Spark history Server配置实用
Posted 尧字节
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark history Server配置实用相关的知识,希望对你有一定的参考价值。
Spark history Server产生背景
以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息;但该WEBUI随着Application的完成(成功/失败)而关闭,也就是说,Spark Application运行完(成功/失败)后,将无法查看Application的历史记录;
Spark history Server就是为了应对这种情况而产生的,通过配置可以在Application执行的过程中记录下了日志事件信息,那么在Application执行结束后,WEBUI就能重新渲染生成UI界面展现出该Application在执行过程中的运行时信息;
Spark运行在yarn或者mesos之上,通过spark的history server仍然可以重构出一个已经完成的Application的运行时参数信息(假如Application运行的事件日志信息已经记录下来);
配置&使用Spark History Server
以默认配置的方式启动spark history server:
cd $SPARK_HOME/sbin start-history-server.sh
报错:
starting org.apache.spark.deploy.history.HistoryServer, logging to /home/spark/software/source/compile/deploy_spark/sbin/../logs/spark-spark-org.apache.spark.deploy.history.HistoryServer-1-hadoop000.out
failed to launch org.apache.spark.deploy.history.HistoryServer:
at org.apache.spark.deploy.history.FsHistoryProvider.<init>(FsHistoryProvider.scala:44)
... 6 more
需要在启动时指定目录:
start-history-server.sh hdfs://hadoop000:8020/directory
hdfs://hadoop000:8020/directory可以配置在配置文件中,那么在启动history-server时就不需要指定,后续介绍怎么配置;
注:该目录需要事先在hdfs上创建好,否则history-server启动报错。
启动完成之后可以通过WEBUI访问,默认端口是18080:http://hadoop000:18080
默认界面列表信息是空的,下面截图是我跑了几次spark-sql测试后出现的。
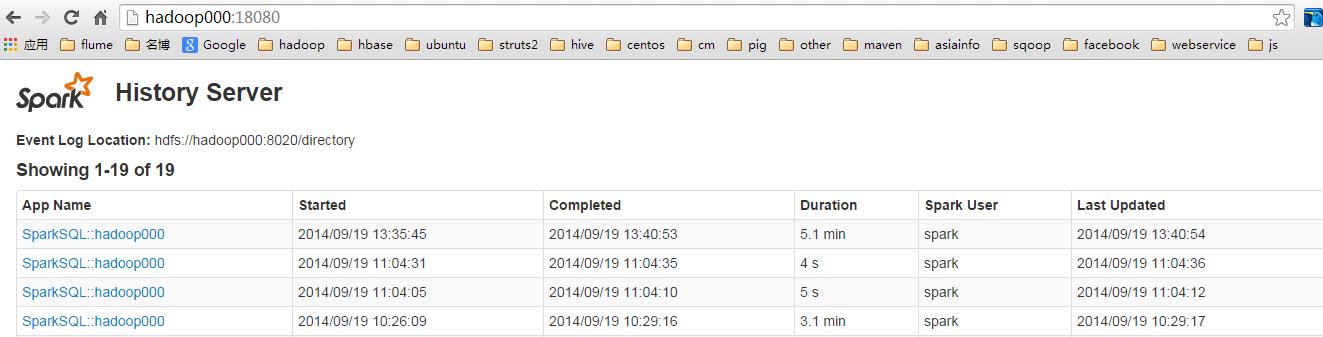
history server相关的配置参数描述
1) spark.history.updateInterval
默认值:10
以秒为单位,更新日志相关信息的时间间隔
2)spark.history.retainedApplications
默认值:50
在内存中保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,当再次访问已被删除的应用信息时需要重新构建页面。
3)spark.history.ui.port
默认值:18080
HistoryServer的web端口
4)spark.history.kerberos.enabled
默认值:false
是否使用kerberos方式登录访问HistoryServer,对于持久层位于安全集群的HDFS上是有用的,如果设置为true,就要配置下面的两个属性
5)spark.history.kerberos.principal
默认值:用于HistoryServer的kerberos主体名称
6)spark.history.kerberos.keytab
用于HistoryServer的kerberos keytab文件位置
7)spark.history.ui.acls.enable
默认值:false
授权用户查看应用程序信息的时候是否检查acl。如果启用,只有应用程序所有者和spark.ui.view.acls指定的用户可以查看应用程序信息;否则,不做任何检查
8)spark.eventLog.enabled
默认值:false
是否记录Spark事件,用于应用程序在完成后重构webUI
9)spark.eventLog.dir
默认值:file:///tmp/spark-events
保存日志相关信息的路径,可以是hdfs://开头的HDFS路径,也可以是file://开头的本地路径,都需要提前创建
10)spark.eventLog.compress
默认值:false
是否压缩记录Spark事件,前提spark.eventLog.enabled为true,默认使用的是snappy
以spark.history开头的需要配置在spark-env.sh中的SPARK_HISTORY_OPTS,以spark.eventLog开头的配置在spark-defaults.conf
我在测试过程中的配置如下:
spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop000:8020/directory spark.eventLog.compress true
spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=7777 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://had oop000:8020/directory"
参数描述:
spark.history.ui.port=7777 调整WEBUI访问的端口号为7777
spark.history.fs.logDirectory=hdfs://hadoop000:8020/directory 配置了该属性后,在start-history-server.sh时就无需再显示的指定路径
spark.history.retainedApplications=3 指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除
调整参数后启动start-history-server.sh
start-history-server.sh
访问WEBUI: http://hadoop000:7777
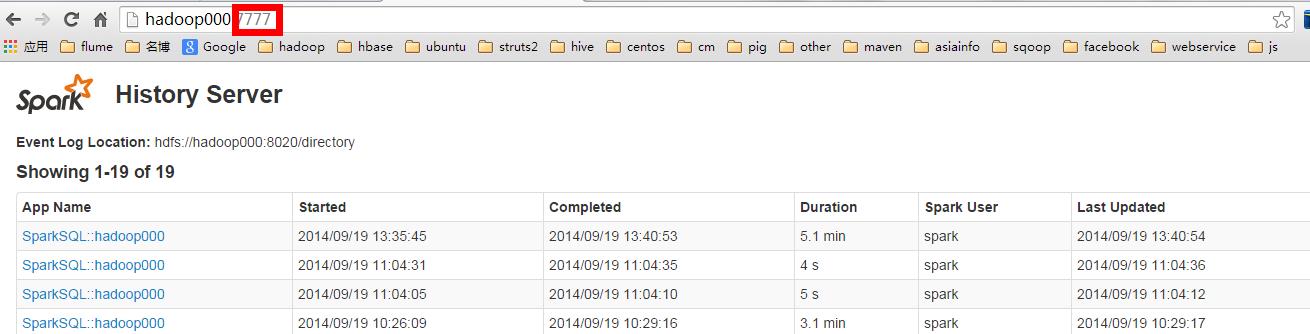
在使用spark history server的过程中产生的几个疑问:
疑问1:spark.history.fs.logDirectory和spark.eventLog.dir指定目录有啥区别?
经测试后发现:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.fs.logDirectory:Spark History Server页面只展示该指定路径下的信息;
比如:spark.eventLog.dir刚开始时指定的是hdfs://hadoop000:8020/directory,而后修改成hdfs://hadoop000:8020/directory2
那么spark.history.fs.logDirectory如果指定的是hdfs://hadoop000:8020/directory,就只能显示出该目录下的所有Application运行的日志信息;反之亦然。
疑问2:spark.history.retainedApplications=3 貌似没生效??????
The History Server will list all applications. It will just retain a max number of them in memory. That option does not control how many applications are show, it controls how much memory the HS will need.
注意:该参数并不是也页面中显示的application的记录数,而是存放在内存中的个数,内存中的信息在访问页面时直接读取渲染既可;
比如说该参数配置了10个,那么内存中就最多只能存放10个applicaiton的日志信息,当第11个加入时,第一个就会被踢除,当再次访问第1个application的页面信息时就需要重新读取指定路径上的日志信息来渲染展示页面。
详见官方文档:http://spark.apache.org/docs/latest/monitoring.html
以上是关于Spark history Server配置实用的主要内容,如果未能解决你的问题,请参考以下文章