爬取抖音某个博主下面的全部视频
Posted 鱼虫光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取抖音某个博主下面的全部视频相关的知识,希望对你有一定的参考价值。
- 工具:charles,手机模拟器(我用的是mumu模拟器)
- 经过一番实验,本菜鸟发现,要抓抖音的包,必须要登录,而且还得用手机模拟器
- 发现URL
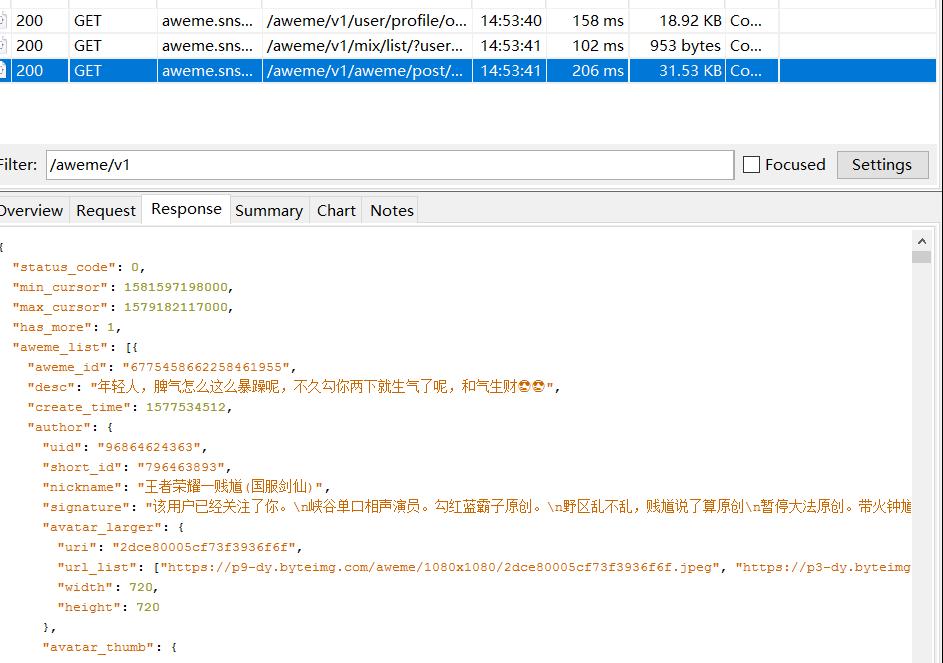

- 后面就比较简单了,直接上代码:
import json from time import time import requests from requests import urllib3 from jsonpath import jsonpath urllib3.disable_warnings() headers = { \'Accept-Encoding\': \'gzip\', \'X-SS-REQ-TICKET\': \'1581660428182\', \'sdk-version\': \'1\', \'Cookie\': \'install_id=103352043068; ttreq=1$d29781e6817415b2336bf64a341c5c52a774276d; d_ticket=f618ea679f55d5c2f8b80a9a6d094563e59df; odin_tt=a84c4ba69760c5508dc4deb0fc8d455602a0feaf37eb88ffc1ff6160c74134380e27fde9e3145770266377b503270b6a; msh=LwK4GHwRJ3HW0pYhRKoude--bdE; sid_guard=a0ff9b655c3fc7fd489a4f29c564b8b0%7C1581657235%7C5184000%7CTue%2C+14-Apr-2020+05%3A13%3A55+GMT; uid_tt=0849a342334709951bf7d36eca9b71ac; sid_tt=a0ff9b655c3fc7fd489a4f29c564b8b0; sessionid=a0ff9b655c3fc7fd489a4f29c564b8b0\', \'x-tt-token\': \'00a0ff9b655c3fc7fd489a4f29c564b8b0348cef63112f9c2de76300a6428a0d14d46d0638e964f7d6e4a44d229e0eebe25f\', \'X-Gorgon\': \'040120d9400141032e52e896e6e108d5d8030c421707c7b1da70\', \'X-Khronos\': \'1581660428\', \'Host\': \'aweme.snssdk.com\', \'Connection\': \'Keep-Alive\', \'User-Agent\': \'okhttp/3.10.0.1\' } url = \'https://aweme.snssdk.com/aweme/v1/aweme/post/?source=0&max_cursor=0&sec_user_id=MS4wLjABAAAAQgBRnIwhA5hR4wi7-TjXzE2-8ir5uwBpbT2a-gukccc&count=20&os_api=23&device_type=MI%205s&device_platform=android&ssmix=a&iid=103352043068&manifest_version_code=972&dpi=270&uuid=500000000189568&version_code=972&app_name=aweme&cdid=955be6dc-f79f-4480-ab01-0409eff3f75b&version_name=9.7.2&ts=1581660430&openudid=862bef236d1d353f&device_id=70748665911&resolution=810*1440&os_version=6.0.1&language=zh&device_brand=Xiaomi&app_type=normal&ac=wifi&update_version_code=9708&aid=1128&channel=tengxun_new&_rticket=1581660428228\' resp = requests.get(url, headers=headers, stream=True, verify=False) result = json.loads(resp.text) video_url_list = [] video_url_list1 = jsonpath(result, \'$..play_addr_lowbr\') desc_name_list = jsonpath(result, \'$..desc\') print(desc_name_list) for item in video_url_list1: video_url_list.append(item[\'url_list\'][0]) print(video_url_list) for i, url1 in enumerate(video_url_list): resp1 = requests.get(url1) with open(\'{}.mp4\'.format(desc_name_list[i]), \'wb\')as f: for content in resp1.iter_content(1024): if content: f.write(content) #因为只是爬了一个博主一个版面的视频,往下拉,还会有类似的请求就没有爬取,都一样,只是url里面的max_cursor变成了时间戳*1000的值,count变成10,每次下拉的cookie也可能会变(我没有试验过)
#比如我爬取的这个博主有62个视频,抓包发现第一次url里面count是20,后面五次count都是10,获取70个但博主只有62个,从第二次请求开始count由20变为10
#要大量爬取的话要多准备点抖音账号登录获取cookie,可以采用redis+flask的方法搭建cookie池,详情可以参见崔庆才大佬的博客,抖音cookie过期比较快,貌似十分钟左右就过期了,可能还要用到代理
- 结果:

爬下来都是无水印的,大家可以用来此方法来收集抖音里面自己喜欢的小姐姐视频哦
不过不要做什么侵权的事情哦,
爬虫大佬不要喷我,我只是个菜鸡
抖音策略更新很快,大家对于这篇博客,主要还是学会charles怎么抓手机的包,这个是重点,至于方法,网上一大堆
以上是关于爬取抖音某个博主下面的全部视频的主要内容,如果未能解决你的问题,请参考以下文章