《Linux内核设计与实现》笔记——内核同步简介
Posted xcy6666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Linux内核设计与实现》笔记——内核同步简介相关的知识,希望对你有一定的参考价值。
相关概念
竞争条件
多个执行线程(进程/线程/中断处理程序)并发(并行)访问共享资源,因为执行顺序不一样造成结果不一样的情况,称为竞争条件(race condition)
举例说明
#include<thread>
using namespace std;
int i = 0;
void thread1(){
//for(int x=0;x<100000;x++)
i++;
}
void thread2(){
//for(int x=0;x<100000;x++)
i++;
}
int main(){
std::thread t1(thread1);
std::thread t2(thread1);
t1.join();
t2.join();
printf(" i = %d\\n",i);
}t1,t2两个线程并发执行时有可能发生竞争条件(当然这个程序发生竞争条件概率很低,但如果你把注释去掉,竞争条件就非常容易发生了)
i++;这条语句一般需要3条机器指令
MOV EAX,i
INC EAX
MOV EAX,i如果按照如下顺序执行,是没有有问题的,打印出的i是2
| thread 1 | thread 2 |
|---|---|
| MOV EAX,i(i=0) | |
| INC EAX | |
| MOV EAX,i(i=1) | |
| MOV EAX,i(i=1) | |
| INC EAX | |
| MOV EAX,i(i=2) |
但是两个线程很可能按照如下顺序执行,此时就会出现竞争条件,打印出的i是1
| thread 1 | thread 2 |
|---|---|
| MOV EAX,i (i=0) | |
| INC EAX | |
| MOV EAX,i (i=0) | |
| MOV EAX,i (i=1) | |
| INC EAX | |
| MOV EAX,i (i=1) |
临界区(critical section)是指 访问和操作共享资源的代码段,例子里就是两个线程的i++语句
为避免竞争条件,临界区必须原子地执行,执行结束前不能被打断。一般会对临界区加锁,使用信号量,条件变量等,例子中的简单操作也可以使用原子变量。
原子性的理解
一般书上对原子性的解释为执行结束前不能被打断。这句话如何理解呢,我个人的理解是:
- 原子变量这种,使用锁总线的方式来实现,相关的若干条指令是连续执行的;
- 使用锁(自旋锁/睡眠锁),信号量,条件变量/完成变量这些,并不是说临界区的所有指令连续执行,可能在临界区执行到了一半,因为调度抢占或者中断,CPU不继续在临界区内执行,也就是执行被打断了。
- 但是这种情况依旧能保证避免竞争条件,原因在于,如果被打断的进程之外的进程被调度,该进程要想访问临界区的时候,被锁或者信号量等“拦住”,是进入不了临界区的,直到原被打断的临界区执行完毕,释放锁/信号量等,其他进程才有可能进入临界区。
造成并发的原因
- 中断:中断几乎可以在任何时刻异步发生,也就可能随时打断当前正在执行的代码
- 软中断和tasklet:内核能在任何时候唤醒或调度软中断和tasklet,打断当前正在执行的代码
- 内核抢占:Linux内核具有抢占性,所以内核的任务可能被另一任务抢占
- 睡眠及用户空间的同步:在内核执行的进程可能会睡眠,会唤醒调度程
序,从而调度一个新的用户进程执行 - SMP,两个或多个处理器可以同时执行代码
内核中的同步手段
加锁
为了避免竞争条件,内核提供了几个机制用于同步,基本思路就是加锁,临界区互斥访问,信号量也可以支持多于一个线程并发访问。
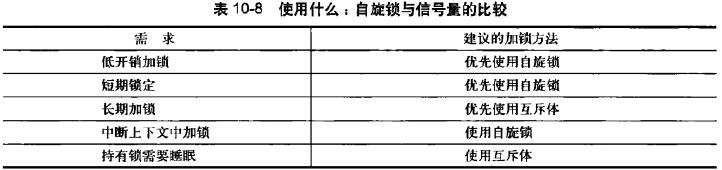
锁的争用
指所被占用时,有其他线程试图获得该锁。锁的争用程度越高,系统性能也就会越低(加锁会降低系统性能,比如睡眠锁,自旋锁),但是为保证正确性有必须使用。要降低锁的争用,加锁粒度要尽可能小,也就是临界区要尽量小。
几种同步方法简介
| 同步方法 | 主要接口 | 备注 |
|---|---|---|
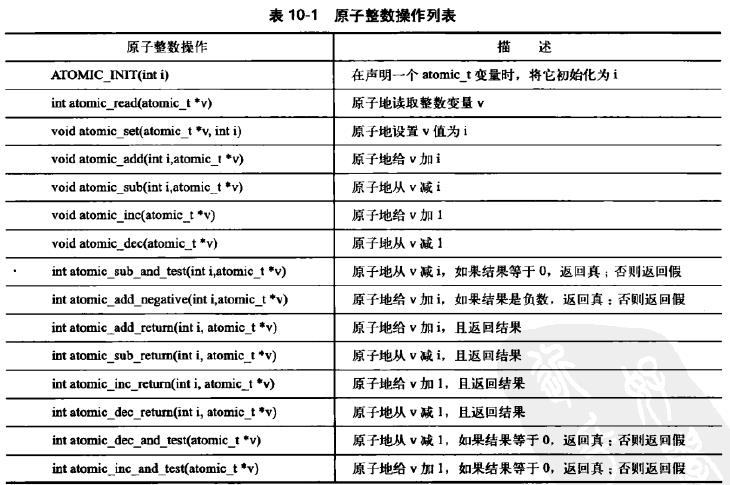
| 原子整数(32bit)操作 | atomic_t v;/*定义 v*/ | |
atomic_t u = ATOMIC_INIT(0);/*定义u,初始化为0*/ | ||
atomic_set(&v, 4);/* v=4 */ | ||
atomic_add(2, &v);/* v=v+2 */ | ||
atomic_inc(&v);/* v=v+1 */ | ||
| 原子整数(64bit)操作 | atomic64_t v; | |
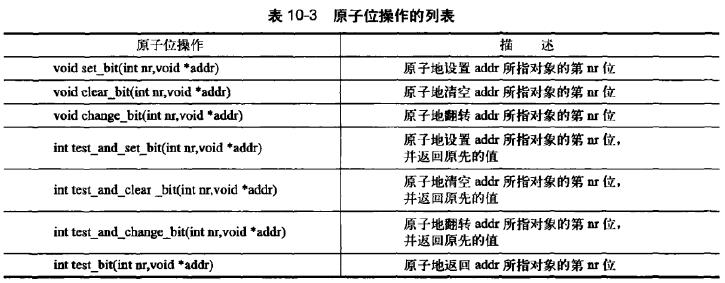
| 原子位操作 | unsigned long word = 0; | 对普通的指针进行操作 |
set_bit(0,&word); //第0位被设置 | __set_bit形式为非原子操作 | |
set_bit(1,&word); //第1位被设置 | 如果不需要原子操作,非原子操作更快一些 | |
printk("%ul\\n",word);//打印3 | 《linux内核设计与实现》P147 | |
clear_bit(1,&word);//清空第1位 | ||
change_bit(0,&word);//反转第0位 | ||
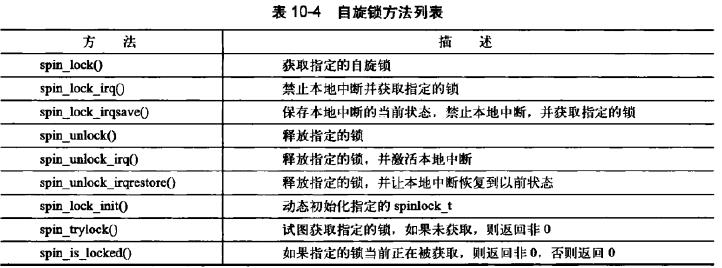
| 自旋锁 | DEFINE_SPINLOCK(mr_lock); | 自旋锁在同一时刻只能由一个线程位于临界区 |
spin_lock(&mr_lock); | 可为多处理器提供并发访问所需的保护机制 | |
/*临界区*/ | 单处理机,当作一个内核抢占是否开启的开关,如果禁止内核抢占,编译时自旋锁会被完全剔除内核 | |
spin_unlock(&mr_lock); | 自旋锁不可递归 | |
| 自旋锁和下半部 | 下半部和进程上下文共享数据/下半部和中断处理程序共享数据,需要加锁 | 下半部可以抢占进程上下文,中断处理程序可以抢占下半部 |
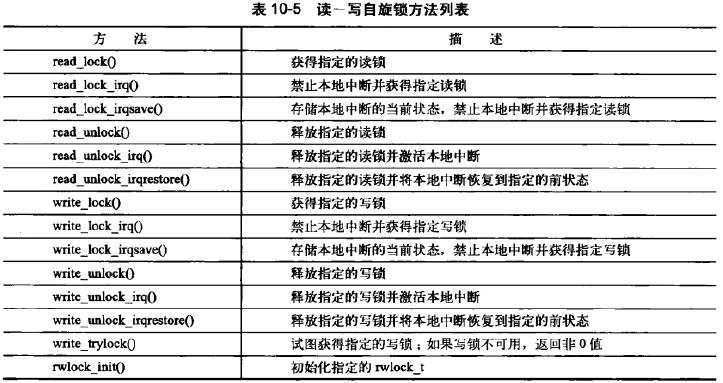
| 读写自旋锁 | DEFINE_RWLOCK(mr_rwlock); | |
read_lock(&mr_rwlock); | 所有读者共享 | |
/*临界区(只读)*/ | ||
read_unlock(&mr_rwlock); | ||
write_lock(&mr_rwlock); | 写者相互排斥,写者和读者互斥 | |
/*临界区(读写)*/ | ||
write_unlock(&mr_rwlock); | ||
| 信号量 | struct semophore name; | 争用的线程会睡眠,因此适合锁会被长时间占有的情况 |
sema_init(&name, count); | 在进程上下文中使用 | |
static DECLARE_MUTEX(name); | ||
init_MUTEX(sem) | 动态初始化互斥信号量 | |
static DECLARE_MUTEX(mr_sem); | ||
if(down_interruptible(&mr_sem)){ /*信号被接收,信号量还未获取*/ } | ||
/*临界区*/ | ||
up(&mr_sem);//释放给定的信号量 | ||
| 读写信号量 | static DECLARE_RWSEM(mr_rwsem); | 静态定义 |
init_rwsem(struct rw_semaphore *sem); | 动态初始化 | |
down_read(&mr_rwsem); | ||
/*临界区(只读)*/ | ||
up_read(&mr_rwsem); | ||
down_write(&mr_rwsem); | ||
/*临界区(读写)*/ | ||
up_write(&mr_rwsem); | ||
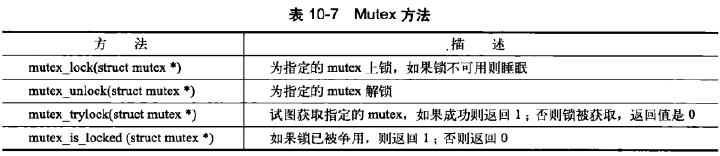
| 互斥体 | DEFINE_MUTEX(name); | 用于处理互斥的睡眠锁 |
mutex_init(&mutex); | 动态初始化 | |
mutex_lock(&mutex) | 不能递归上锁和解锁 | |
/*临界区*/ | 不能再中断或下半部执行 | |
mutex_unlock(&mutex) | ||
| 完成变量 | DECLARE_COMPLETION(mr_comp) | 等待,知道任务完成,发出信号 |
init_completion(); | 动态创建 | |
| 等待任务调用 | wait_for_completion(); | |
| 产生事件的任务调用 | complete();//发送信号唤醒特定事件 |
关于大内核锁BLK,顺序锁的内容见《Linux内核设计与实现》P160
禁止抢占
内核抢占代码使用自旋锁作为非抢占区域的标记
可以禁用抢占

更简洁的解决每个处理器上的数据访问问题,get_cpu()获取处理器编号,返回处理器编号前会先关闭内核抢占
int cpu;
cpu = get_cpu;//禁止内核抢占,将CPU设置为当前cpu
/*对每一个cpu的数据进行操作*
/*在给予内核抢占性,“cpu”可改变,所以不再有效*/
put_up();顺序和屏障
保证顺序的原因
- 多处理器之间,硬件设备的同步问题时,需要在程序代码中按照指定的顺序读取内存和写入内存。
- 和硬件交互时,常需要保证给定读操作在其他读/写操作之前
- 多处理器上,可能需要按照写数据的顺序读数据。
为了效率,编译器(编译优化)和处理器(乱序执行)可能对读和写重新排序。
- 所有可能重新排序读写的cpu提供机器指令,确保按顺序执行。
- 也可以指示编译器不进行给定点周围的指令序列进行重新排序。
e.g.
//可能重新排序
a=1;
b=2;
//不可能重新排序
a=1;
b=a;
举例解释保证顺序的原因
a=1,b=2
| 线程1 | 线程2 |
|---|---|
| a=3; | – |
| mb(); | – |
| b=4; | c=b; |
| – | rmb(); |
| – | d=a; |
如果没有内存屏障,某些处理器上,可能c接受了b的新值4,d接受了a原来的值1
几个方法
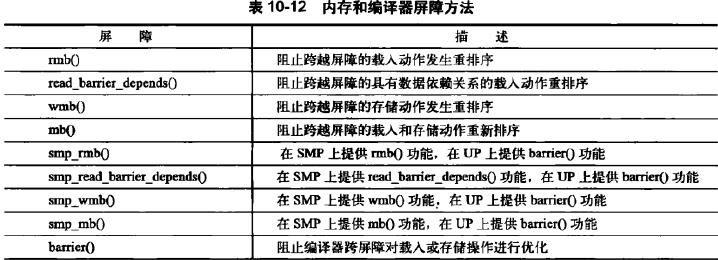
完整接口列表
截图自《Linux内核设计与实现》第10章



以上是关于《Linux内核设计与实现》笔记——内核同步简介的主要内容,如果未能解决你的问题,请参考以下文章