你所不知道的charCodeAt与codePointAt(了解js字符串的码元与码点)
Posted yongg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你所不知道的charCodeAt与codePointAt(了解js字符串的码元与码点)相关的知识,希望对你有一定的参考价值。
charCodeAt与codePointAt的用法:
相同点:
charCodeAt与codePointAt都是字符串实例上的方法,用途都是用来返回指定索引位字符的Unicode编码。
不同点:
charCodeAt与codePointAt匹配索引位的规则不一样。charCodeAt是根据码元来匹配,codePointAt是根据码点来进行匹配的。
先举个例子:
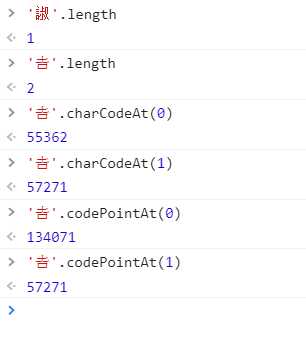
可以发现一个非常神奇的事情。
有些中文字符?? 的长度不为1,并且charCodeAt与codePointAt对相同字进行处理返回的结果却是不同的。
有人说念‘gei给’,有人说念‘ji‘同吉,反正是个古文字
这其中的原因就是charCodeAt是以一个码元为一个索引,codePointAt是以一个码点为一个索引进行处理的
Unicode使用16位二进制来存储文字。我们将一个16位的二进制编码叫做一个码元(Code Unit),Unicode编码范围在0 - 2^16。也就是我们所说的占一个字节。
由于技术的发展,Unicode对文字编码进行了扩展,将某些文字扩展到了32位(占用两个码元),并且,将某个文字对应的二进制数字叫做码点(Code Point),Unicode编码范围在0 - 2^32,占2个字节。
特别要注意,码点可以是一个码元,也可以是两个码元。
字符串的length属性返回的是码元。所以在对一些字符串如果要处理长度的时候要注意这一点。
??这个字的Unicode编码是ud842udfb7,占用了两个码元。
所以当用charCodeAt(0)是匹配0位的码元,也就是返回给我们55362。
当用codePointAt(0)是匹配0位的码元,codePointAt能识别出字符串的码点,所以反回134071。
??.codePointAt(1)为什么返回的是57271呢?
这是因为索引位是根据码元,而匹配的规则是根据码点的规则。如果后面两位码元是一个码点,就会当作一个码点来处理。
总结
charCodeAt是以码元为单位来处理的,也就是说按照每16位2进制数为单位。一个16位2进制数就是一位,所以处理不了Unicode扩展编码字符(32位2进制)。他会把32位2进制数当成两个16位2进制数处理
codePointAt也是以码元位单位来处理的。与charCodeAt不同的地方是,当处理到当前位码元时,如果超过了16位2进制数值的上线,他就明白这是一个32位2进制数,就会以32位2进制数当作一个来处理。
可以通过codePointAt来判断当前字符是是32位的码点还是16位的码元
function is32bit(char, i) { //如果码点大于了16位二进制的最大值,则其是32位的 return char.codePointAt(i) > 0xffff; }
同样的,也可以通过这个方法来判断以字符串真实的长度(码点的长度)
function getLengthOfCodePoint(str) { var len = 0; for (let i = 0; i < str.length; i++) { //i在索引码元 if (is32bit(str, i)) { //当前字符串,在i这个位置,占用了两个码元 i++; } len++; } return len; }
以上是关于你所不知道的charCodeAt与codePointAt(了解js字符串的码元与码点)的主要内容,如果未能解决你的问题,请参考以下文章