Gensim-LDA实践
Posted bbking
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Gensim-LDA实践相关的知识,希望对你有一定的参考价值。
本文利用gensim进行LDA主题模型实验,第一部分是基于前文的wiki语料,第二部分是基于Sogou新闻语料。
1. 基于wiki语料的LDA实验
上一文得到了wiki纯文本已分词语料 wiki.zh.seg.utf.txt,去停止词后可进行LDA实验。
import codecs from gensim.models import LdaModel from gensim.corpora import Dictionary train = [] stopwords = codecs.open(\'stopwords.txt\',\'r\',encoding=\'utf8\').readlines()
stopwords = [ w.strip() for w in stopwords ] fp = codecs.open(\'wiki.zh.seg.utf.txt\',\'r\',encoding=\'utf8\') for line in fp: line = line.split() train.append([ w for w in line if w not in stopwords ]) dictionary = corpora.Dictionary(train) corpus = [ dictionary.doc2bow(text) for text in train ] lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=100)
同时gensim也提供了对wiki压缩包直接进行抽取并保存为稀疏矩阵的脚本 make_wiki,可在bash运行下面命令查看用法。
python -m gensim.scripts.make_wiki #USAGE: make_wiki.py WIKI_XML_DUMP OUTPUT_PREFIX [VOCABULARY_SIZE] python -m gensim.scripts.make_wiki zhwiki-latest-pages-articles.xml.bz2 zhwiki
运行时间比较久,具体情况可以看gensim官网,结果如下,mm后缀表示Matrix Market格式保存的稀疏矩阵:
-rw-r--r-- 1 chenbingjin data 172M 7月 1 12:10 zhwiki_bow.mm -rw-r--r-- 1 chenbingjin data 1.3M 7月 1 12:10 zhwiki_bow.mm.index -rw-r--r-- 1 chenbingjin data 333M 7月 1 12:16 zhwiki_tfidf.mm -rw-r--r-- 1 chenbingjin data 1.3M 7月 1 12:16 zhwiki_tfidf.mm.index -rw-r--r-- 1 chenbingjin data 1.9M 7月 1 12:10 zhwiki_wordids.txt
利用 tfidf.mm 及wordids.txt 训练LDA模型
# -*- coding: utf-8 -*- from gensim import corpora, models # 语料导入 id2word = corpora.Dictionary.load_from_text(\'zhwiki_wordids.txt\') mm = corpora.MmCorpus(\'zhwiki_tfidf.mm\') # 模型训练,耗时28m lda = models.ldamodel.LdaModel(corpus=mm, id2word=id2word, num_topics=100)
模型结果
训练过程指定参数 num_topics=100, 即训练100个主题,通过print_topics() 和print_topic() 可查看各个主题下的词分布,也可通过save/load 进行模型保存加载。
# 打印前20个topic的词分布 lda.print_topics(20) # 打印id为20的topic的词分布 lda.print_topic(20) #模型的保存/ 加载 lda.save(\'zhwiki_lda.model\') lda = models.ldamodel.LdaModel.load(\'zhwiki_lda.model\')
对新文档,转换成bag-of-word后,可进行主题预测。
模型差别主要在于主题数的设置,以及语料本身,wiki语料是全领域语料,主题分布并不明显,而且这里使用的语料没有去停止词,得到的结果差强人意。
test_doc = list(jieba.cut(test_doc)) #新文档进行分词 doc_bow = id2word.doc2bow(test_doc) #文档转换成bow doc_lda = lda[doc_bow] #得到新文档的主题分布 #输出新文档的主题分布 print doc_lda for topic in doc_lda: print "%s\\t%f\\n"%(lda.print_topic(topic[0]), topic[1])
2. 基于Sogou新闻语料的LDA实验
Sogou实验室提供了很多中文语料的下载, 全网新闻数据(SogouCA),来自若干新闻站点2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL和正文信息。
这里使用的是2008精简版(一个月数据, 437MB)

数据转码处理,由于数据是Ascii文件,容易出现乱码情况,使用iconv命令转成utf8,由于XML文件处理时需要有顶级tag,这里使用sed 命令在文件的首行前插入<root>,在尾行后插入</root>


#!/bin/bash #将文件夹下的Ascii文件转成utf8 #Usage: ./iconv_encode.sh indir outdir #@chenbingjin 2016-07-01 function conv_encode() { all=`ls ${indir}` for ffile in ${all} do ifile="${indir}${ffile}" ofile="${outdir}${ffile}" echo "iconv $ifile to $ofile" iconv -c -f gb2312 -t utf8 "$ifile" > "$ofile" sed -i \'1i <root>\' "$ofile" sed -i \'$a </root>\' "$ofile" done } if [ $# -ne 2 ]; then echo "Usage: ./iconv_encode.sh indir outdir" exit 1 fi indir=$1 outdir=$2 if [ ! -d $outdir ]; then echo "mkdir ${outdir}" mkdir $outdir fi time conv_encode
总共128个文件,存放在Sogou_data/ 文件夹下,使用iconv_encode.sh 进行处理,新文件保存在out文件夹,结果如下:
$ ./iconv_encode.sh Sogou_data/ out/ mkdir out/ iconv Sogou_data/news.allsites.010806.txt to out/news.allsites.010806.txt iconv Sogou_data/news.allsites.020806.txt to out/news.allsites.020806.txt iconv Sogou_data/news.allsites.030806.txt to out/news.allsites.030806.txt iconv Sogou_data/news.allsites.040806.txt to out/news.allsites.040806.txt ...... real 0m27.255s user 0m6.720s sys 0m8.924s
接下来需要对xml格式的数据进行预处理,这里使用lxml.etree,lxm 是Python的一个html/xml解析并建立dom的库, 比python自带的XML解析快。
防止出现异常 XMLSyntaxError: internal error: Huge input lookup ,设置XMLParser参数 huge_tree=True,详细见代码:
# -*- coding: utf-8 -*- import os import codecs import logging from lxml import etree logging.basicConfig(format=\'%(asctime)s : %(levelname)s : %(message)s\', level=logging.INFO) \'\'\' Sogou新闻语料预处理 @chenbingjin 2016-07-01 \'\'\' train = [] # huge_tree=True, 防止文件过大时出错 XMLSyntaxError: internal error: Huge input lookup parser = etree.XMLParser(encoding=\'utf8\',huge_tree=True) def load_data(dirname): global train files = os.listdir(dirname) for fi in files: logging.info("deal with "+fi) text = codecs.open(dirname+fi, \'r\', encoding=\'utf8\').read() # xml自身问题,存在&符号容易报错, 用&代替 text = text.replace(\'&\', \'&\') # 解析xml,提取新闻标题及内容 root = etree.fromstring(text, parser=parser) docs = root.findall(\'doc\') for doc in docs: tmp = "" for chi in doc.getchildren(): if chi.tag == "contenttitle" or chi.tag == "content": if chi.text != None and chi.text != "": tmp += chi.text if tmp != "": train.append(tmp)
得到train训练语料后,分词并去停止词后,便可以进行LDA实验
from gensim.corpora import Dictionary from gensim.models import LdaModel stopwords = codecs.open(\'stopwords.txt\',\'r\',encoding=\'utf8\').readlines()
stopwords = [ w.strip() for w in stopwords ] train_set = [] for line in train: line = list(jieba.cut(line))
train_set.append([ w for w in line if w not in stopwords ]) # 构建训练语料 dictionary = Dictionary(train_set) corpus = [ dictionary.doc2bow(text) for text in train_set] # lda模型训练 lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=20) lda.print_topics(20)
实验结果:训练时间久,可以使用 ldamulticore ,整体效果还不错,可以看出08年新闻主题主要是奥运,地震,经济等
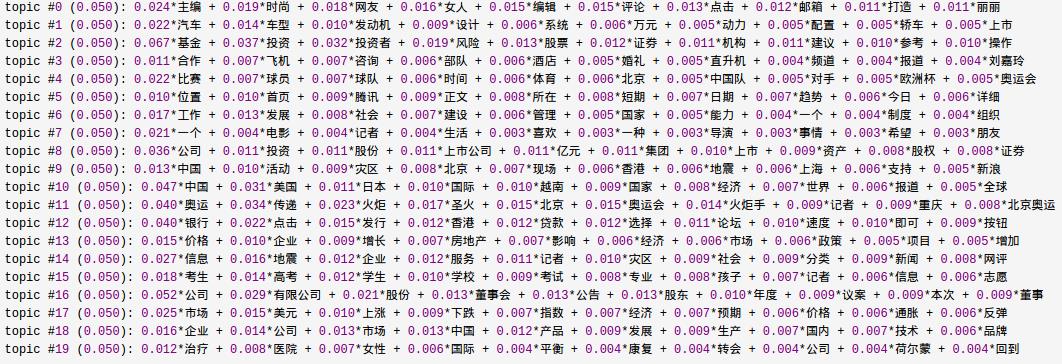
得到的LDA模型可用于主题预测,给定新的文档预测文档主题分布,可用于分类。训练文档中每个词会分配一个主题,有paper就将这种主题信息做Topic Word Embedding,一定程度上解决一词多义问题。
参考
1. gensim:Experiments on the English Wikipedia
2. Sogou:全网新闻数据
以上是关于Gensim-LDA实践的主要内容,如果未能解决你的问题,请参考以下文章