Python正则表达式详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python正则表达式详解相关的知识,希望对你有一定的参考价值。
如果是匹配url呢? from urllib.parse import urlparse 了解一下
2019年前端必用正则(js)
python正则详细讲解带有示例
下面这张大图有示例:需要拖到另一个网页可以看的更清楚
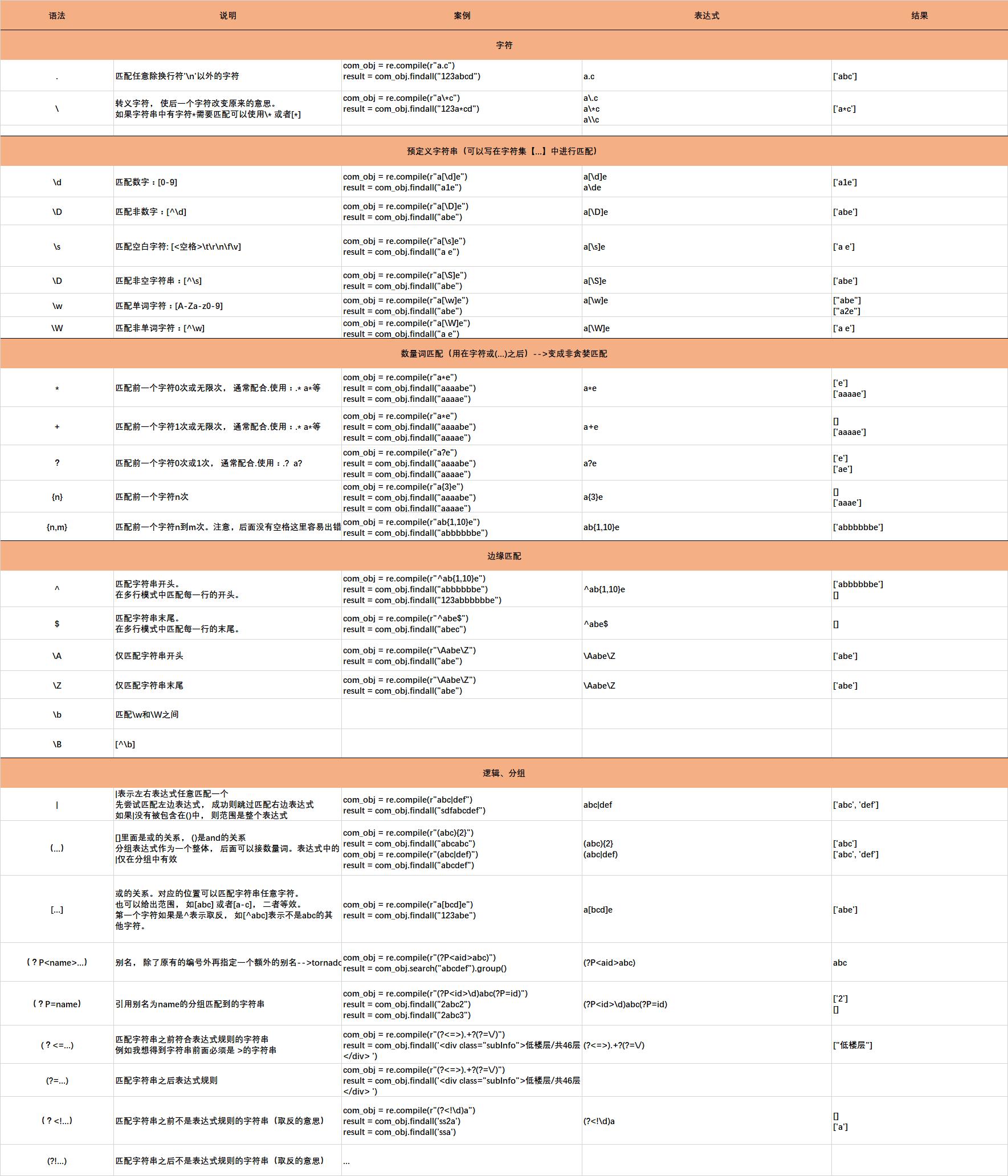
练习:
<div class="subInfo">低楼层/共46层</div> 正则表达式 如何提取“低楼层” 而不要后面的“共46层” 代码: (?<=>).+?(?=\\/)
python正则表达式
^ 匹配开始 $ 匹配行尾 . 匹配出换行符以外的任何单个字符,使用-m选项允许其匹配换行符也是如此 [...] 匹配括号内任何当个字符(也有或的意思) [^...] 匹配单个字符或多个字符不在括号内 * 匹配0个或多个匹配前面的表达式 + 匹配1个或多个前面出现的表达式 ? 匹配0次或1次前面出现的表达式 {n} 精确匹配前面出现的表达式的数量 {n,m} 匹配至少n次到m次 a | b 匹配a或b *?,+?,??,{m,n}? 这样在*,+,?,{m,n} 变成非贪婪模式 (re) 组正则表达式并及时匹配的文本 (?imx) 暂时切换上i,m或x震泽表达式的选项,如果括号中,仅该地区受到影响 (?: re) 组正则表达式而匹配的记住文字 (?#....) 注释 (?=re) 指定使用的模式位置,没有一个范围 (?!re) 使用指定模式取反位置,没有一个范围 (?<n1>..) 用列表的方式匹配
url(r\'^abc/(?P<name>\\w+/)$\',views.cccc), http://127.0.0.1:8000/adfadfasdf213/ 得到值adfadfasdf213/
(r"/index/(?P<page>\\d*)", home.IndexHandler),
\\d 数字[0-9] digit
\\D 非数字 == [^0-9] or [^\\d]
\\s 空白字符
\\S 非空白字符
\\w 字母数字下划线 word
\\W 非字母数字下划线
正则表达式是一个特殊的字符序列,他能帮你检查字符串是否与某种模式匹配
re模块
re模块使用python拥有全部的正则表达式功能
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法) re.M(MULTILINE):(多行模式,改变“^”,"$"的行为) re.S(DOTALL):(点任意匹配模式,改变"." 的行为) re.X(VERBOSE):详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
re.complit
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换
格式:re.match(pattern,string,flags=0) #pattern: 正则模型, string:要匹配的字符串 falgs:匹配模式
a = re.complit(r"\\d*", re.I) b = a.match("ABCde")
re.match --》从起始位置匹配
re.match 函数尝试从字符串的其实位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
print(re.match(\'com\',\'comwww.runcomoob\').group()) print(re.match(\'com\',\'Comwww.runcomoob\',re.I).group()) 执行结果: com com
re.seach --》匹配到第一个就返回,否则为None
re.search(pattern,string,flags=0)
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None
print(re.search(\'\\dcom\',\'www.4comrunoob.5com\').group()) 执行结果: 4com
*注:match 和search一旦匹配成功,就是一个match object对象,而match object 对象有以下方法:
·group()返回被RE匹配的字符串
·start()返回匹配开始的位置
·end()返回匹配结束的位置
·span()返回一个元组包含匹配(开始,结束)的位置
·group()返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串
a. group()返回re整体匹配的字符串,
b. group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常
c.groups()groups() 方法返回一个包含正则表达式中所有小组字符串的元组,从 1 到所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则表达式中定义的组。
import re a = "123abc456" print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) #123abc456,返回整体 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) #123 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) #abc print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) #456
u= "http://k.autohome.com.cn/325/quality/02#pvareaid=#2073101"
import re
print re.search("\\d{2}(?=#)",u).group()
>> 02
###group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。###
re.findall --》遍历匹配
re.findall 遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表 格式:
re.findall(pattern,string,flags=0)
p = re.compile(r\'\\d+\') print(p.findall(\'o1n2m3k4\')) 执行如果如下: [\'1\',\'2\',\'3\',\'4\'] import re tt = "Tina is a good girl , she is cool ,clever, and so on ..." rr = re.compile(r\'\\w*oo\\w*\') print(rr.findall(tt)) print(re.findall(r\'(\\w)*oo(\\w)\'tt)) 执行结果如下 [\'good\',\'cool\'] [(\'g\',\'d\'),(\'c\',\'l\')]
re.finditer
finditer()
搜索string,返回一个顺序访问每一个匹配结果(match对象)的迭代器。找到RE匹配的所以子串,并把他们昨晚一个迭代器返回
格式:re.finditer(pattern,string,flags=0)
iter = re.finditer(r\'\\d+\',\'12 drumm44ers drumming, 11.. 10..\') for i in iter: print(i) print(i.group()) print(i.span()) 执行结果如下: <_sre.SRE_Match object; span=(0, 2), match=\'12\'> 12 (0, 2) <_sre.SRE_Match object; span=(8, 10), match=\'44\'> 44 (8, 10) <_sre.SRE_Match object; span=(24, 26), match=\'11\'> 11 (24, 26) <_sre.SRE_Match object; span=(31, 33), match=\'10\'> 10 (31, 33)
re.split
split()
安装能够匹配的字符串将string分割后返回列表
可以使用re.split来分割字符串,如:re.split(r\'\\s+\',text);将字符串按空格分割成一个单词列表
格式:re.split(pattern,string[,maxsplit])
print(re.split(\'\\d+\',\'one1two2three3four4five5\')) 执行结果如下: [\'one\',\'two\',\'three\',\'four\',\'five\']
re.sub
sub()
使用re替换string中每一个匹配的子串后返回替换后的字符串
格式:re.sub(pattern,repl,string,count)
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r\'\\s+\', \'-\', text)) 执行结果如下: JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on... 其中第二个函数是替换后的字符串;本例中为\'-\' 第四个参数指替换个数。默认为0,表示每个匹配项都替换。
subn()
返回替换次数
格式:
subn(pattern,repl,string,count=0,flags=0)
print(re.subn(\'[1-2]\',\'A\',\'123456abcdef\')) print(re.sub("g.t","have",\'I get A, I got B ,I gut C\')) print(re.subn("g.t","have",\'I get A, I got B ,I gut C\')) 执行结果如下: (\'AA3456abcdef\', 2) I have A, I have B ,I have C (\'I have A, I have B ,I have C\', 3)
区别
1、re.match与re.search 与re.findall 的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配
a=re.search(\'[\\d]\',"abc33").group() print(a) p=re.match(\'[\\d]\',"abc33") print(p) b=re.findall(\'[\\d]\',"abc33") print(b)
执行结果: 3 None [\'3\', \'3\']
贪婪匹配与非贪婪匹配
*?,+?,??,{m,n}? 前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
a = re.findall(r"a(\\d+?)",\'a23b\') print(a) b = re.findall(r"a(\\d+)",\'a23b\') print(b) 执行结果: [\'2\'] [\'23\']
用flags时遇到的小坑
print(re.split(\'a\',\'1A1a2A3\',re.I))#输出结果并未能区分大小写
这是因为re.split(pattern,string,maxsplit,flags)默认是四个参数,当我们传入的三个参数的时候,系统会默认re.I是第三个参数,所以就没起作用。如果想让这里的re.I起作用,写成flags=re.I即可。
以上是关于Python正则表达式详解的主要内容,如果未能解决你的问题,请参考以下文章