实现一个比较低效但可以成功跑通的父子id表查询数据
Posted earlybridvic
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实现一个比较低效但可以成功跑通的父子id表查询数据相关的知识,希望对你有一定的参考价值。
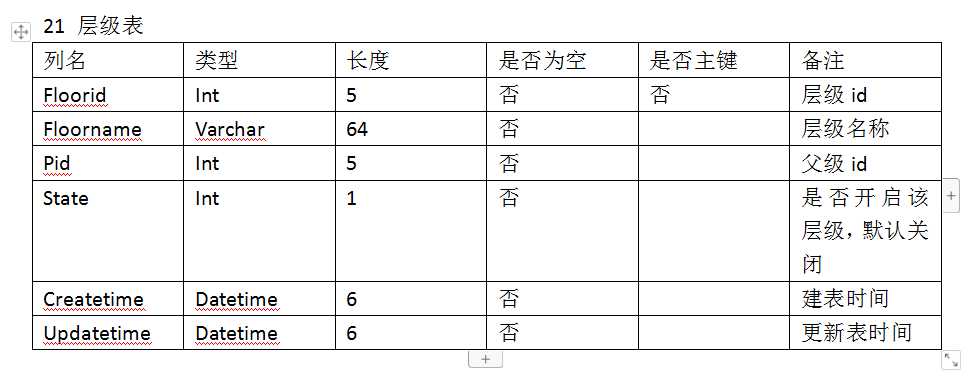
数据库定义是这样的。
后台查询代码段是这样的,比较复杂,主要是通过floorid,和 pid去循环查询,取得我们要的所有数据,并且按照一定的规则拼接成我们要的字符串。
返回给前端,进行展示处理,可能用递归树求解会好,或者是维护一个path列表,添加数据,其他的方法,暂时没有试过,今天第一次开发,先用最普通的方法试了一下,用到了三重循环,如果扩展一个层级,就要加一重循环,不过我们的项目,最多只有3层左右,所以最多是三重循环,虽然是如此,但是也是比较吃不开了。
public String getAllChapterQuestionbankTitle(@RequestParam(value = "subject", required = false) String subject) {
System.out.println("all floors --- begin!
");
System.out.println(subject);
String resultStr = "";
subjectMapper sub = subjectService.selectBySubjectName(subject);
System.out.println(sub.toString());
String subjectid = sub.getSubjectid();
System.out.println(subjectid);
//获取章节模块部分的代码
List<floorMapper> floors = floorService.selectBySubjectId(subjectid);
List<floorMapper> tempfloors = new ArrayList<floorMapper>();
System.out.println(floors);
System.out.println("all floors ---
");
//查找出出现过的父节点的章节,就是每一个章节的起头,添加到set集合中去
if (floors != null && floors.size() > 0) {
for (int i = 0; i < floors.size(); i++) {
System.out.println(floors.get(i).toString());
int pid = floors.get(i).getPid();
floorMapper floor = floorService.selectByPrimaryKey(pid);
if(floor.getFloorid()==floor.getPid())
tempfloors.add(floor);
}
}
List<floorMapper> resultfloors = new ArrayList<floorMapper>();
resultfloors = removeDuplicateFlight(tempfloors);
//获取了章
for (int index = 0; index < resultfloors.size(); index++) {
//这里请求到了每一个章的内容, 这里获取到章了,再一次获取到节部分
int pid = resultfloors.get(index).getFloorid();
//先拼接章名字
resultStr +=resultfloors.get(index).getFloorname()+"【章】";
List<floorMapper> joins = floorService.selectByParentId(pid);
joins = removeDuplicateFlight(joins);
if(joins!=null) {
//获取了节,先拼接节名字
for (int subindex = 0; subindex < joins.size(); subindex++) {
//这里获取到节了,再一次获取到模块部分
int pid2 = joins.get(subindex).getFloorid();
List<floorMapper> subjoins = floorService.selectByParentId(pid2);
//获取了部分
subjoins = removeDuplicateFlight(subjoins);
if(subjoins!=null) {
//获取了获取了部分,先拼接获取了部分名字
for (int k=0;k<subjoins.size();k++){
resultStr += subjoins.get(k).getFloorname()+"【部分】";
//没有下一层了!
}
}
resultStr += joins.get(subindex).getFloorname()+"【节】";
}
}
//从每一个章里,又获取每一个节的内容
/* resultStr += resultfloors.get(index).getFloorname() + ":" + resultfloors.get(index).getTitlenumber() +":"+ resultfloors.get(index).getState()+ "#";
*/
resultStr +="#";
}
resultStr = resultStr.substring(0, resultStr.length() - 1);
return resultStr;
}
接下来是对后端返回前端的数据进行解析,
返回的数据是
第一章 【章】 第一节【节】第一部分【部分】第二节【节】第三节【节】# 第二章【章】第一节【节】 这样的格式,
然后对其进行操作,
var len="";
$(document).ready(function () {
//刚进来请求一下章节数据,牵扯到floor表,questionbankid表,title表,option表,answer表,analyse表
//先调用一下floor层级表吧,floor关联到了subjectid,也关联到了questionbankid。
var subject = $("#subject").text();
alert(subject);
$.ajax({
type: ‘Post‘,
url: "/getAllChapterQuestionbankTitle",
timeout: 0,
async: false,
contentType: "application/x-www-form-urlencoded; charset=UTF-8",
data: {
subject: subject
},
success: function (result) {
//返回章节的字符串信息
var arrayList = new Array(1000);
arrayList = result.split("#");
//返回的是xxxxx【章】xxxxx【节】字符串数组
//拼接每一个章节信息到页面展示X
for (var index = 0; index < arrayList.length; index++) {
var htmlstr = "";
var zhangjie = arrayList[index].split("【章】");
htmlstr += "<li><div style="background-color:#ccc;font-color:white;" class="li">" + zhangjie[0] + "<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;" ><img th:src=‘@{/images/4.jpg}‘></span></div>";
htmlstr += " <div class="else">";
var lastjie = zhangjie[1].lastIndexOf("【节】");
var jiestr = zhangjie[1].substring(0, lastjie);//获取X节X节X节
var mokuaistr = zhangjie[1].substring(lastjie, zhangjie[1].length);//节之后的模块
var jiestrs = jiestr.split("【节】");
for (var i = 0; i < jiestrs.length; i++) {
//这里要判断节字符串是否含有【部分】,
len = 0; //一开始赋值为0
if (jiestrs[i].indexOf("【部分】") > 0) { //含有部分,将部分的子串提出
len = 1;//只要出现过部分一次,就赋值为1
var lastbufen = jiestrs[i].lastIndexOf("【部分】");
var jiesubstr = jiestrs[i].substring(lastbufen, jiestrs[i].length);
var bufen = jiestrs[i].substring(0, lastbufen); //获取前面的【部分】子串
jiestrs[i] = jiesubstr.substring(4, jiesubstr.length); //重新给节字符串赋值
}
if(bufen!="") {
if (bufen.indexOf("【部分】") > 0) {
//多余一个部分,分割一下
var bufenstrs = bufen.split("【部分】");
len = bufenstrs.length; //根据具体有多少个部分,设置长度
}
}
if (i == 0) { //第一个
htmlstr += "<div class="else-list first" style=‘height:"+(len+1)*35+"px;‘>" + jiestrs[i]+"<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;" ><img th:src=‘@{/images/4.jpg}‘></span>";
//添加下一个层级部分
if(bufen!=""){
if (bufen.indexOf("【部分】") > 0){
//多余一个部分,分割一下
var bufenstrs = bufen.split("【部分】");
for(var per = 0 ;per<bufenstrs.length;per++){
if(per == 0) {
htmlstr += "<div class="bufen first">" + bufenstrs[per] + "<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;" ><img th:src=‘@{/images/4.jpg}‘></span></div>";
}else{
htmlstr += "<div class="bufen">" + bufenstrs[per] + "<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;" ><img th:src=‘@{/images/4.jpg}‘></span></div>";
}
}
}else{
htmlstr += "<div class="bufen first">" + bufen + "<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;" ><img th:src=‘@{/images/4.jpg}‘></span></div>";
}
}
bufen = "";
htmlstr += "</div>";
} else {
htmlstr += "<div class="else-list first" style=‘height:"+(len+1)*35+"px;‘>" + jiestrs[i]+"<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;" ><img th:src=‘@{/images/4.jpg}‘></span>";
//添加下一个层级部分
if(bufen!=""){
if (bufen.indexOf("【部分】") > 0){
//多余一个部分,分割一下
var bufenstrs = bufen.split("【部分】");
for(var per = 0 ;per<bufenstrs.length;per++){
if(per == 0) {
htmlstr += "<div class="bufen first">" + bufenstrs[per] + "<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;"><img th:src=‘@{/images/4.jpg}‘></span></div>";
}else{
htmlstr += "<div class="bufen">" + bufenstrs[per] + "<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;"><img th:src=‘@{/images/4.jpg}‘></span></div>";
}
}
}else{
htmlstr += "<div class="bufen first">" + bufen + "<span style="background-color:white;z-index:99999;float:right;width:25px;height:25px;border:2px solid black;"><img th:src=‘@{/images/4.jpg}‘></span></div>";
}
}
bufen = "";
htmlstr += "</div>";
}
}
htmlstr += " </div ></id>";
$(".list").append(htmlstr);
}
},
error: function (error) {
}
});
});
解析的整个过程其实很复杂,需要很大耐心完成,同时这样写代码如果不是第一次写,还算是新手,肯定不会以这种方式完成的,目前项目的需求是可以简单的满足,估计过一段时间,得重构了,记录下这次的繁琐的代码记录,算是一个实践的过程吧。
以上是关于实现一个比较低效但可以成功跑通的父子id表查询数据的主要内容,如果未能解决你的问题,请参考以下文章