scrapy+baiduapi搭建一个私人小说阅读器(智能爬取加智能朗读)
Posted comicwang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy+baiduapi搭建一个私人小说阅读器(智能爬取加智能朗读)相关的知识,希望对你有一定的参考价值。
写在前面的话
喜欢看小说,平时都是通过电脑或者手机看小说,手机听小说(智能语音),或者喜马拉雅搜索小说听(好多喜欢的都收费o(╥﹏╥)o,然后网上好多免费资源却不能听),想在电脑上听小说,目前Microsoft Edge可以阅读网页文本很赞,不能自动翻译很烦(# ̄~ ̄#),而且智能语音库体验很差,所以想一个能搜索网上资源智能朗读的东东,木有发现好的,就自己写一个吧!
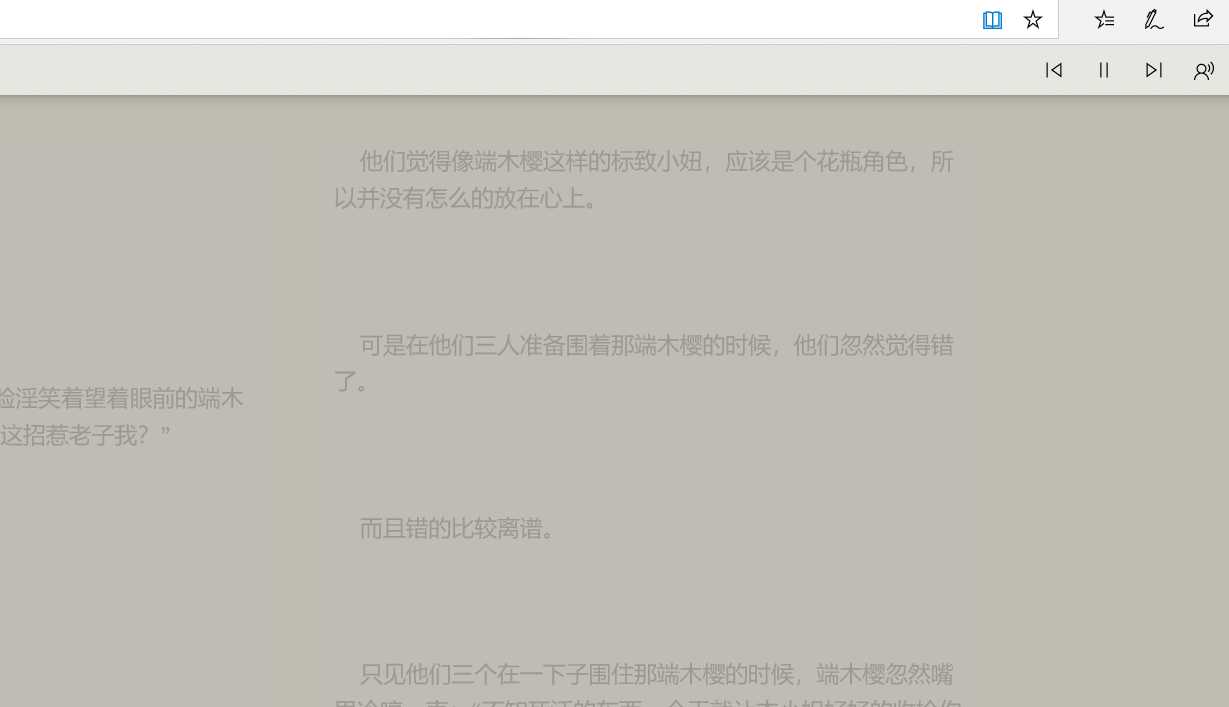 (Microsoft Edge阅读视图朗读示例)
(Microsoft Edge阅读视图朗读示例)
小说资源获取(scrapy爬虫获取biquge资源)
1.scrapy环境搭建,这里就不说了,网上资源一堆,我也收录了一个,不知道可以看看,附带一个scrapy经典的架构图(转载)
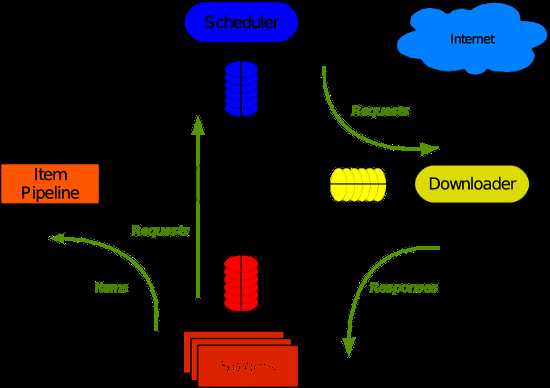
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
2.核心代码编写,按照爬虫架构,来编写爬虫及各个中间件内容(见代码)
爬虫核心代码(BiqugeSpider),最高爬取深度4层,同时定义了关键字和全文爬取2种策略
第1层 根据关键字搜索小说列表(默认函数parse),这里主要根据获取分页所有页url,传递给下一层,小说的基本信息列表爬取层
代码如下(这里xpath就不做介绍了,有兴趣自己学习下):
def parse(self, response): index=0 #检索小说(这里通过判断关键字来进行全文或者关键字爬取) if self.p: for each in response.xpath("//*[@class=‘search-result-page-main‘]/a"): src=each.attrib[‘href‘] yield scrapy.Request(self.domainUrl+ src, callback = self.ParsePage,dont_filter=False) else: for each in response.xpath("//*[@id=‘main‘]/div[1]/ul/li"): if index>0: src=each.xpath(".//span[2]/a")[0].attrib[‘href‘] yield scrapy.Request(self.domainUrl+ src, callback = self.BookBasic,dont_filter=False) index=index+1
第2层 根据小说基本信息列表获取每本小说的详情url,传递给下一层,小说基本信息爬取层
图和第一层类似,这里省略
代码如下:
#获取分页内容,进行关键字深度爬取 def ParsePage(self,response): for each in response.xpath("//*[@class=‘result-list‘]/div"): src=each.xpath(".//div/a")[0].attrib[‘href‘] yield scrapy.Request(self.domainUrl+ src, callback = self.BookBasic,dont_filter=False)
第3层 根据小说分页列表获取每本检索到小说的基本信息,同时获取章节列表url,传递给下一层,小说内容爬取层
代码如下:(存储了小说的名称、作者、简介信息)
#获取小说基本信息,同时让调度器爬取小说内容 def BookBasic(self,response): Id=uuid.uuid1() BookName=response.xpath("string(//*[@id=‘info‘]/h1)")[0].root.strip() Author=response.xpath("string(//*[@id=‘info‘]/p)")[0].root.strip().split(‘:‘)[1] imgSrc=response.xpath("//*[@id=‘fmimg‘]/img")[0].attrib[‘src‘] img= requests.get(imgSrc) Image= img.content LatestChapter=response.xpath("string(//*[@id=‘info‘]/p[4]/a)")[0].root.strip() Desc1=response.xpath("string(//*[@id=‘intro‘])")[0].root.strip() #查询小说是否存在 resp= self.mysql.Query("select Id from BookBasic where BookName=‘{0}‘".format(BookName)) if not resp: # 获取小说信息 Id=uuid.uuid1() #插入数据 self.mysql.ExecuteSql("insert into BookBasic (BookName,Author,Image,LatestChapter,Desc1,Id) values(%s,%s,%s,%s,%s,%s)",(str(BookName),str(Author),Image,str(LatestChapter),str(Desc1),str(Id))) else: Id=resp[0][0] self.mysql.ExecuteSql("update BookBasic set LatestChapter=%s,Desc1=%s where Id=%s",(str(LatestChapter),str(Desc1),str(Id))) #查询所有章节 list=self.mysql.Query("select Title from BookContent where Id=‘{0}‘".format(str(Id))) index=0 listName=[] for each in response.xpath("//*[@id=‘list‘]/dl/dd"): try: src= each.xpath(".//a")[0].attrib[‘href‘] title=each.xpath("string(.//a)")[0].root.strip() if self.InTable(list,title): print(title,"已经入库...") elif title in listName: print(title,"重复章节...") else: request= scrapy.Request(self.domainUrl+ src, callback = self.BookContent,dont_filter=False) request.meta[‘id‘]=Id request.meta[‘Chapter‘]=index index=index+1 listName.append(title) yield request except Exception as e: print("analysis item error:"+item["title"]+ e);
第4层 根据小说章节url获取小说内容信息,存储小说内容,到此,小说内容全部爬取完成

代码如下:
#爬取每个章节小说内容 def BookContent(self,response): try: item=BiqugespiderItem() item[‘Title‘]=response.xpath("string(//*[@class=‘bookname‘]/h1)")[0].root.strip() item[‘Content‘]=response.xpath("string(//*[@id=‘content‘])")[0].root.strip() item[‘Id‘]= response.meta[‘id‘] item[‘Chapter‘]= response.meta[‘Chapter‘] yield item except Exception as e: print("login item error:"+item["title"]+ e);
3.持久化处理
上面说到了爬虫的内容怎么获取,下面说到存储,当然这层可以自己处理,这里为了方便使用腾讯云mysql进行存储小说信息(mysql帮助类)
数据库和表结构初始化:
#初始化数据库 def IniMysql(self): #创建数据库 conn=pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,database=‘mysql‘) sql=‘create database if not exists Biquge‘ cursor=conn.cursor() cursor.execute(sql) cursor.close() conn.close() #创建表 conn=pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,database=self.defaultDb) cursor=conn.cursor() sql= """CREATE TABLE IF NOT EXISTS BookBasic( BookName varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT ‘书名‘, Author varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘作者‘, Image longblob NULL COMMENT ‘书封面‘, LatestChapter varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘最新章节‘, Desc1 varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘内容描述‘, Id char(36) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT ‘主键‘, PRIMARY KEY (`Id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; """ cursor.execute(sql) sql="""CREATE TABLE IF NOT EXISTS BookContent( DId char(36) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, Title varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘详情标题‘, Content longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT ‘内容信息‘, Id char(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘书主键‘, Chapter varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT ‘章节‘, SyncTime datetime(0) NULL DEFAULT NULL COMMENT ‘入库时间‘, PRIMARY KEY (`DId`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; """ cursor.execute(sql) cursor.close() conn.close()
小说基本信息存储代码:
if not resp: # 获取小说信息 Id=uuid.uuid1() #插入数据 self.mysql.ExecuteSql("insert into BookBasic (BookName,Author,Image,LatestChapter,Desc1,Id) values(%s,%s,%s,%s,%s,%s)",(str(BookName),str(Author),Image,str(LatestChapter),str(Desc1),str(Id))) else: Id=resp[0][0] self.mysql.ExecuteSql("update BookBasic set LatestChapter=%s,Desc1=%s where Id=%s",(str(LatestChapter),str(Desc1),str(Id)))
小说内容信息存储代码:
class BiqugespiderPipeline(object): def process_item(self, item, spider): DId=uuid.uuid1() SyncTime=datetime.datetime.now() mysql=MySqlComment() mysql.ExecuteSql("insert into BookContent values(%s,%s,%s,%s,%s,%s)",(str(DId),str(item[‘Title‘]),str(item[‘Content‘]),str(item[‘Id‘]),str(item[‘Chapter‘]),SyncTime)) return item
数据库存储结果:
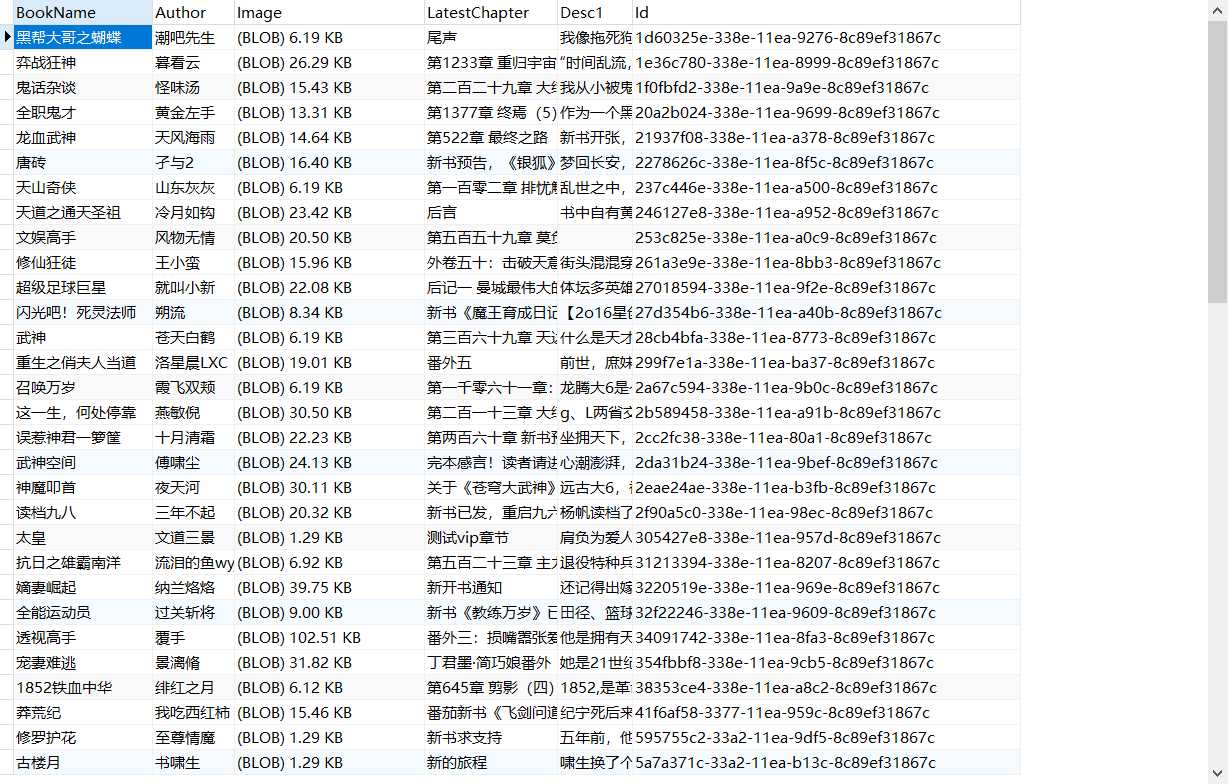 (小说基本信息)
(小说基本信息)
 (小说内容信息)
(小说内容信息)
4.代码地址
只能朗读客户端下一章继续写,代码github地址先附上
以上是关于scrapy+baiduapi搭建一个私人小说阅读器(智能爬取加智能朗读)的主要内容,如果未能解决你的问题,请参考以下文章