一起学源码-微服务Nexflix Eureka 源码十:服务下线及实例摘除,一个client下线到底多久才会被其他实例感知?
Posted wang-meng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一起学源码-微服务Nexflix Eureka 源码十:服务下线及实例摘除,一个client下线到底多久才会被其他实例感知?相关的知识,希望对你有一定的参考价值。
前言
前情回顾
上一讲我们讲了 client端向server端发送心跳检查,也是默认每30钟发送一次,server端接收后会更新注册表的一个时间戳属性,然后一次心跳(续约)也就完成了。
本讲目录
这一篇有两个知识点及一个疑问,这个疑问是在工作中真真实实遇到过的。
例如我有服务A、服务B,A、B都注册在同一个注册中心,当B下线后,A多久能感知到B已经下线了呢?
不知道大家有没有这个困惑,这篇文章最后会对此问题答疑,如果能够看到文章的结尾,或许你就知道答案了,当然答案也会在结尾揭晓。

目录如下:
- Client端服务实例下线通知Server端
- Server端定时任务 服务摘除
技术亮点:定时任务错误触发时间补偿机制
在Server端定时任务进行服务故障自动感知摘除的时候有一个设计很巧妙的点,时间补偿机制。
我们知道,在做定时任务的时候,基于某个固定点触发的操作都可能由于一些其他原因导致固定的点没有执行对应的操作,这时再次执行定时操作后,计算的每次任务相隔时间就会出现问题。而Eureka 这里采用了一种补偿机制,再计算时间差值的时候完美解决此问题。
说明
原创不易,如若转载 请标明来源:一枝花算不算浪漫
源码分析
Client端服务实例下线通知Server端
Client下线 我们还是依照之前的原则,从DiscoveryClient 看起,可以看到有一个shutdown() 方法,然后接着跟一下这个方法:
@PUT
public Response renewLease(
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication,
@QueryParam("overriddenstatus") String overriddenStatus,
@QueryParam("status") String status,
@QueryParam("lastDirtyTimestamp") String lastDirtyTimestamp) {
boolean isFromReplicaNode = "true".equals(isReplication);
boolean isSuccess = registry.renew(app.getName(), id, isFromReplicaNode);
// 省略部分代码
logger.debug("Found (Renew): {} - {}; reply status={}" + app.getName(), id, response.getStatus());
return response;
}
public boolean renew(String appName, String id, boolean isReplication) {
RENEW.increment(isReplication);
Map<String, Lease<InstanceInfo>> gMap = registry.get(appName);
Lease<InstanceInfo> leaseToRenew = null;
if (gMap != null) {
leaseToRenew = gMap.get(id);
}
if (leaseToRenew == null) {
RENEW_NOT_FOUND.increment(isReplication);
logger.warn("DS: Registry: lease doesn't exist, registering resource: {} - {}", appName, id);
return false;
} else {
InstanceInfo instanceInfo = leaseToRenew.getHolder();
if (instanceInfo != null) {
// touchASGCache(instanceInfo.getASGName());
InstanceStatus overriddenInstanceStatus = this.getOverriddenInstanceStatus(
instanceInfo, leaseToRenew, isReplication);
if (overriddenInstanceStatus == InstanceStatus.UNKNOWN) {
logger.info("Instance status UNKNOWN possibly due to deleted override for instance {}"
+ "; re-register required", instanceInfo.getId());
RENEW_NOT_FOUND.increment(isReplication);
return false;
}
if (!instanceInfo.getStatus().equals(overriddenInstanceStatus)) {
Object[] args = {
instanceInfo.getStatus().name(),
instanceInfo.getOverriddenStatus().name(),
instanceInfo.getId()
};
logger.info(
"The instance status {} is different from overridden instance status {} for instance {}. "
+ "Hence setting the status to overridden status", args);
instanceInfo.setStatusWithoutDirty(overriddenInstanceStatus);
}
}
renewsLastMin.increment();
leaseToRenew.renew();
return true;
}
}代码也很简单,做一些资源释放,取消调度任等操作,这里主要还是关注的是通知Server端的逻辑,及Server端是如何做实例下线的。这里请求Server端请求主要看下unregister方法,这里是调用jersey中的cancel 方法,调用Server端ApplicationsResource中的@DELETE 请求。(看到这里,前面看到各种client端调用server端,都是通过请求方式来做restful风格调用的,这里不仅要感叹 妙啊)
我们到Server端看下接收请求的入口代码:
InstanceResource.cancelLease() :
@DELETE
public Response cancelLease(
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {
boolean isSuccess = registry.cancel(app.getName(), id,
"true".equals(isReplication));
if (isSuccess) {
logger.debug("Found (Cancel): " + app.getName() + " - " + id);
return Response.ok().build();
} else {
logger.info("Not Found (Cancel): " + app.getName() + " - " + id);
return Response.status(Status.NOT_FOUND).build();
}
}然后接着往下跟,AbstractInstanceRegistry.internalCancel 方法:
protected boolean internalCancel(String appName, String id, boolean isReplication) {
try {
read.lock();
CANCEL.increment(isReplication);
// 通过appName获取注册表信息
Map<String, Lease<InstanceInfo>> gMap = registry.get(appName);
Lease<InstanceInfo> leaseToCancel = null;
if (gMap != null) {
// 通过实例id将注册信息从注册表中移除
leaseToCancel = gMap.remove(id);
}
// 最近取消的注册表信息队列添加该注册表信息
synchronized (recentCanceledQueue) {
recentCanceledQueue.add(new Pair<Long, String>(System.currentTimeMillis(), appName + "(" + id + ")"));
}
InstanceStatus instanceStatus = overriddenInstanceStatusMap.remove(id);
if (instanceStatus != null) {
logger.debug("Removed instance id {} from the overridden map which has value {}", id, instanceStatus.name());
}
if (leaseToCancel == null) {
CANCEL_NOT_FOUND.increment(isReplication);
logger.warn("DS: Registry: cancel failed because Lease is not registered for: {}/{}", appName, id);
return false;
} else {
// 执行下线操作的cancel方法
leaseToCancel.cancel();
InstanceInfo instanceInfo = leaseToCancel.getHolder();
String vip = null;
String svip = null;
if (instanceInfo != null) {
instanceInfo.setActionType(ActionType.DELETED);
// 最近更新的队列中加入此服务实例信息
recentlyChangedQueue.add(new RecentlyChangedItem(leaseToCancel));
instanceInfo.setLastUpdatedTimestamp();
vip = instanceInfo.getVIPAddress();
svip = instanceInfo.getSecureVipAddress();
}
// 使注册表的读写缓存失效
invalidateCache(appName, vip, svip);
logger.info("Cancelled instance {}/{} (replication={})", appName, id, isReplication);
return true;
}
} finally {
read.unlock();
}
}接着看 Lease.cancel :
public void cancel() {
// 这里只是更新服务实例中下线的时间戳
if (evictionTimestamp <= 0) {
evictionTimestamp = System.currentTimeMillis();
}
}这里已经加了注释,再总结下:
1、加上读锁,支持多服务实例下线
2、通过appName获取注册表信息map
3、通过appId移除对应注册表信息
4、recentCanceledQueue添加该服务实例
5、更新Lease中的服务实例下线时间
6、recentlyChangedQueue添加该服务实例
7、invalidateCache() 使注册表的读写缓存失效
这里针对于6、7再解释一下,我们在第八讲:【一起学源码-微服务】Nexflix Eureka 源码八:EurekaClient服务发现之注册表抓取 精妙设计分析! 中讲过,当client端第一次进行增量注册表抓取的时候,是会从recentlyChangedQueue中获取数据的,然后放入到读写缓存,然后再同步到只读缓存,下次再获取的时候直接从只读缓存获取即可。
这里会存在一个问题,如果一个服务下线了,读写缓存更新了,但是只读缓存并未更新,30s后由定时任务刷新 读写缓存的数据到了只读缓存,这时其他客户端才会感知到该下线的服务实例。
配合文字说明这里加一个EurekaClient下线流程图,红色线是下线逻辑,黑色线是抓取注册表 感知服务下线逻辑:
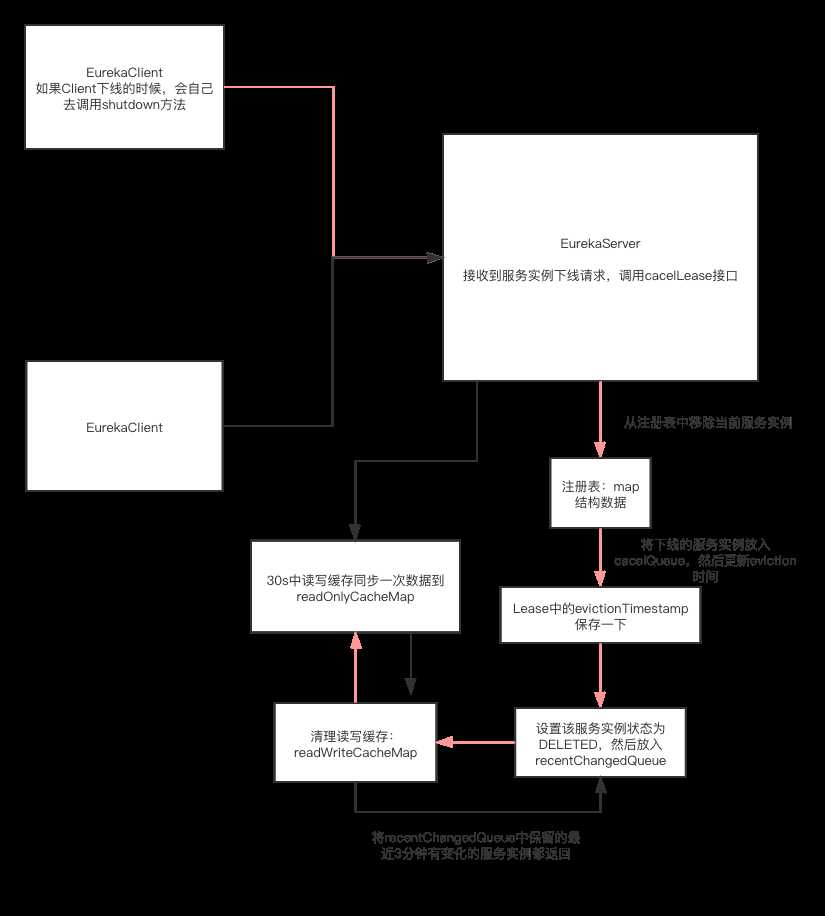
记住一点,这里是正常的服务下线,走shutdown逻辑,如果一个服务突然自己宕机了,那么注册中心怎么去自动感知这个服务下线呢?紧接着往下看吧。
Server端定时任务 服务摘除
举例一个场景,上面也说过,一个Client服务端自己挂掉了,并没有正常的去执行shutdown方法,那么注册中心该如何感知这个服务实例下线了并从注册表摘除这个实例呢?
我们知道,eureka靠心跳机制来感知服务实例是否还存活着,如果某个服务挂掉了是不会再发送心跳过来了,如果在一段时间内没有接收到某个服务的心跳,那么就将这个服务实例给摘除掉,认为这个服务实例以及宕机了。
这里自动检测服务实例是否宕机的入口在:EurekaBootStrap,eureka server在启动初始化的时候,有个方法registry.openForTraffic(applicationInfoManager, registryCount) 里面会有一个服务实例检测的调度任务(这个入口真的很隐蔽,网上查了别人的分析才找到),接着直接看代码吧。
EurekaBootStrap.initEurekaServerContext() :
protected void initEurekaServerContext() throws Exception {
// 省略部分代码...
int registryCount = registry.syncUp();
registry.openForTraffic(applicationInfoManager, registryCount);
}这里的代码前面看过很多次,syncUp是获取其他EurekaServer中注册表数据,然后拿到注册表中服务实例registryCount,然后和自己本地注册表服务实例数量进行对比等等。
接着是openForTraffic方法,这里会计算预期的1分钟所有服务实例心跳次数expectedNumberOfRenewsPerMin
(插个眼,后面eureka server自我保护机制会用到这个属性)后面会详细讲解,而且这里设置还是有bug的。
在方法的最后会有一个:super.postInit(); 到了这里才是真正的服务实例自动感知的调度任务逻辑。兜兜转转 在这个不起眼的地方 隐藏了这么重要的逻辑。
PeerAwareInstanceRegistryImpl.java :
public int syncUp() {
// Copy entire entry from neighboring DS node
int count = 0;
for (int i = 0; ((i < serverConfig.getRegistrySyncRetries()) && (count == 0)); i++) {
if (i > 0) {
try {
Thread.sleep(serverConfig.getRegistrySyncRetryWaitMs());
} catch (InterruptedException e) {
logger.warn("Interrupted during registry transfer..");
break;
}
}
Applications apps = eurekaClient.getApplications();
for (Application app : apps.getRegisteredApplications()) {
for (InstanceInfo instance : app.getInstances()) {
try {
// isRegisterable:是否可以在当前服务实例所在的注册中心注册。这个方法一定返回true,那么count就是相邻注册中心所有服务实例数量
if (isRegisterable(instance)) {
register(instance, instance.getLeaseInfo().getDurationInSecs(), true);
count++;
}
} catch (Throwable t) {
logger.error("During DS init copy", t);
}
}
}
}
return count;
}
@Override
public void openForTraffic(ApplicationInfoManager applicationInfoManager, int count) {
// Renewals happen every 30 seconds and for a minute it should be a factor of 2.
// 如果有20个服务实例,乘以2 代表需要40次心跳
// 这里有bug,count * 2 是硬编码,作者是不是按照心跳时间30秒计算的?所以计算一分钟得心跳就是 * 2,但是心跳时间是可以自己配置修改的
// 看了master源码,这一块已经改为:
/**
* this.expectedNumberOfClientsSendingRenews = this.expectedNumberOfClientsSendingRenews + 1;
* updateRenewsPerMinThreshold();
*
* 主要是看 updateRenewsPerMinThreshold 方法:
* this.numberOfRenewsPerMinThreshold = (int) (this.expectedNumberOfClientsSendingRenews * (60.0 / serverConfig.getExpectedClientRenewalIntervalSeconds() * serverConfig.getRenewalPercentThreshold());
* 这里完全是读取用户自己配置的心跳检查时间,然后用60s / 配置时间
*/
this.expectedNumberOfRenewsPerMin = count * 2;
// numberOfRenewsPerMinThreshold = count * 2 * 0.85 = 34 期望一分钟 20个服务实例,得有34个心跳
this.numberOfRenewsPerMinThreshold =
(int) (this.expectedNumberOfRenewsPerMin * serverConfig.getRenewalPercentThreshold());
logger.info("Got " + count + " instances from neighboring DS node");
logger.info("Renew threshold is: " + numberOfRenewsPerMinThreshold);
this.startupTime = System.currentTimeMillis();
if (count > 0) {
this.peerInstancesTransferEmptyOnStartup = false;
}
DataCenterInfo.Name selfName = applicationInfoManager.getInfo().getDataCenterInfo().getName();
boolean isAws = Name.Amazon == selfName;
if (isAws && serverConfig.shouldPrimeAwsReplicaConnections()) {
logger.info("Priming AWS connections for all replicas..");
primeAwsReplicas(applicationInfoManager);
}
logger.info("Changing status to UP");
applicationInfoManager.setInstanceStatus(InstanceStatus.UP);
// 此方法会做服务实例的自动摘除任务
super.postInit();
}关于
syncUp方法,这里知道它是获取其他服务注册表信息,然后获取注册实例数量就行了,后面还会有更详细的讲解。接着
openForTraffic方法,第一行代码:this.expectedNumberOfRenewsPerMin = count * 2;这个count是相邻注册表中所有服务实例数量,至于乘以2 是什么意思呢? 首先是这个字段的含义是:期待的一分钟所有服务实例心跳次数,因为服务续约renew 默认是30s执行一次,所以这里就想当然一分钟就乘以2了。大家看出来了吧?这是个很明显的bug。因为续约时间是可配置的,如果手动配置成10s,那么这里乘以6才对。看了下公司代码 spring-cloud版本是
Finchley.RELEASE, 其中以来的netflix eureka 是1.9.2仍然存在这个问题。我也翻看了master分支的代码,此bug已经修复了,修改如下:
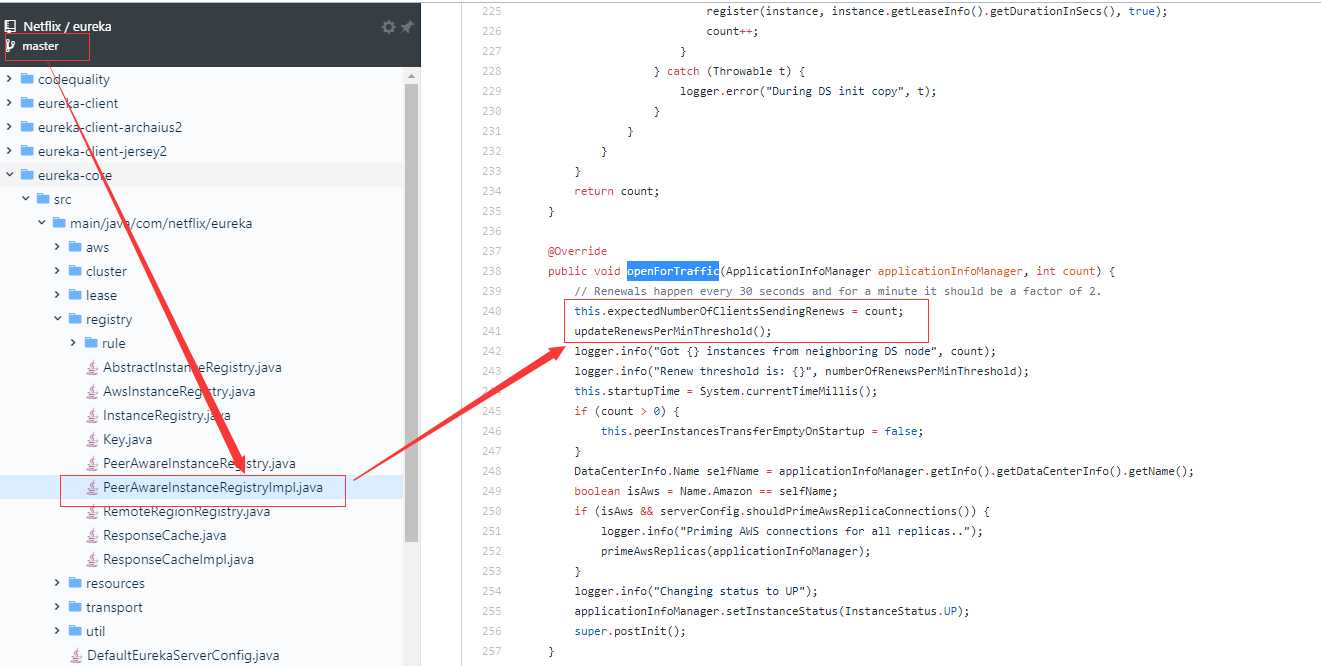
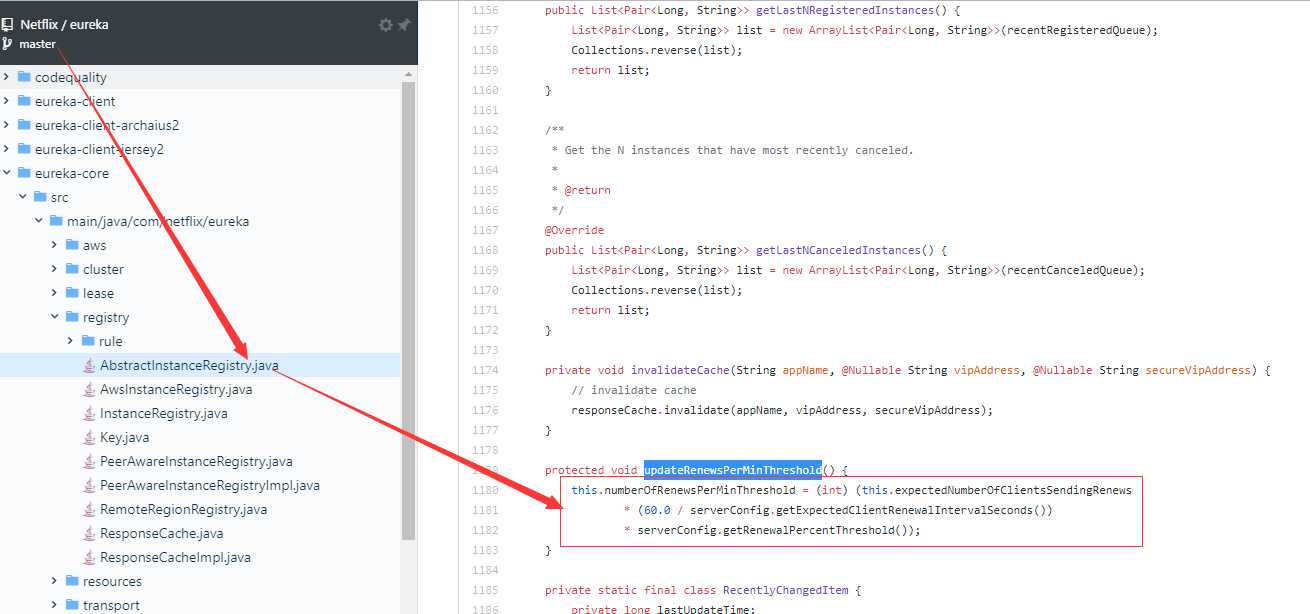
其实这一块还有很多bug,包括服务注册、下线 用的都是+2 -2操作,后面一篇文章会有更多讲解。
继续看服务实例自动感知的调度任务:
AbstractInstanceRegistry.java :
protected void postInit() {
renewsLastMin.start();
if (evictionTaskRef.get() != null) {
evictionTaskRef.get().cancel();
}
evictionTaskRef.set(new EvictionTask());
evictionTimer.schedule(evictionTaskRef.get(),
serverConfig.getEvictionIntervalTimerInMs(),
serverConfig.getEvictionIntervalTimerInMs());
}
class EvictionTask extends TimerTask {
private final AtomicLong lastExecutionNanosRef = new AtomicLong(0l);
@Override
public void run() {
try {
// 获取补偿时间 可能大于0
long compensationTimeMs = getCompensationTimeMs();
logger.info("Running the evict task with compensationTime {}ms", compensationTimeMs);
evict(compensationTimeMs);
} catch (Throwable e) {
logger.error("Could not run the evict task", e);
}
}
/**
* compute a compensation time defined as the actual time this task was executed since the prev iteration,
* vs the configured amount of time for execution. This is useful for cases where changes in time (due to
* clock skew or gc for example) causes the actual eviction task to execute later than the desired time
* according to the configured cycle.
*/
long getCompensationTimeMs() {
// 第一次进来先获取当前时间 currNanos=20:00:00
// 第二次过来,此时currNanos=20:01:00
// 第三次过来,currNanos=20:03:00才过来,本该60s调度一次的,由于fullGC或者其他原因,到了这个时间点没执行
long currNanos = getCurrentTimeNano();
// 获取上一次这个EvictionTask执行的时间 getAndSet :以原子方式设置为给定值,并返回以前的值
// 第一次 将20:00:00 设置到lastNanos,然后return 0
// 第二次过来后,拿到的lastNanos为20:00:00
// 第三次过来,拿到的lastNanos为20:01:00
long lastNanos = lastExecutionNanosRef.getAndSet(currNanos);
if (lastNanos == 0l) {
return 0l;
}
// 第二次进来,计算elapsedMs = 60s
// 第三次进来,计算elapsedMs = 120s
long elapsedMs = TimeUnit.NANOSECONDS.toMillis(currNanos - lastNanos);
// 第二次进来,配置的服务驱逐间隔默认时间为60s,计算的补偿时间compensationTime=0
// 第三次进来,配置的服务驱逐间隔默认时间为60s,计算的补偿时间compensationTime=60s
long compensationTime = elapsedMs - serverConfig.getEvictionIntervalTimerInMs();
return compensationTime <= 0l ? 0l : compensationTime;
}
long getCurrentTimeNano() { // for testing
return System.nanoTime();
}
}这里执行
postInit方法,然后执行EvictionTask任务,执行时间是serverConfig.getEvictionIntervalTimerInMs()默认是60s执行一次。接着调用
EvictionTask,这里也加了一些注释,我们再来分析一下。
2.1 首先是获取补偿时间,compenstationTimeMs,这个时间很关键
2.2 调用evict方法,摘除过期没有发送心跳的实例
查看getCompensationTimeMs 方法,这里我添加了很详细的注释,这个方法主要是 为了防止 定时任务触发点,服务因为某些原因没有执行该调度任务,此时elapsedMs 会超过60s的,最后返回的compensationTime 就是实际延误且需要补偿的时间。
接着再看下evict 逻辑:
public void evict(long additionalLeaseMs) {
// 是否允许主动删除宕机节点数据,这里判断是否进入自我保护机制,如果是自我保护了则不允许摘除服务
if (!isLeaseExpirationEnabled()) {
logger.debug("DS: lease expiration is currently disabled.");
return;
}
List<Lease<InstanceInfo>> expiredLeases = new ArrayList<>();
for (Entry<String, Map<String, Lease<InstanceInfo>>> groupEntry : registry.entrySet()) {
Map<String, Lease<InstanceInfo>> leaseMap = groupEntry.getValue();
if (leaseMap != null) {
for (Entry<String, Lease<InstanceInfo>> leaseEntry : leaseMap.entrySet()) {
Lease<InstanceInfo> lease = leaseEntry.getValue();
if (lease.isExpired(additionalLeaseMs) && lease.getHolder() != null) {
expiredLeases.add(lease);
}
}
}
}
int registrySize = (int) getLocalRegistrySize();
int registrySizeThreshold = (int) (registrySize * serverConfig.getRenewalPercentThreshold());
int evictionLimit = registrySize - registrySizeThreshold;
int toEvict = Math.min(expiredLeases.size(), evictionLimit);
if (toEvict > 0) {
logger.info("Evicting {} items (expired={}, evictionLimit={})", toEvict, expiredLeases.size(), evictionLimit);
Random random = new Random(System.currentTimeMillis());
for (int i = 0; i < toEvict; i++) {
// Pick a random item (Knuth shuffle algorithm)
int next = i + random.nextInt(expiredLeases.size() - i);
Collections.swap(expiredLeases, i, next);
Lease<InstanceInfo> lease = expiredLeases.get(i);
String appName = lease.getHolder().getAppName();
String id = lease.getHolder().getId();
EXPIRED.increment();
logger.warn("DS: Registry: expired lease for {}/{}", appName, id);
internalCancel(appName, id, false);
}
}
}public boolean isLeaseExpirationEnabled() {
if (!isSelfPreservationModeEnabled()) {
// The self preservation mode is disabled, hence allowing the instances to expire.
return true;
}
// 这行代码触发自我保护机制,期望的一分钟要有多少次心跳发送过来,所有服务实例一分钟得发送多少次心跳
// getNumOfRenewsInLastMin 上一分钟所有服务实例一共发送过来多少心跳,10次
// 如果上一分钟 的心跳次数太少了(20次)< 我期望的100次,此时会返回false
return numberOfRenewsPerMinThreshold > 0 && getNumOfRenewsInLastMin() > numberOfRenewsPerMinThreshold;
}- 首先看
isLeaseExpirationEnabled方法,这个方法是判断是否需要自我保护的,里面逻辑其实也很简单,获取山一分钟所有实例心跳的次数和numberOfRenewsPerMinThreshold(期望的每分钟所有实例心跳次数x85%) 进行对比,如果大于numberOfRenewsPerMinThreshold才允许摘除实例,否则进入自我保护模式。下一节会详细讲解这个方法。 - 如果服务实例可以被移除,接着往下看,这里是遍历所有的服务注册信息,然后一个个遍历服务实例心跳时间是否超过了对应的时间,主要看
lease.isExpired(additionalLeaseMs)方法:
Lease.isExpired() :
/**
* Checks if the lease of a given {@link com.netflix.appinfo.InstanceInfo} has expired or not.
*
* Note that due to renew() doing the 'wrong" thing and setting lastUpdateTimestamp to +duration more than
* what it should be, the expiry will actually be 2 * duration. This is a minor bug and should only affect
* instances that ungracefully shutdown. Due to possible wide ranging impact to existing usage, this will
* not be fixed.
*
* @param additionalLeaseMs any additional lease time to add to the lease evaluation in ms.
*/
public boolean isExpired(long additionalLeaseMs) {
// lastUpdateTimestamp renew成功后就会刷新这个时间,可以理解为最近一次活跃时间
// 查看 Lease.renew方法:lastUpdateTimestamp = System.currentTimeMillis() + duration;
// duration可以查看为:LeaseInfo中的DEFAULT_LEASE_RENEWAL_INTERVAL=90s 默认为90s
// 这段逻辑为 当前时间 > 上一次心跳时间 + 90s + 补偿时间
/**
* 这里先不看补偿时间,假设补偿时间为0,这段的含义是 如果当前时间大于上次续约的时间+90s,那么就认为该实例过期了
* 因为lastUpdateTimestamp=System.currentTimeMillis()+duration,所以这里可以理解为 超过180是还没有续约,那么就认为该服务实例过期了
*
* additionalLeaseMs 时间是一个容错的机制,也是服务保持最终一致性的一种手段,针对于定时任务 因为一些不可控原因在某些时间点没有定时执行,那么这个就是很好的容错机制
* 这段代码 意思现在理解为:服务如果宕机了,那么最少180s 才会被注册中心摘除掉
*/
return (evictionTimestamp > 0 || System.currentTimeMillis() > (lastUpdateTimestamp + duration + additionalLeaseMs));
}这里注释已经写得很清楚了,System.currentTimeMillis() > lastUpdateTimestamp + duration + additionalLeaseMs 如果将补偿时间记为0,那么这段代码的含义是 如果服务如果宕机了,那么最少180s 才会被注册中心摘除掉
上面这段代码翻译完了,接着看一个彩蛋
看这段代码注释,我先谷歌翻译给大家看下:

翻译的不是很好,我再来说下,这里说的是在renew() 方法中,我们写了一个bug,那里不应该多加一个duration(默认90s)时间的,加上了会导致这里duration * 2了,所以也就是至少180s才会被摘除。但是又由于修改会产生其他的问题,所以我们不予修改。
顺便看下renew() 做了什么错事:
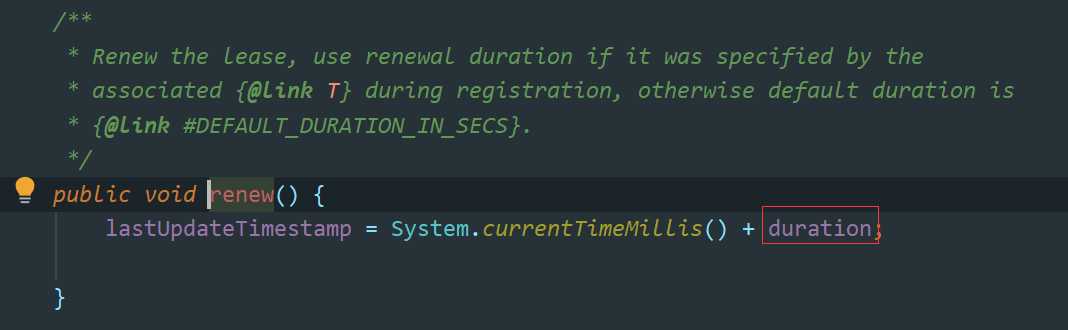
这里确实多给加了一个duration,哈哈 通过这个注释 可以感受到作者就像一个娇羞的小媳妇一样,我做错了事 我就不改 哼!~

言归正传,这里接着看evict()后面的操作:
- 将所有需要摘除的服务实例放到
expiredLeases集合中去 - 计算服务摘除的阈值,
registrySizeThreshold为注册实例总数量 * 85% - 计算最多可摘除的服务实例个数:总数量 - 总数量 * 85%
这里实则也是一种保护机制,即使我很多服务宕机了,但是最多只能摘除15%的服务实例。 - 随机摘取指定的服务实例数量,然后遍历调用
internalCancel方法来remove宕机的服务实例, 这里就是上面讲解的服务下线调用的方法
总结
分析完了上面所有的代码 是不是有一种大跌眼镜的感觉?我们现在查看的版本确实还存在bug的,有一些bug在master中已经被修复,但仍有些存在。后面一讲会重点跟进这些问题。
接下来就回答开头抛出来的一个问题了:
例如我有服务A、服务B,A、B都注册在同一个注册中心,当B下线后,A多久能感知到B已经下线了呢?
答案是:最快180s才会被感知。如果有补偿时间,或者服务摘除的时候 计算随机摘除服务的时候 没有摘除此服务,那么又会等待180s 来摘除。所以这个只能说一个最块180被感知到。
这一讲还是写了很多,其实这里面包含了很多下一讲的内容,下一讲会对本讲做一个补充。敬请期待。
申明
本文章首发自本人博客:https://www.cnblogs.com/wang-meng 和公众号:壹枝花算不算浪漫,如若转载请标明来源!
感兴趣的小伙伴可关注个人公众号:壹枝花算不算浪漫

以上是关于一起学源码-微服务Nexflix Eureka 源码十:服务下线及实例摘除,一个client下线到底多久才会被其他实例感知?的主要内容,如果未能解决你的问题,请参考以下文章