SPSS数据分析—加权最小二乘法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SPSS数据分析—加权最小二乘法相关的知识,希望对你有一定的参考价值。
标准的线性回归模型的假设之一是因变量方差齐性,即因变量或残差的方差不随自身预测值或其他自变量的值变化而变化。但是有时候,这种情况会被违反,称为异方差性,比如因变量为储蓄额,自变量为家庭收入,显然高收入家庭由于有更多的可支配收入,因此储蓄额差异较大,而低收入家庭由于没有过多的选择余地,因此储蓄会比较有计划和规律。
异方差性如果还是使用普通最小二乘法进行估计,那么会造成以下问题
1.估计量仍然具有无偏性,但是不具备有效性
2.变量的显著性检验失去意义
3.由于估计量变异程度增大,导致模型预测误差增大,精度降低
如何辨别是否存在异方差性呢?
1.根据专业经验判断,如上例中的储蓄额和家庭收入
2.做自变量和残差的散点图,看是否具有某种趋势
3.使用假设检验,例如Park-Gleiser检验、Goldfeld-Quandt检验、怀特检验等。
异方差的修正可以使用加权最小二乘法,基本思路是根据变异大小对相应的数据赋予不同的权重,对变异较小的赋予较大的权重,对变异较大的赋予较小的权重,使模型趋于平衡。
在SPSS中,加权最小二乘法有两个过程可以操作,一个是在线性回归中直接加入WLS权重,该功能主要是针对权重已知的情况下,如果权重未知,则需要在专门的“权重估计”过程中操作。下面我们分别来看这两个过程
1.分析—回归—线性
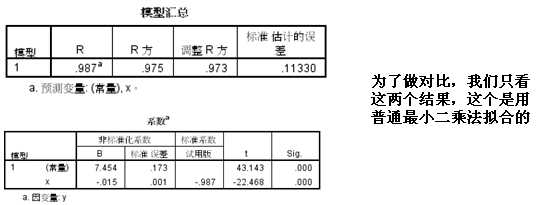
该数据是建立X对Y的回归,如果只有两个变量,则可以直接使用简单线性回归,但是数据中还有一个样本数n,如果直接使用简单线性回归,默认的最小二乘估计法则认为样本数并不影响结果,这显然不太合理,样本量大的变异和样本量小的变异肯定不一样,因此需要使用加权最小二乘法,将样本数作为权重,为了对比结果,我们分别使用两种方法进行拟合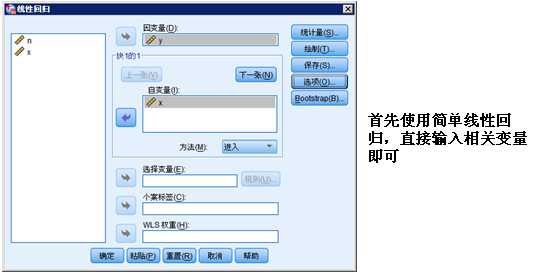
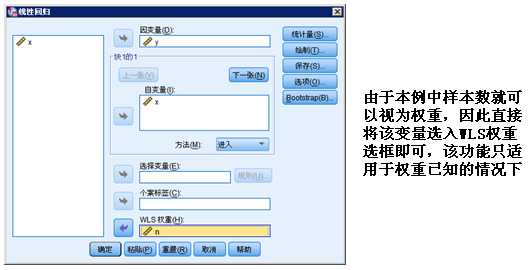
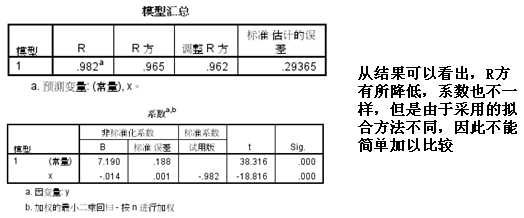
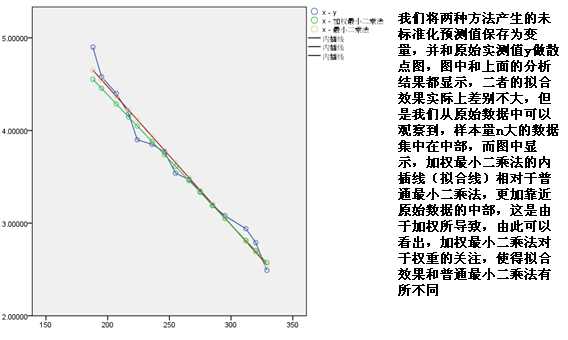
2.分析—回归—权重估计
上面的例子中,我们已经知道了样本量大小代表权重大小,说明权重已经已知了,但是有时候权重大小并不十分明确,需要在拟合时逐步确定,因此我们采用WLS法的另一个过程,该过程首先要确定权重变量,权重变量也是待分析变量中其中一个,需要从专业角度加以认定,在本例中,我们仍以n作为权重变量。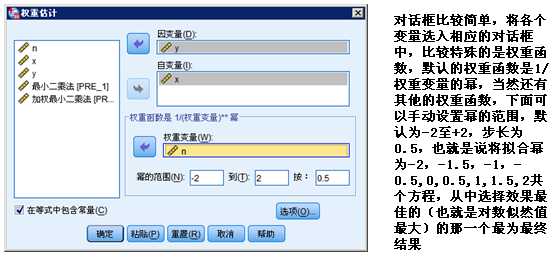
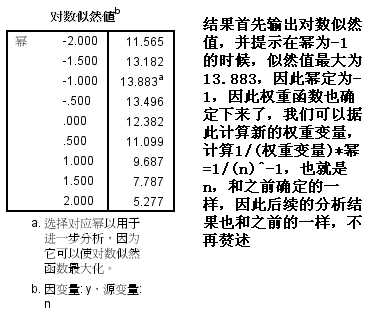
以上是关于SPSS数据分析—加权最小二乘法的主要内容,如果未能解决你的问题,请参考以下文章