流程:


参考-《编译原理(第二版)》
以上是关于编译原理-第二章 一个简单的语法指导编译器-2.2 词法分析的主要内容,如果未能解决你的问题,请参考以下文章